







昨天需要对柏林情感语音库中的535段承载七种不同情感的语音片段进行重命名以方便后续处理。
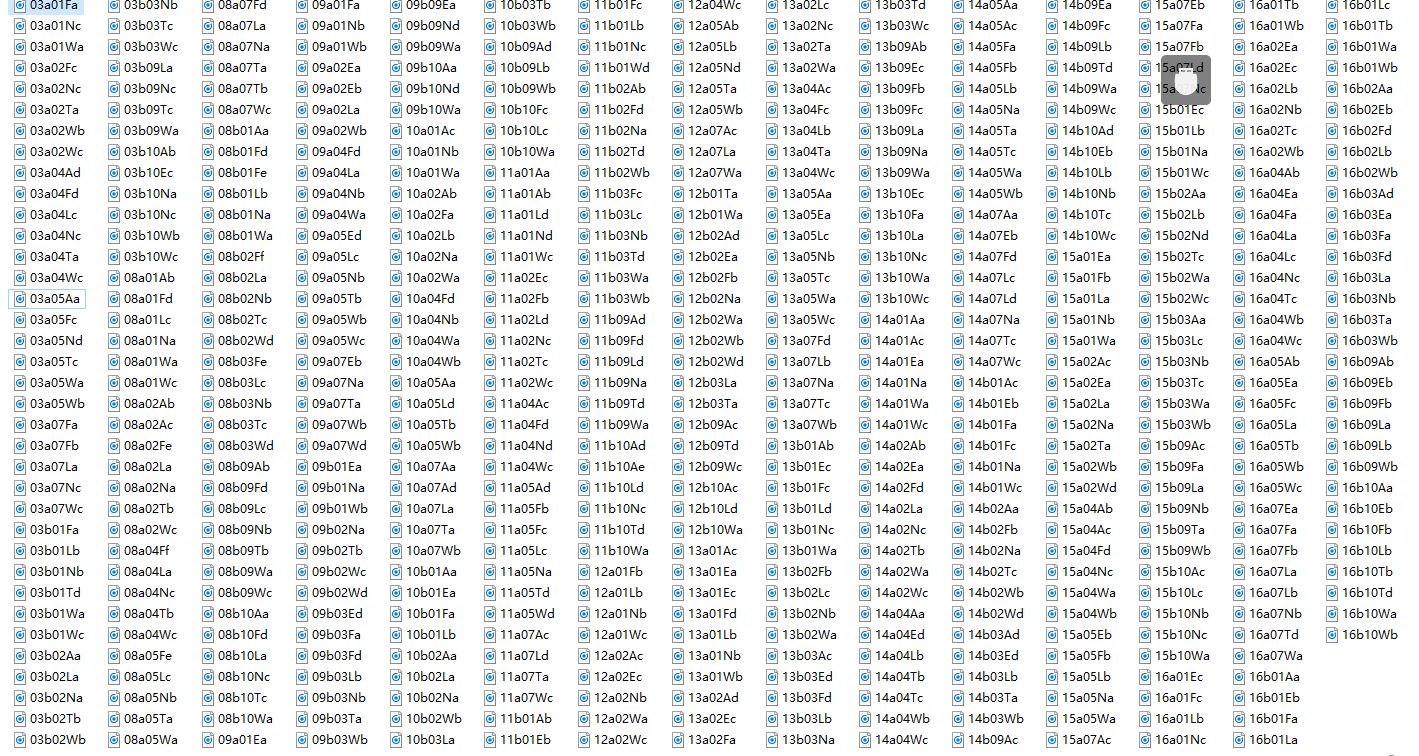
原始数据是按照下图所示命名的:
可以看到,排序会以演员名进行,而我需要它以情感种类进行排序,这样才方便后续处理。
python代码如下:
import os
path = "C:\Users\machuanli\Desktop\download\wav";
j = 0 ;
prename = {};
newname = {};
srcfiles = os.listdir(path);
os.chdir(path);
#os.rename('readme.txt','gotoyou.txt')
for i in xrange(535):
prename = srcfiles[i];
if prename[5] == 'N':
newname = 'neutral_' + prename;
if prename[5] == 'W':
newname = 'anger_' + prename;
if prename[5] == 'L':
newname = 'boredom_' + prename;
