









相关论文
《end-to-end memory networks》
《aspect level sentiment classification with deep memory network》
《entity disambiguation with memory network》
第一篇是2015年发表的关于注意力模型应用到NLP上的文章。一作是Sainbayar Sukhbaatar,LeCun的博士生。作者将自己的网络模型归结于一种新的循环神经网络,是对《Neural machine translation by jointly learning to align and translate》中注意力模型的改进,可以应用于QA或者语言模型等需要长期依赖的任务上。
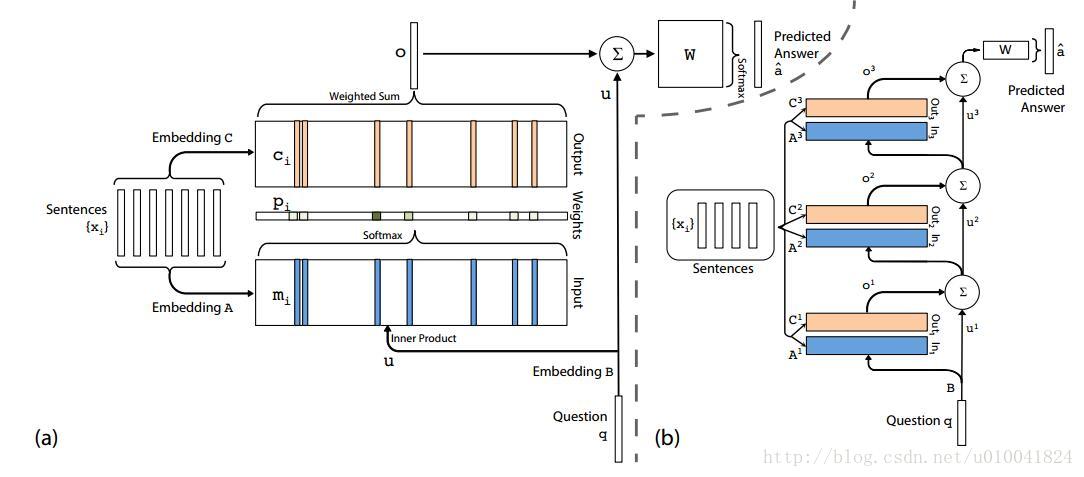
(a)为单层网络结构,(b)为多层网络结构
单层网络结构中,首先将Question和Sentences经过Embedding得到各自的向量表示,其中Sentences有两套Embedding方案。将Question和Sentences的Embedding向量做内积,经过softmax函数得到p向量。然后用p与Sentences的另一种Embedding做内积得到输出向量o。o与Question相加作为最后提取出来的信息。
可以将单层网络进行堆叠得到多层网络,如图b中所示。模型需要训练的参数主要是几个Embedding向量。在多层网络训练时,作者做了两种Embedding的尝试。一种Adjacent,一种Layer-wise(RNN-like)。目的是减少模型参数量。之后,作者还提出了一种postition encoding(PE)的概念。在得到m记忆单元的时候融合单词的位置信息。
第二篇是16年哈工大的一位博士,Duyu Tang所写。他将第一篇论文的模型应用到了aspect情感分析的任务上。对于给定的句子,和句子中的aspect单词,判断单词的情感。模型如下图所示。
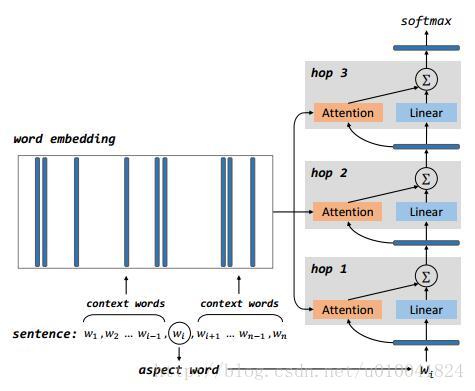
与第一篇中描述的处理过程相似,首先对sentence和aspect word进行Embedding。利用aspect word和context words得到不同上下文单词的权重。将得到的权重与aspect word再次进行结合,得到该hop的输出。
在Attention部分,作者利用单词的上下文和单词本身得到句子关于aspect word的表示。让句子学习关于aspect word重要的是上下文中的哪些单词。利用如下公式学习得到每个mi的权重。之后经过softmax函数,对权重进行归一化。
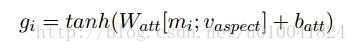
为了在Attention中加入单词的位置信息,作者提出了四个模型。其中模型二在后面实验中验证有较好的结果,且参数量较少(具体看论文吧)。
第三篇是17年哈工大的一位博士Yaming Sun所写,利用注意力模型进行实体消歧的任务。模型的基础也是来自于上两篇论文。任务是对于给定的指称(mention)和他的候选实体集(entity),从中挑出与指称表达意思最为相近的实体。
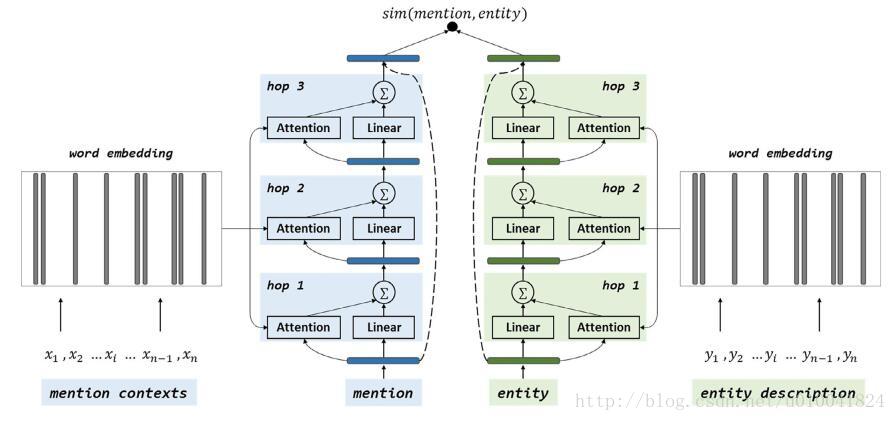
相似度函数使用的是余弦函数,模型训练时的损失函数是自己构造的如下所示。博主好奇在训练的时候是如何使用的。
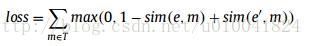
这几篇论文是将同一模型用在不同任务之上。工作量比较饱满,模型描述的也很清楚。网上有人开源了模型的keras版本链接。有兴趣的同学可以进行试验,欢迎交流。















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









