






论文阅读笔记:Fully Convolutional Networks forSemantic Segmentation
这是CVPR 2015拿到best paper候选的论文。
论文下载地址:Fully Convolutional Networks forSemantic Segmentation
尊重原创,转载请注明:http://blog.csdn.net/tangwei2014
提出了一种end-to-end的做semantic segmentation的方法,简称FCN。
如下图所示,直接拿segmentation 的 ground truth作为监督信息,训练一个端到端的网络,让网络做pixelwise的prediction,直接预测label map。
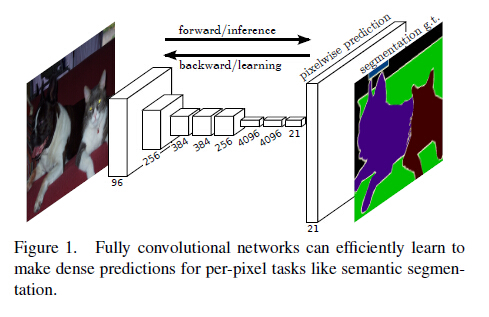
2.问题&解决办法
1)如何做pixelwise的prediction?
传统的网络是subsampling的,对应的输出尺寸会降低,要想做pixelwiseprediction,必须保证输出尺寸。
解决办法:
(1)对传统网络如AlexNet,VGG等的最后全连接层变成卷积层。
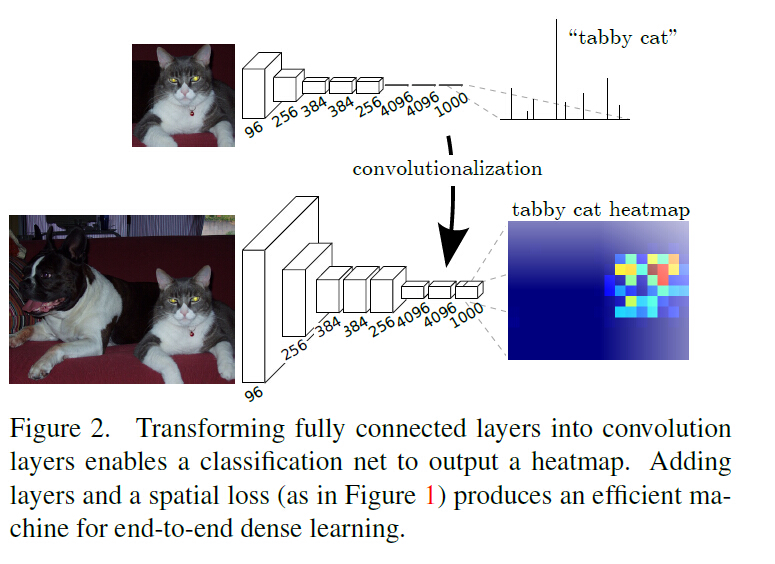
例如VGG16中第一个全连接层是25088x4096的,将之解释为512x7x7x4096的卷积核,则如果在一个更大的输入图像上进行卷积操作(上图的下半部分),原来输出4096维feature的节点处(上图的上半部分),就会输出一个coarsefeature map。
这样做的好处是,能够很好的利用已经训练好的supervisedpre-training的网络,不用像已有的方法那样,从头到尾训练,只需要fine-tuning即可,训练efficient。
(2)加In-network upsampling layer。
对中间得到的featuremap做bilinear上采样,就是反卷积层。实现把conv的前传和反传过程对调一下即可。
2)如何refine,得到更好的结果?
upsampling中步长是32,输入为3x500x500的时候,输出是544x544,边缘很不好,并且limit thescale of detail of the upsampling output。
解决办法:
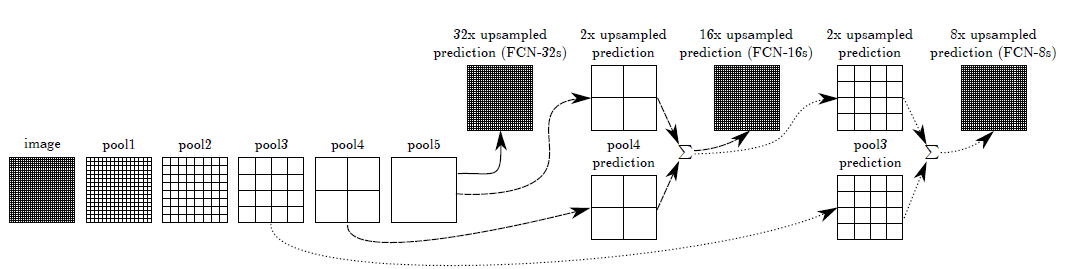
采用skiplayer的方法,在浅层处减小upsampling的步长,得到的finelayer 和 高层得到的coarselayer做融合,然后再upsampling得到输出。这种做法兼顾local和global信息,即文中说的combiningwhat and where,取得了不错的效果提升。FCN-32s为59.4,FCN-16s提升到了62.4,FCN-8s提升到62.7。可以看出效果还是很明显的。
3.训练细节
用AlexNet,VGG16或者GoogleNet训练好的模型做初始化,在这个基础上做fine-tuning,全部都fine-tuning。
采用wholeimage做训练,不进行patchwisesampling。实验证明直接用全图已经很effectiveand efficient。
对classscore的卷积层做全零初始化。随机初始化在性能和收敛上没有优势。
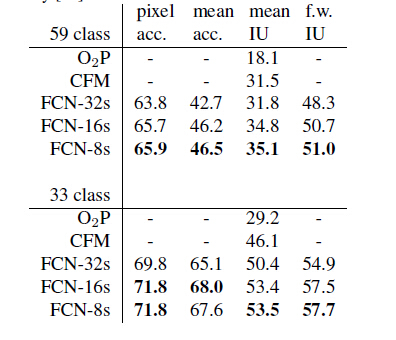
4.结果
当然是state-of-the-art的了。感受一下:















 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









