









该实验证明了传统密码体制通过统计分析等办法很容易破译。
Caesar密码作为一种最为古老的对称加密体制,在古罗马的时候都已经很流行,它的基本思想是:通过把字母移动一定的位数来实现加密和解密。明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。例如,当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推X将变成 A,Y变成B,Z变成C。由此可见,位数就是Caesar密码加密和解密的密钥。
本次程序在网上选取了3篇类型不一样的文章(来自经济、教育,人物)制作成一个txt文档,名称为 明文.txt。然后我用Caesar密码对其进行加密,形成文档 密文.txt。
并且读取密文.txt,依次查找单字母出现的频率、双字母出现的次数以及三字母出现的次数,并且由于数据量较大,将三者依次输出到三个txt文档中,并且在网上查找到了字母频率分布表,如下:



加密前的明文如下:
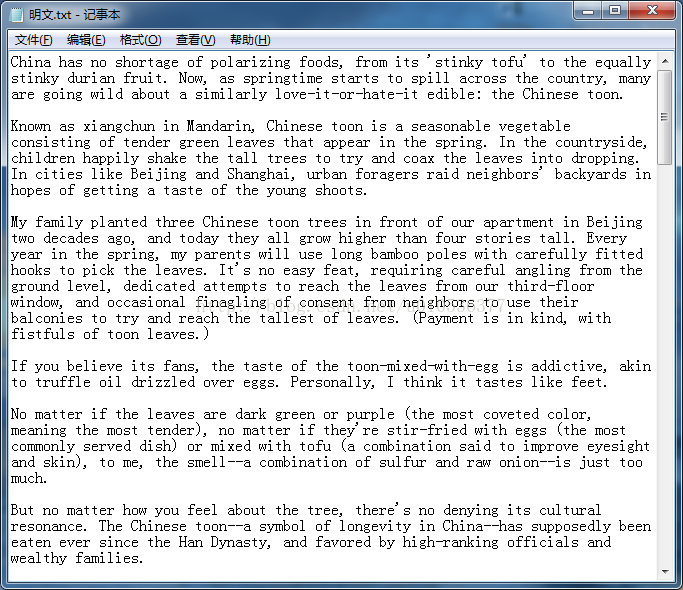
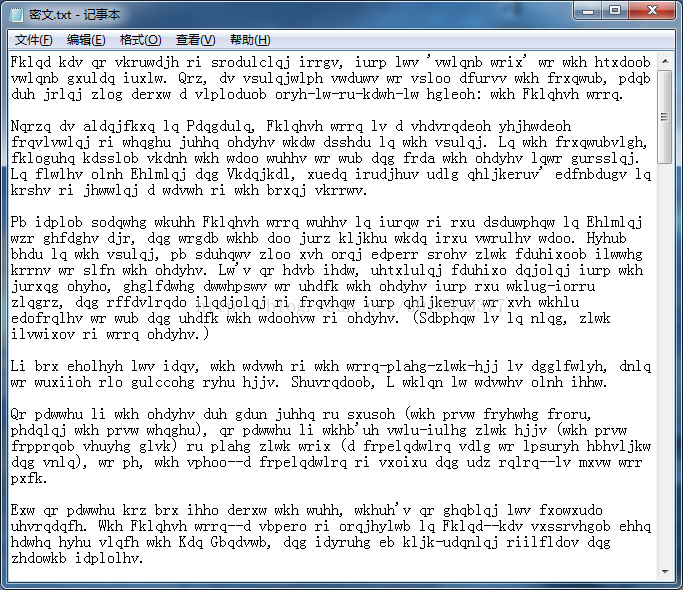
加密后的密文如下:
单字母统计结果如下(从大到小排序输出):
双字母统计结果如下:
三字母统计结果如下(仅仅统计了出现次数,结果很长见附件):
分析:首先感觉单字母统计情况与实际频率分布对比,发现密文中H和h出现的概率大约为12%,与第二9%相差比较大,初步判断H对应的明文为E;注意到W在密文中出现概率为9%左右,且频率分布表中T的概率也为9%左右,初步判断W对应的明文为T;概率分布表中出现概率最小的是C,且频率分布表中Z的概率最小,初步判断C对应的明文为Z;依次类推……我们可以根据单字母的频率分布初步破解该加密方法;
同样,由于我们拥有双字母和三字母出现次数的情况,这2种情况为破解的推理过程提供了校验和推理的依据,不难发现加密的规律,从而应用统计分析的方式破解加密方式。
Node.java
/**
* 用于保存概率(次数)和字符或者字母的信息 以结构体的形式,利于排序
*/
public class Node {
private double p;// 记录概率
private char alpha;// 记录对应的字母
private String str;// 记录对应的字符串
public Node(double p, char alpha) {
this.p = p;
this.alpha = alpha;
}
public Node(double p, String str) {
this.p = p;
this.str = str;
}
public void setp(double p) {
this.p = p;
}
public void setalpha(char a) {
this.alpha = a;
}
public void setstring(String s) {
this.str = s;
}
public double getp() {
return p;
}
public char getalpha() {
return alpha;
}
public String getstr() {
return str;
}
public char getalphabig() {
return (char) (alpha + 32);
}
}
Caesar.java
import java.io.*;
import java.util.ArrayList;
/**
* 运行说明:注意将明文.txt的位置与代码中保持一致,才可以正常运行,修改代码57行位置为明文的路径即可
*
*
* 本程序参考了数据结构3.1.4中的代码,对txt文件进行读取, 并且译码存入到另外一个txt文件中,并且统计每个字母在明文和明文中
* 出现的概率,查阅字母频率分布表后,对明文进行攻击
*/
public class Caesar {
public static final int ALPHASIZE = 26;// 英文字母表
public static final char[] alpha = { 'A', 'B', 'C', 'D', 'E', 'F', 'G',
'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z' };
public static final char[] alpha1 = { 'a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z' };
protected char[] encrypt = new char[ALPHASIZE];
protected char[] encrypt1 = new char[ALPHASIZE];
protected char[] decrypt = new char[ALPHASIZE];
protected char[] decrypt1 = new char[ALPHASIZE];
public Caesar() {
for (int i = 0; i < ALPHASIZE; i++) {
encrypt[i] = alpha[(i + 3) % ALPHASIZE];
encrypt1[i] = alpha1[(i + 3) % ALPHASIZE];
}
for (int i = 0; i < ALPHASIZE; i++) {
decrypt[encrypt[i] - 'A'] = alpha[i];
decrypt1[encrypt1[i] - 'a'] = alpha1[i];
}
}
public String encrypt(String secret) {
char[] mess = secret.toCharArray();
for (int i = 0; i < mess.length; i++) {
if (Character.isUpperCase(mess[i]))
mess[i] = encrypt[mess[i] - 'A'];
else if (Character.isLowerCase(mess[i]))
mess[i] = encrypt1[mess[i] - 'a'];
}
return new String(mess);
}
public String decrypt(String secret) {
