







论文链接:https://arxiv.org/abs/1411.4038
作者源码链接:https://github.com/shelhamer/fcn.berkeleyvision.org
1、简介
本文是对神经网络的一个较大改进,通过端到端、像素到像素的训练,实现像素级别的分类任务,并且取得了很好的效果,同时也是PASCAL VOC当时最出色的分割方法。
2、FCN
2.1 卷积化
在传统的分类网络中,网络的最后一般会链接全连接层,通过全连接层将二维的图像变为一维的分类信息,得到图像的类别,然而在像素级别的分类任务中,对于输入的二维图像,我们需要得到的结果仍然需要是二维的,因此作者丢弃了全连接层,使用全卷积层进行卷积。
如图所示为AlexNet的例子,作者将最后三层的全连接层变为卷积层,并且卷积核的大小分别为:(4096,6,6)、(4096,1,1)、(1000,1,1)

2.2 上采样
在CNN网络中,池化层会使特征图大小变小,而我们的目标是得到一个与原图像同样大小的结果图,所以这里需要对提取得到的特征图进行上采样。
- 1、利用线性差值进行上采样
- 2、利用反卷积进行上采样
反卷积也可叫做转置卷积,并且作者表明,在上采样的过程中,卷积核参数不需要固定不变,是可以被学习的,但作者实验中学习率为0。
下图为两种反卷积例子:
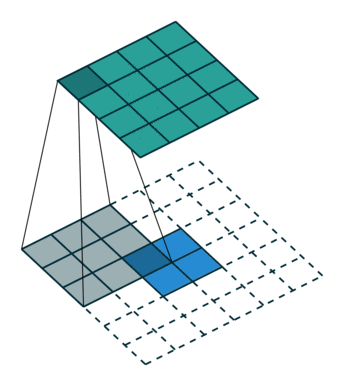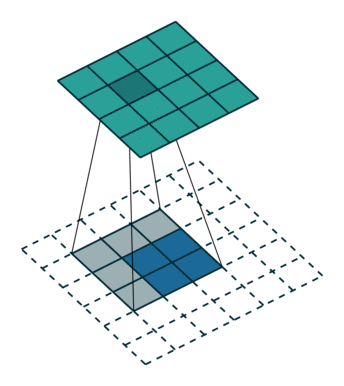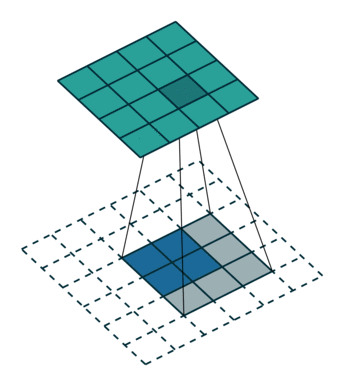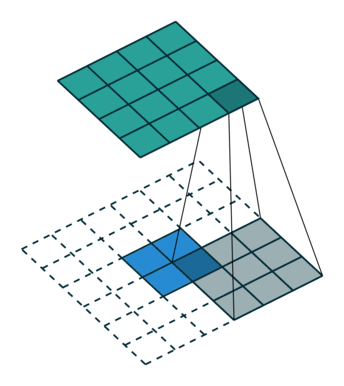
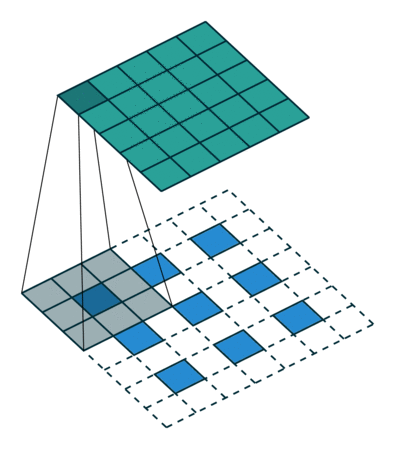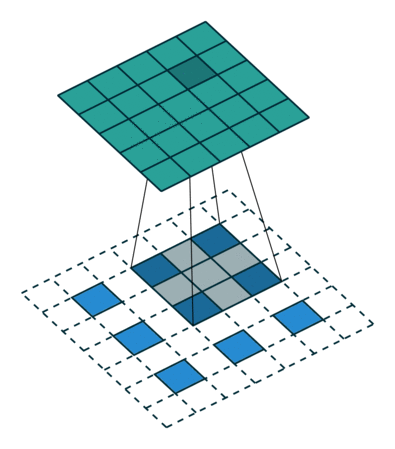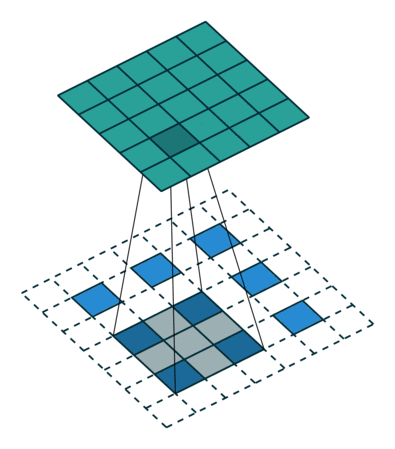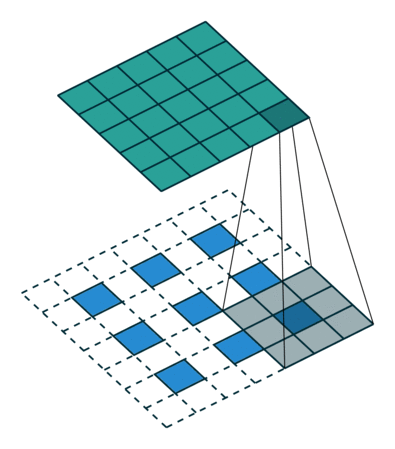
2.3 跳跃结构
为提高结果,作者采用如下结构对网络进行优化:
例如经过5次卷积(和pooling)以后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。
对第5层的输出(32倍放大)反卷积到原图大小,得到的结果还是不够精确,一些细节无法恢复。于是作者将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。下图是这个卷积和反卷积上采样的过程:

3、实验结果
上图:

可以发现FCN-8s的检测精度最高。

与其他算法相比,fcn的效果也达到了最优。















 6749
6749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