if prename[5] == 'E':
newname = 'disgust_' + prename;
if prename[5] == 'A':
newname = 'fear_' + prename;
if prename[5] == 'F':
newname = 'happiness_' + prename;
if prename[5] == 'T':
newname = 'sadness_' + prename;
os.rename(prename,newname);
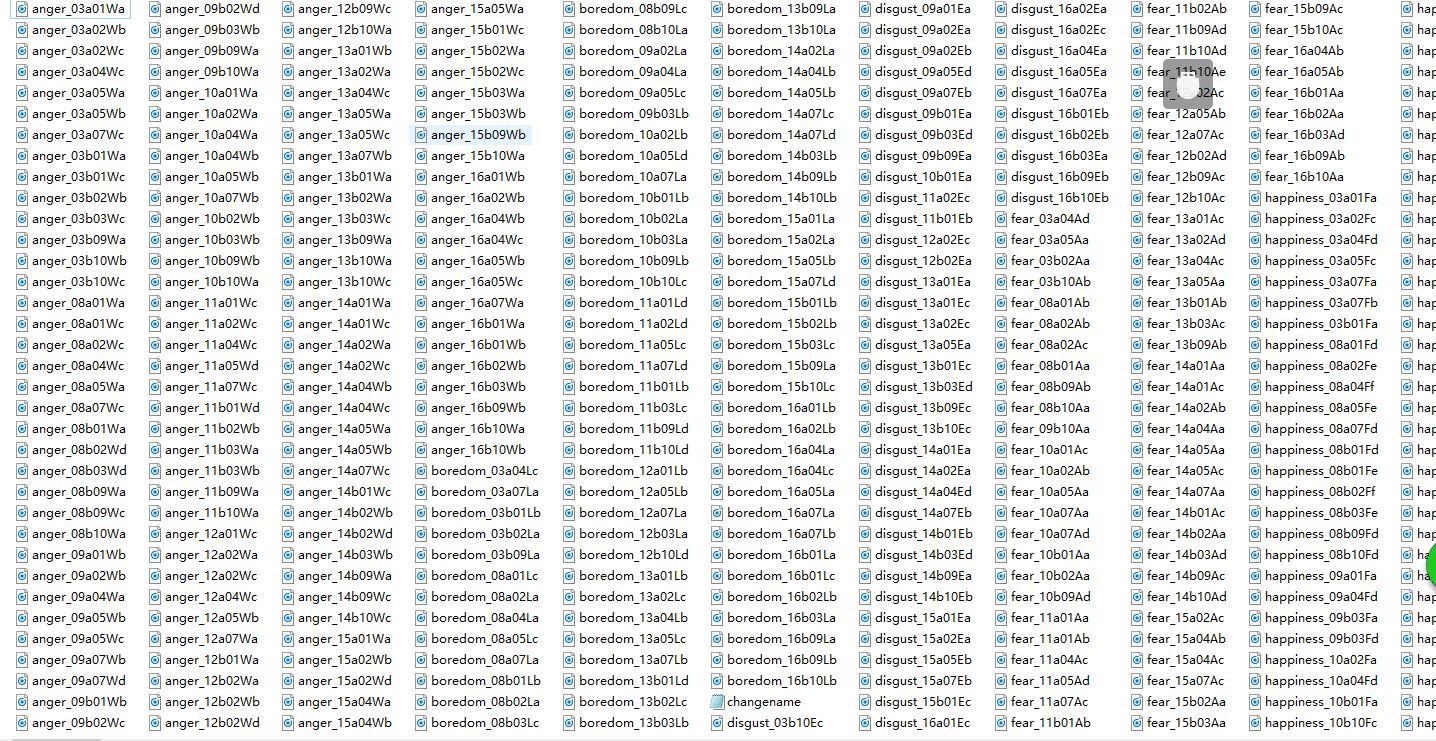
print 'successfully!'如上所示,需要的功能是实现了,但是代码极其粗糙,而且运行一次之后就会报错WindowsError。
修改后:
【回头一看,当年很菜】
2017.06.26补充:
原来的柏林情感语音数据库好像已经不提供下载服务了。我将Emo-DB 535段语音的那个版本放在百度云盘了,下载链接如下:
链接:http://pan.baidu.com/s/1mit7Rle 密码:t92c















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









