







以上链接是一系列讲的特别好的深度学习的博客。
六、浅层学习(Shallow Learning)和深度学习(Deep Learning)
七、Deep learning与Neural Network
9.3、Restricted Boltzmann Machine(RBM)限制波尔兹曼机
9.4、Deep BeliefNetworks深信度网络 (DBN)
9.5、Convolutional Neural Networks卷积神经网络 (CNN)
深度学习,是机器学习的升华,机器学习需要手工地选取特征是一件非常费力、启发式(需要专业知识)的方法,能不能选取好很大程度上靠经验和运气,而且它的调节需要大量的时间。
既然手工选取特征不太好,那么能不能自动地学习一些特征呢?答案是能!Deep Learning就是用来干这个事情的,看它的一个别名UnsupervisedFeature Learning,就可以顾名思义了,Unsupervised的意思就是不要人参与特征的选取过程。
人们对于神经系统的进一步思考。神经-中枢-大脑的工作过程,或许是一个不断迭代、不断抽象的过程。
这里的关键词有两个,一个是抽象,一个是迭代。从原始信号,做低级抽象,逐渐向高级抽象迭代。人类的逻辑思维,经常使用高度抽象的概念。 例如,从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图。而抽象层面越高,存在的可能猜测就越少,就越利于分类。例如,单词集合和句子的对应是多对一的,句子和语义的对应又是多对一的,语义和意图的对应还是多对一的,这是个层级体系。
所以深度学习的关键是特征:
学习算法在一个什么粒度上的特征表示,才有能发挥作用?
他们提出的问题是,如何从这400个碎片中,选取一组碎片,S[k], 通过叠加的办法,合成出一个新的碎片,而这个新的碎片,应当与随机选择的目标碎片 T,尽可能相似,同时,S[k] 的数量尽可能少。用数学的语言来描述,就是:
Sum_k (a[k] * S[k]) --> T, 其中 a[k] 是在叠加碎片 S[k] 时的权重系数。
为解决这个问题,Bruno Olshausen和 David Field 发明了一个算法,稀疏编码(Sparse Coding)。
稀疏编码是一个重复迭代的过程,每次迭代分两步:
1)选择一组 S[k],然后调整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
经过几次迭代后,最佳的 S[k] 组合,被遴选出来了。令人惊奇的是,被选中的 S[k],基本上都是照片上不同物体的边缘线,这些线段形状相似,区别在于方向。
结构性特征表示
小块的图形可以由基本edge构成,更结构化,更复杂的,具有概念性的图形如何表示呢?这就需要更高层次的特征表示,比如V2,V4。因此V1看像素级是像素级。V2看V1是像素级,这个是层次递进的,高层表达由底层表达的组合而成。专业点说就是基basis。V1取提出的basis是边缘,然后V2层是V1层这些basis的组合,这时候V2区得到的又是高一层的basis。即上一层的basis组合的结果,上上层又是上一层的组合basis……(所以有大牛说Deep learning就是“搞基”,因为难听,所以美其名曰Deep learning或者Unsupervised Feature Learning)
对于深度学习来说,其思想就是对堆叠多个层,也就是说这一层的输出作为下一层的输入。通过这种方式,就可以实现对输入信息进行分级表达了。
另外,前面是假设输出严格地等于输入,这个限制太严格,我们可以略微地放松这个限制,例如我们只要使得输入与输出的差别尽可能地小即可,这个放松会导致另外一类不同的Deep Learning方法。上述就是Deep Learning的基本思想。
浅层学习是机器学习的第一次浪潮。
20世纪80年代末期,用于人工神经网络的反向传播算法(也叫Back Propagation算法或者BP算法)的发明,给机器学习带来了希望,掀起了基于统计模型的机器学习热潮。这个热潮一直持续到今天。人们发现,利用BP算法可以让一个人工神经网络模型从大量训练样本中学习统计规律,从而对未知事件做预测。这种基于统计的机器学习方法比起过去基于人工规则的系统,在很多方面显出优越性。这个时候的人工神经网络,虽也被称作多层感知机(Multi-layer Perceptron),但实际是种只含有一层隐层节点的浅层模型。
20世纪90年代,各种各样的浅层机器学习模型相继被提出,例如支撑向量机(SVM,Support Vector Machines)、 Boosting、最大熵方法(如LR,Logistic Regression)等。这些模型的结构基本上可以看成带有一层隐层节点(如SVM、Boosting),或没有隐层节点(如LR)。这些模型无论是在理论分析还是应用中都获得了巨大的成功。相比之下,由于理论分析的难度大,训练方法又需要很多经验和技巧,这个时期浅层人工神经网络反而相对沉寂。
