









序
- 本文简单记录一些自己读论文时看到的有趣的点,其他通俗的东西就不详细写了。
- 《Memory Networks》是这一系列的开山之作,也是本文的前篇,本文的提出是就在于 “End-to-End”,简单来说就是可以直接用反向传播优化算法训练模型了,就是文中提到的一个词:模式是连续的。
- 特点: 外部记忆,end-to-end
- 个人也找了个代码看了看:链接 ,当然代码github上很多,而且很有可能代码复现和论文说的细节不一致。
模型结构

Data_Input
- 三元组:(memory(所谓的document),question, answer)
- 当然,文中说每一个单词都是word_to_index过得,就是他们弄了一个词库,然后通过映射关系,把原本的word替换成index,常规操作。(当然你也可以,弄成one-hot的形式,因为我看论文在编码时用了相乘的方式,感觉这里是根据词表把单词one-hot过,所以后面直接相乘从embedding中提取vector,不过我看得源码用的look-up方式从embedding中找vector,就不存在考虑one-hot,所以细节问题还是看具体实现吧)
- 长度什么的也都是固定填充。
- 打印一个例子:

Embedding
-
其实就是所谓的图中的 A,C,B。
-
他们都是一个 V × E, V词库大小,V是词库大小,E是编码维度,随机初始化,随着模型训练逐渐优化。
-
其实和普通分类任务中embedding的没区别
-
那下图那个方块是什么?怎么出来的?个人觉得放一句论文里的话比较清晰:
-
Suppose we are given an input set x1… xi to be stored in memory. The entire set of {xi} are converted into memory vectors {mi} of dimension d computed by embedding each xi in a continuous space, in the simplest case, using an embedding matrix A (of
size d×V ).

-
其中A就是embedding矩阵,lj是位置编码
-
补充:看得代码里有一个生成词库的代码,感觉很巧妙:
from itertools import chain
from six.moves import reduce
# 去重:首先用集合取消集合内部的重复,然后用集合取并集
vocab = sorted(reduce(lambda x, y: x | y, (set(list(chain.from_iterable(s)) + q + a) for s, q, a in data)))
外部记忆?
- 这个地方本来是自己想重点看一下的,结果论文和代码看完,嗯????!!!
- 可能是我太菜了,我完全没有体会到这个外部记忆的点在哪里,感觉就是从embedding里用story_index把story找出来,一个对齐操作找了一个权重,然后数据乘于权重得到output,所以外部记忆存储是个什么东西…
- 这不就是个注意力吗…可能我对外部记忆存储这个词有什么误解。
这里用维度确认一下上面说的
question的ui


mi和ui求q 的维度变化
- 这里放上对应代码
# 原本u[-1]: [32,20]
# expand_dim: [32,20,1]
# tanspose: [32,1,20]
# [32,10,20] * [32,1,20] = [32,10,20]
self.u_temp = tf.transpose(tf.expand_dims(u[-1], -1), [0, 2, 1])
self.dotted = tf.reduce_sum(self.m_A * self.u_temp, 2)
# Calculate probabilities
self.probs = tf.nn.softmax(self.dotted)
self.probs_temp = tf.transpose(tf.expand_dims(self.probs, -1), [0, 2, 1])

验证
-
没用过*,所以这个维度变换有点怀疑,然后验证了一波。
-
返回值: 一个跟张量a和张量b类型一样的张量且最内部矩阵是a和b中的相应矩阵的乘积
-
tf.matmul()将矩阵a乘以矩阵b,生成a * b
-
其实就是一个点积

-
Ci的维度同理,这里就不验证了。
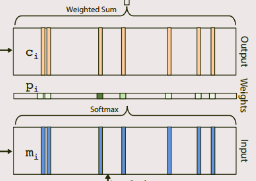
Input | output memory representation
- 对着上上图,很好懂
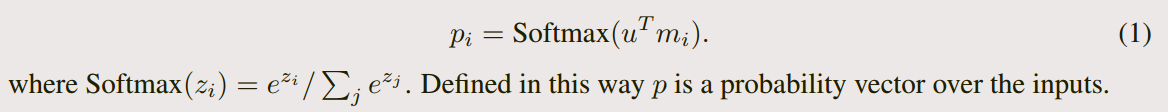
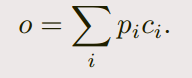
Generating the final prediction
- 同样结合上图:
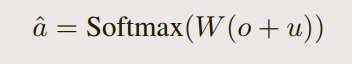
位置编码
- 论文表明,单纯的mi没有相对位置的信息,对于某些任务效果不好,所以加了一个位置编码进去:
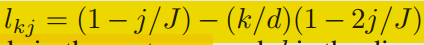
时间编码
- 意思是有的任务对于时间的顺序敏感,所以在计算mi时不止加位置编码,也可以加时间编码…但是个人看的代码没有实现这个,不过这个思路不错。

LS(线性开始训练)
In some of our experiments, we explored commencing training with the softmax in each memory layer removed,
making the model entirely linear except for the final softmax for answer prediction. When the
validation loss stopped decreasing, the softmax layers were re-inserted and training recommenced.
We refer to this as linear start (LS) training.
-
在我们的一些实验中,我们探索了在去除每个记忆层中的softmax后开始训练,使模型完全线性,除了最后的softmax的答案预测。当验证损失停止减少,重新插入softmax层并重新开始训练。我们称之为线性开始训练。
-
还有写参数配置和训练细节就不一一叙述了
DeepLearning与Local minima
-
这里个人暂时没特别想明白,为什么要怎么做。去除模型中的非线性部分,那么线性模型训练可以求出全局最优,然后再用这个结果微调预测?这么做有效的原因是什么?若有大佬明白还望解答。

扩充
- 个人暂时对这个外部记忆的体现很模糊,稍微找了些资料扩充一下:
[ 1 ]【序列到序列学习】带外部记忆机制的神经机器翻译
[ 2 ]记忆网络的结构简介
[ 3 ]【RS】Collaborative Memory Network for Recommendation Systems - 基于协同记忆网络的推荐系统
小结
- 排除细枝末节,这个网络挺简单的,但是个人还是有一点小疑惑。
- 如果从通篇角度来看,神经网络做了什么?…间接学了一个词向量出来,句向量是以加权求和出来的(这里权重是以类似于attention的方式求出来的),然后映射到词表空间,找到对应的答案的那个单词。
END
本文完















 3722
3722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









