






Kafka和storm集群环境安装
这两者的依赖如下:
Storm集群:JDK1.8 , Zookeeper3.4,Storm1.1.1;
Kafa集群 : JDK1.8 ,Zookeeper3.4 ,Kafka2.12;
- 文件准备
- 环境配置
- 修改配置文件
- 启动
Storm
分布式实时大数据处理框架
Storm的核心组件:
Nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个Worker进程。
Worker:工作进程,每个工作进程中都有多个Task。
Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。
Topology:计算拓扑,Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。
Stream:数据流(Streams)是 Storm 中最核心的抽象概念。一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。
Spout:数据源(Spout)是拓扑中数据流的来源。一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中。根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。一个可靠的 Spout能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;相对应的,不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理。一个 Spout可以发送多个数据流。
Bolt:拓扑中所有的数据处理均是由 Bolt 完成的。通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求。一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
Stream grouping:为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
Reliability:可靠性。Storm 可以通过拓扑来确保每个发送的元组都能得到正确处理。通过跟踪由 Spout 发出的每个元组构成的元组树可以确定元组是否已经完成处理。每个拓扑都有一个“消息延时”参数,如果 Storm 在延时时间内没有检测到元组是否处理完成,就会将该元组标记为处理失败,并会在稍后重新发送该元组。
Topology是使用Spout获取数据,Bolt来进行计算。
三种模式,解释如下:
第一种比较简单,就是由一个Spout获取数据,然后交给一个Bolt进行处理;
第二种稍微复杂点,由一个Spout获取数据,然后交给一个Bolt进行处理一部分,然后在交给下一个Bolt进行处理其他部分。
第三种则比较复杂,一个Spout可以同时发送数据到多个Bolt,而一个Bolt也可以接受多个Spout或多个Bolt,最终形成多个数据流。但是这种数据流必须是有方向的,有起点和终点,不然会造成死循环,数据永远也处理不完。就是Spout发给Bolt1,Bolt1发给Bolt2,Bolt2又发给了Bolt1,最终形成了一个环状。
具体步骤如下:
- 启动topology,设置好Spout和Bolt。
- 将Spout获取的数据传递给Bolt。
- Bolt接受Spout的数据进行打印。
Kafak
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
kafka的术语:
Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker。
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition。
Producer:负责发布消息到Kafka broker。
Consumer:消息消费者,向Kafka broker读取消息的客户端。
Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
整合
1.提供一个将用户数据写入kafka的接口;
2.使用storm的spout获取kafka的数据并发送给bolt;
2.在bolt移除年龄小于10岁的用户的数据,并写入mysql;
准备:
添加相关依赖
添加配置
数据库脚本
首先是数据源的获取,也就是使用storm中的spout从kafka中拉取数据。
其中spout是storm获取数据的一个组件,其中我们主要实现nextTuple方法,编写从kafka中获取数据的代码就可以在storm启动后进行数据的获取。
上述spout类中主要是将从kafka获取的数据传输传输到bolt中,然后再由bolt类处理该数据,处理成功之后,写入数据库,然后给与sqout响应,避免重发。
bolt类主要处理业务逻辑的方法是execute,我们主要实现的方法也是写在这里。需要注意的是这里只用了一个bolt,因此也不用定义Field进行再次的转发。
编写完了spout和bolt之后,我们再来编写storm的主类。
storm的主类主要是对Topology(拓步)进行提交,提交Topology的时候,需要对spout和bolt进行相应的设置。Topology的运行的模式有两种:
- 一种是本地模式,利用本地storm的jar模拟环境进行运行。
1
2 LocalCluster cluster = new LocalCluster();
cluster.submitTopology(“TopologyApp”, conf,builder.createTopology()); - 另一种是远程模式,也就是在storm集群进行运行。
1 StormSubmitter.submitTopology(args[0], conf, builder.createTopology());



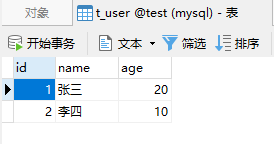
程序
目录结构:

KafkaProducerTest:
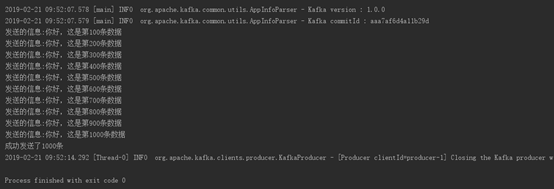
KafkConsumerTest:

StormTest:
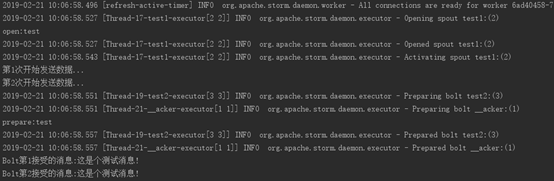
StormTest2:


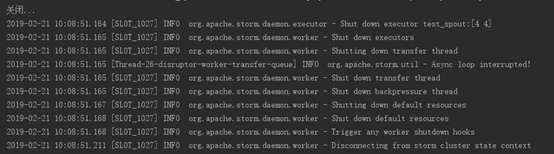
TopologyApp:



















 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









