









关键词
End2End, Memory Networks, Multiple hops
来源
arXiv 2015.03.31 (published at NIPS 2015)
特色
设计了全新网络,相对于LSTM,以词为单位的时序,memory network是以句子为单位。
解决方案
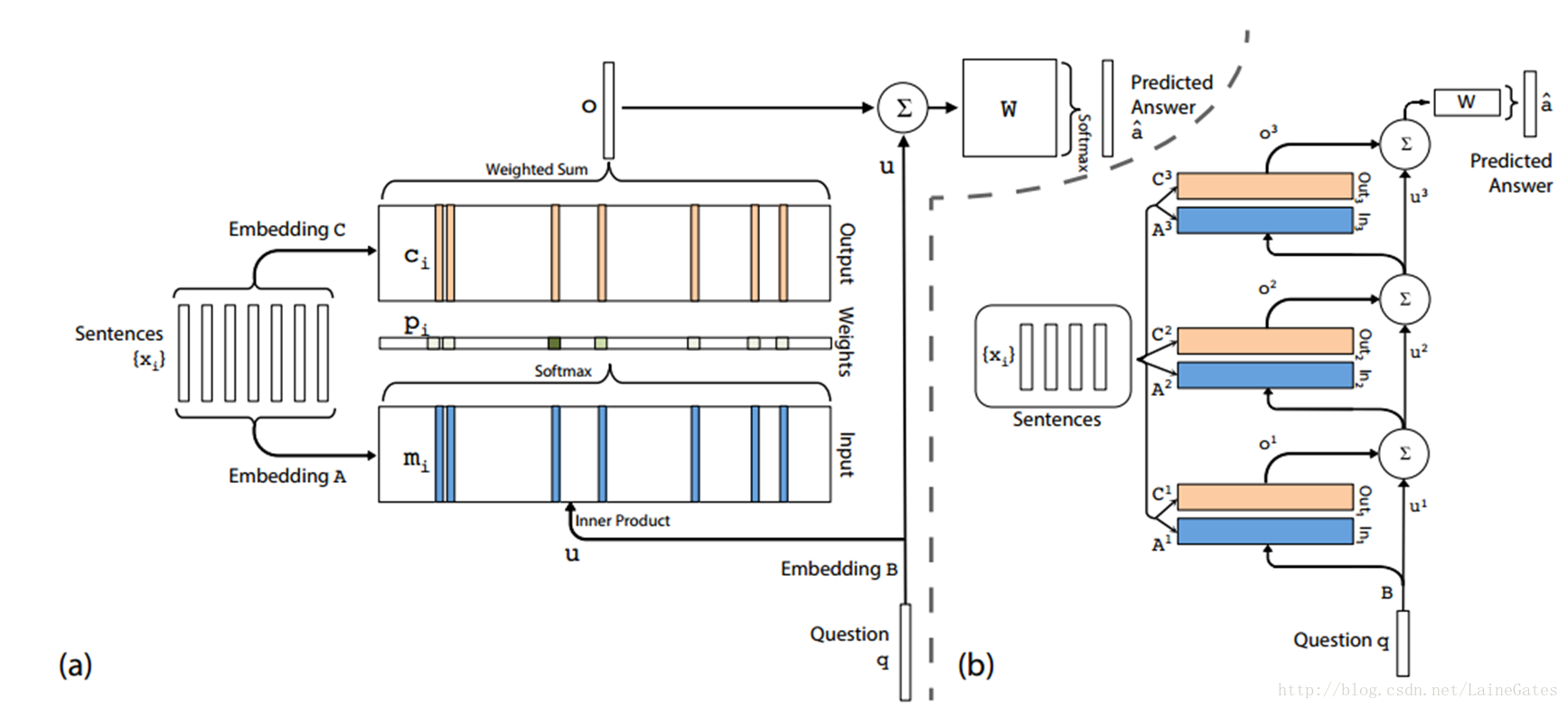
原图
加备注图
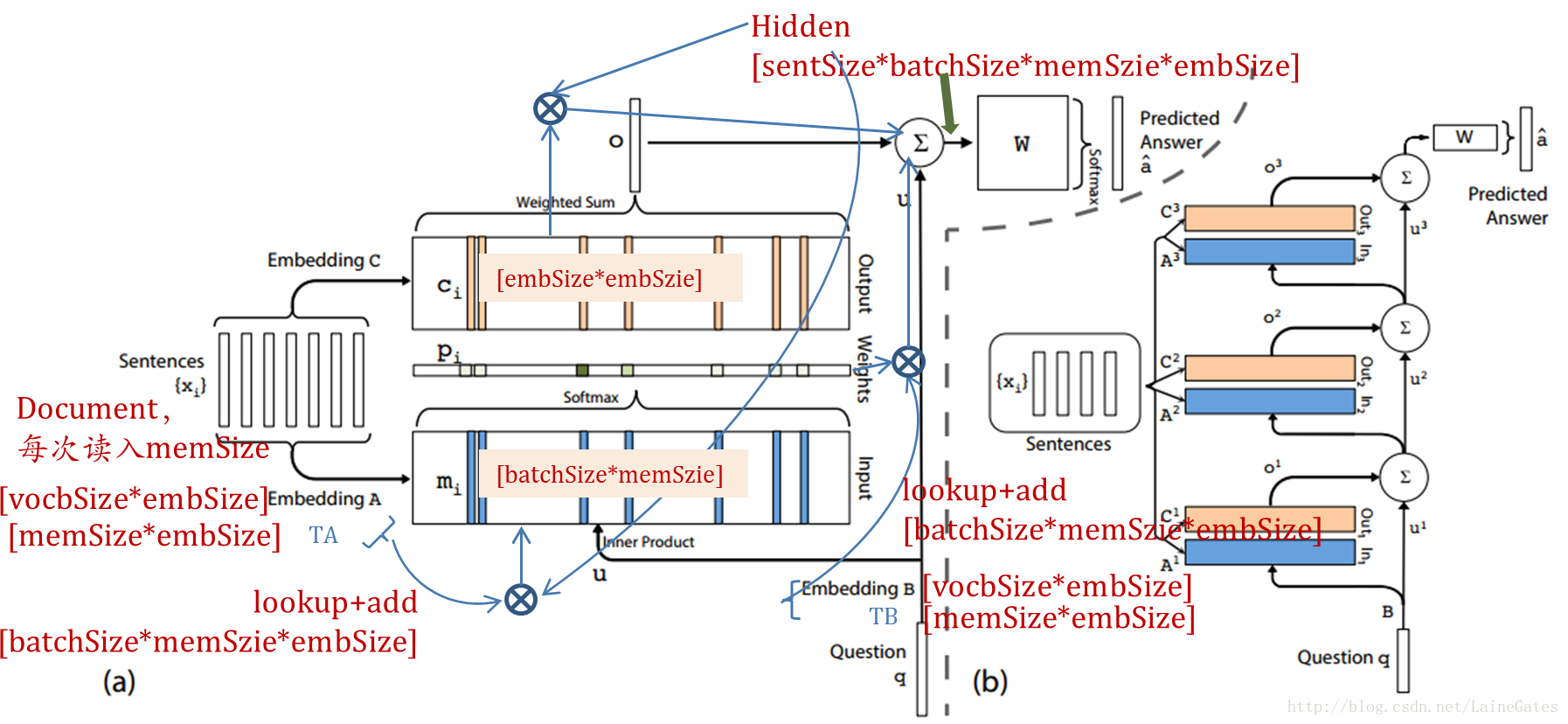
计算过程
按原图
lookup词表A获得句子向量表示,
mi=Axi
,
i
大小是memory size
计算attention,或者说计算输入的权重
将输出乘权重,得到最终的输出o
输出的嵌入向量
ci=Couti
,
i
大小是memory size
最终输出嵌入向量
查询的嵌入向量
u=Bq
预测结果
a^=softmax(W(o+u))
按实现代码
计算过程与原图不一致,我按论文的实现代码做了标注,参见备注图。
输入sentences和query时,都有矩阵TA和TB矩阵
即
Ain=Axi+TAxi
, i代表句子,长度固定为memory size
Aout=AinHlast
, H代表隐藏层,
Aout可看作mi
pi=softmax(Aout)
Bin=Bq+TBq
Bout=pBin
Cout=HlastBout
Dout=CoutBout
最后,保存
Dout
为新的Hidden
多层网络
原文提供两种方式。
第一种是邻接,即
Ak+1=Ck
,依次递推
第二种是类似于 RNN 中共享权重的模式,
A1=A2=…=Ak
,
C1=C2=…=Ck
。
其余与单层网络一致。
参考代码
facebook实现,使用Lua语言
网友实现,使用tensorflow















 3723
3723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