深度学习的实质,是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。因此,“深度模型”是手段,“特征学习”是目的。区别于传统的浅层学习,深度学习的不同在于:1)强调了模型结构的深度,通常有5层、6层,甚至10多层的隐层节点;2)明确突出了特征学习的重要性,也就是说,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易。与人工规则构造特征的方法相比,利用大数据来学习特征,更能够刻画数据的丰富内在信息。
BP算法存在的问题:
(1)梯度越来越稀疏:从顶层越往下,误差校正信号越来越小;
(2)收敛到局部最小值:尤其是从远离最优区域开始的时候(随机值初始化会导致这种情况的发生);
(3)一般,我们只能用有标签的数据来训练:但大部分的数据是没标签的,而大脑可以从没有标签的的数据中学习;
2006年,hinton提出了在非监督数据上建立多层神经网络的一个有效方法,简单的说,分为两步,一是每次训练一层网络,二是调优,使原始表示x向上生成的高级表示r和该高级表示r向下生成的x'尽可能一致。方法是:
1)首先逐层构建单层神经元,这样每次都是训练一个单层网络。
2)当所有层训练完后,Hinton使用wake-sleep算法进行调优。
将除最顶层的其它层间的权重变为双向的,这样最顶层仍然是一个单层神经网络,而其它层则变为了图模型。向上的权重用于“认知”,向下的权重用于“生成”。然后使用Wake-Sleep算法调整所有的权重。让认知和生成达成一致,也就是保证生成的最顶层表示能够尽可能正确的复原底层的结点。比如顶层的一个结点表示人脸,那么所有人脸的图像应该激活这个结点,并且这个结果向下生成的图像应该能够表现为一个大概的人脸图像。Wake-Sleep算法分为醒(wake)和睡(sleep)两个部分。
1)wake阶段:认知过程,通过外界的特征和向上的权重(认知权重)产生每一层的抽象表示(结点状态),并且使用梯度下降修改层间的下行权重(生成权重)。也就是“如果现实跟我想象的不一样,改变我的权重使得我想象的东西就是这样的”。
2)sleep阶段:生成过程,通过顶层表示(醒时学得的概念)和向下权重,生成底层的状态,同时修改层间向上的权重。也就是“如果梦中的景象不是我脑中的相应概念,改变我的认知权重使得这种景象在我看来就是这个概念”。
对于wake-sleep:我的理解是:wake阶段,就是通过实际输入对特征们的认知权重进行分配,然后使用梯度下降修改特征抽象的下行权重。sleep阶段则相反
deep learning训练过程具体如下:
1)使用自下上升非监督学习(就是从底层开始,一层一层的往顶层训练):
采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,是和传统神经网络区别最大的部分(这个过程可以看作是feature learning过程):
具体的,先用无标定数据训练第一层,训练时先学习第一层的参数(这一层可以看作是得到一个使得输出和输入差别最小的三层神经网络的隐层),由于模型capacity的限制以及稀疏性约束,使得得到的模型能够学习到数据本身的结构,从而得到比输入更具有表示能力的特征;在学习得到第n-1层后,将n-1层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数;
2)自顶向下的监督学习(就是通过带标签的数据去训练,误差自顶向下传输,对网络进行微调):
基于第一步得到的各层参数进一步fine-tune整个多层模型的参数,这一步是一个有监督训练过程;第一步类似神经网络的随机初始化初值过程,由于DL的第一步不是随机初始化,而是通过学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果;所以deep learning效果好很大程度上归功于第一步的feature learning过程。
Deep Learning的常用模型或者方法
AutoEncoder自动编码器
经过上面的方法,我们就可以得到很多层了。至于需要多少层(或者深度需要多少,这个目前本身就没有一个科学的评价方法)需要自己试验调了。每一层都会得到原始输入的不同的表达。当然了,我们觉得它是越抽象越好了,就像人的视觉系统一样。
到这里,这个AutoEncoder还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如罗杰斯特回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)去训练。
Sparse AutoEncoder稀疏自动编码器:
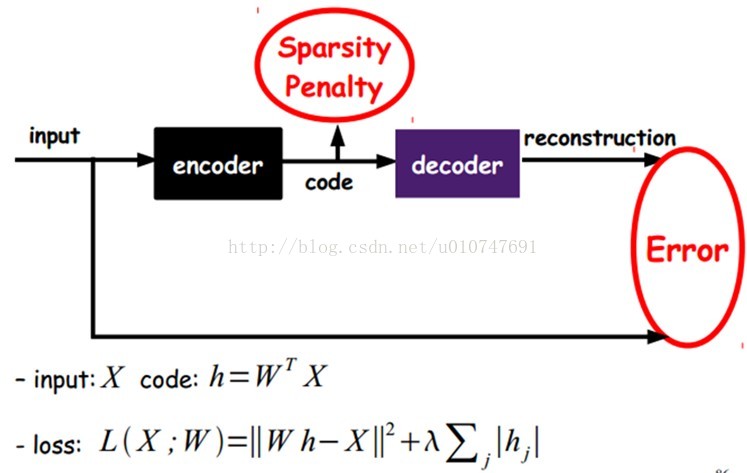
如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)。
Denoising AutoEncoders降噪自动编码器:
降噪自动编码器DA是在自动编码器的基础上,训练数据加入噪声,所以自动编码器必须学习去去除这种噪声而获得真正的没有被噪声污染过的输入。因此,这就迫使编码器去学习输入信号的更加鲁棒的表达,这也是它的泛化能力比一般编码器强的原因。DA可以通过梯度下降算法去训练。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