char[] mess = secret.toCharArray();
for (int i = 0; i < mess.length; i++)
if (Character.isUpperCase(mess[i]))
mess[i] = decrypt[mess[i] - 'A'];
else if (Character.isLowerCase(mess[i]))
mess[i] = decrypt1[mess[i] - 'a'];
return new String(mess);
}
public static void main(String args[]) throws Exception {
Caesar cipher = new Caesar();
System.out.println("Encryption order=" + new String(cipher.encrypt));
System.out.println("Decryption order=" + new String(cipher.decrypt));
// String secret="The Eagle IS IN Play;MEET AT JOE'S.";
FileReader in = new FileReader(new File(
"C:\\Users\\Administrator\\Desktop\\明文.txt"));
BufferedReader sec = new BufferedReader(in);// 字节流
FileOutputStream out = new FileOutputStream(
"C:\\Users\\Administrator\\Desktop\\密文.txt");
// FileOutputStream out1=new
// FileOutputStream("C:\\Users\\Administrator\\Desktop\\2.txt");
String secret = sec.readLine();
int jishu_mingwen[] = new int[52];// 记录出现次数
int jishu_miwen[] = new int[52];// 记录出现次数
while (secret != null) {
char[] sss = secret.toCharArray();// 字符串变成字符数组
/** 统计明文信息 */
for (int i = 0; i < sss.length; i++) {
if (Character.isUpperCase(sss[i]))
jishu_mingwen[sss[i] - 'A']++;
else if (Character.isLowerCase(sss[i]))
jishu_mingwen[26 + sss[i] - 'a']++;
}
secret = cipher.encrypt(secret);// 译码
byte[] buff = secret.getBytes();
if (secret.equals(""))
buff = "\r\n\r\n".getBytes();
out.write(buff);// 输出到文件
sss = secret.toCharArray();// 字符串变成字符数组
/** 统计密文信息 */
for (int i = 0; i < sss.length; i++) {
if (Character.isUpperCase(sss[i]))
jishu_miwen[sss[i] - 'A']++;
else if (Character.isLowerCase(sss[i]))
jishu_miwen[26 + sss[i] - 'a']++;
}
secret = sec.readLine();// 读取下一行
}
in.close();// 关闭文件
/** 计算明文熵 */
int sum = 0;
for (int i = 0; i < 52; i++)
sum += jishu_mingwen[i];
double Entropy = 0;
for (int i = 0; i < 52; i++) {
double p = (double) jishu_mingwen[i] / sum;
if (p != 0)
Entropy += -p * Math.log(p) / Math.log(2);
}
System.out.println("统计得知明文熵为:" + Entropy);
/** 计算密文熵 */
sum = 0;
for (int i = 0; i < 52; i++)
sum += jishu_miwen[i];
Entropy = 0;
double[] pp = new double[26];// 计算出现频率
Node[] node = new Node[26];
for (int i = 0; i < 52; i++) {
double p = (double) jishu_miwen[i] / sum;
if (p != 0)
Entropy += -p * Math.log(p) / Math.log(2);
if (i < 26)
pp[i] = p;
else {
pp[i - 26] = pp[i - 26] + p;
node[i - 26] = new Node(pp[i - 26], alpha[i - 26]);
}
}
System.out.println("统计得知密文熵为:" + Entropy);
FileOutputStream out1 = new FileOutputStream(
"C:\\Users\\Administrator\\Desktop\\单个字母出现频率分布计算结果.txt");
for (int i = 0; i < 25; i++)
// 排序
for (int j = i + 1; j < 26; j++) {
if (node[i].getp() < node[j].getp()) {
Node temp;
temp = node[i];
node[i] = node[j];
node[j] = temp;
}
}
for (int i = 0; i < 26; i++) {
byte[] buff = (node[i].getalpha() + "和" + node[i].getalphabig()
+ "出现的频率" + node[i].getp() + "\r\n").getBytes();
