







16年一月份阅读了吴军的《数学之美》,真有种相见恨晚的感觉!对于刚刚学习自然语言处理的人来说,这是最佳入门读物,没有之一。下面是我在学习中做的一些知识点的阅读笔记,有些内容、公式摘自Tomas M.Cover的《信息论基础》,详情请参考原著,本文仅作个人阅读笔记学习使用。
1.熵、联合熵、条件熵、互信息、相对熵
信息的作用是排除不确定性,信息量就得关于不确定性的多少。
对于任意一个随机变量X,其熵为:

对于服从联合分布为p(x,y)的一对离散随机变量,即x,y一起出现的概率,其联合熵为
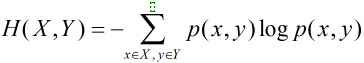
条件熵即在知道Y取不同值时X的概率分布,在Y的条件下的条件熵为
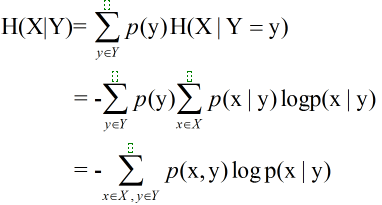
延伸:一对随机变量的联合熵等于其中一个随机变量的熵加上另一个随机变量的条件熵:
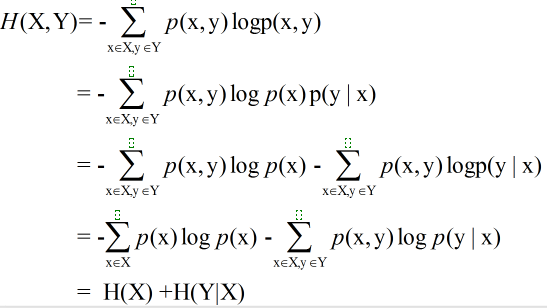
互信息(Mutual Information)度量两个随机事件的相关性,度量一个随机变量包含另一个随机变量的信息量,即在给定另一随机变量知识的条件下,原随机变量不确定度的缩减量:
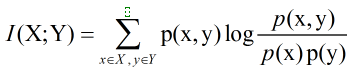
相对熵(Relative Entropy),又叫交叉熵,也用来衡量相关性,但衡量的是两个取值为正的函数的相关性,刻画两个概率分布之间的距离的一种度量,互信息是它的特殊形式。相对熵D(p||q)度量当真实分布为p而假设分布为q时的无效性。两个概率密度函数为p(x)和q(x)之间的相对熵公式如下:
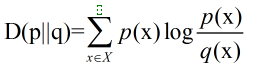
延伸:两个随机变量X和Y,他们的联合概率密度函数为p(x,y),其边际概率密度函数分别是p(x)和
p(y)
。互信息为
联合分布
p(x,y)和
乘积分布
p(x)p(y)之间的相对熵:
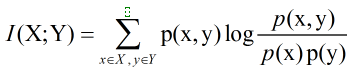
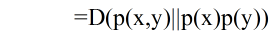
相对熵是不对称的,即
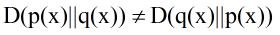
为了使用的方便性,詹森和香农提出新的相对熵计算方法,即将上面的不等式两边取平均:
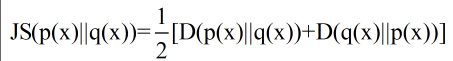
这一计算方法曾用在google的自动问答系统中,衡量两个答案的相似性。如何衡量需要进一步探索!
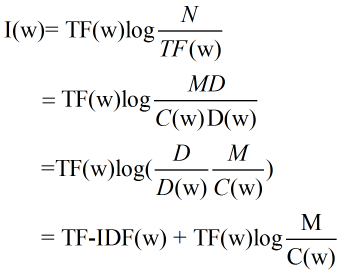
相对熵的应用:文中提出利用相对熵可以得到词频率-逆向文档频率(TF-IDF)。IDF的公式为log(D/Dw),其中D是全部文档数,Dw是关键词w出现的文档数量。就是一个特定条件下(TF为特定条件)关键词的概率分布的相对熵。
推导思路:一个关键词的权重可以利用这个词的信息量来衡量,即:
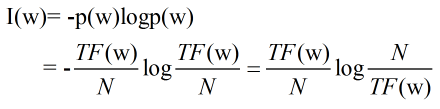
其中N是整个语料库的大小,是个可以忽略的常数。上述公式可以简化为:
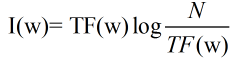
考虑关键词的分辨率,满足一下假设:
(1)每个文献大小基本相同,均为M个词,M=N/D;
(2)一个关键词无论在文献中出现几次,贡献都相同,其要么在一个文献中出现C(w)=TF(w)/D(w)次,要么出现零次。
此时每个关键词的权重及其信息量表示为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