out1.write(buff);
}
out.close();
out1.close();
// 计算双字母出现频率
in = new FileReader(new File(
"C:\\Users\\Administrator\\Desktop\\密文.txt"));
sec = new BufferedReader(in);// 字节流
secret = sec.readLine();
ArrayList<Node> tongji = new ArrayList<Node>();
while (secret != null) {
secret.toLowerCase();
for (int i = 0; i < secret.length() - 1; i++) {
boolean flag = false;// 队列中的没有匹配
for (int j = 0; j < tongji.size(); j++) {
if (secret.substring(i, i + 2).equals(
tongji.get(j).getstr())) {
flag = true;
tongji.get(j).setp(tongji.get(j).getp() + 1);// 此时用途为记录出现次数
break;
}
}
boolean flag2 = true;
if (secret.substring(i, i + 1).equals(" ")
|| secret.substring(i + 1, i + 2).equals(" "))
flag2 = false;
if (!flag && flag2)
tongji.add(new Node(1, secret.substring(i, i + 2)));// 初始次数为1
}
secret = sec.readLine();// 读取下一行
}
in.close();
// 排序
for (int i = 0; i < tongji.size() - 1; i++)
for (int j = i + 1; j < tongji.size(); j++)
if (tongji.get(i).getp() < tongji.get(j).getp()) {
Node temp = tongji.get(i);
tongji.set(i, tongji.get(j));
tongji.set(j, temp);
}
out1 = new FileOutputStream(
"C:\\Users\\Administrator\\Desktop\\双字母出现频率分布计算结果.txt");
byte[] buff = ("双字母出现次数从多到少排序如下:" + "\r\n").getBytes();
out1.write(buff);
for (int i = 0; i < tongji.size(); i++) {
buff = ("双字母" + tongji.get(i).getstr() + "出现次数为:"
+ tongji.get(i).getp() + "次\r\n").getBytes();
out1.write(buff);
}
// 计算三字母出现频率
in = new FileReader(new File(
"C:\\Users\\Administrator\\Desktop\\密文.txt"));
sec = new BufferedReader(in);// 字节流
secret = sec.readLine();
tongji.clear();// 情况统计,即双字母的数据
while (secret != null) {
secret.toLowerCase();
for (int i = 0; i < secret.length() - 2; i++) {
boolean flag = false;// 队列中的没有匹配
for (int j = 0; j < tongji.size(); j++) {
if (secret.substring(i, i + 3).equals(
tongji.get(j).getstr())) {
flag = true;
tongji.get(j).setp(tongji.get(j).getp() + 1);// 此时用途为记录出现次数
break;
}
}
boolean flag2 = true;
if (secret.substring(i, i + 1).equals(" ")
|| secret.substring(i + 1, i + 2).equals(" ")
|| secret.substring(i + 2, i + 3).equals(" "))
flag2 = false;
if (!flag && flag2)
tongji.add(new Node(1, secret.substring(i, i + 3)));// 初始次数为1
}
secret = sec.readLine();// 读取下一行
}
in.close();
// 排序
for (int i = 0; i < tongji.size() - 1; i++)
for (int j = i + 1; j < tongji.size(); j++)
if (tongji.get(i).getp() < tongji.get(j).getp()) {
Node temp = tongji.get(i);
tongji.set(i, tongji.get(j));
tongji.set(j, temp);
}
out1 = new FileOutputStream(
"C:\\Users\\Administrator\\Desktop\\三字母出现频率分布计算结果.txt");
buff = ("三字母出现次数从多到少排序如下:" + "\r\n").getBytes();
out1.write(buff);
for (int i = 0; i < tongji.size(); i++) {
buff = ("三字母" + tongji.get(i).getstr() + "出现次数为:"
+ tongji.get(i).getp() + "次\r\n").getBytes();
out1.write(buff);
}
}
}













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









