






如果要保存一些数据类型相同的变量,比如n个int类型的变量,就可以存放在一个数组中,然后通过下标方便的访问。可是数组的缺点也比较多,第一个就是在声明数组的时候,数组的长度必须是明确的,即便是动态声明一个数组,处理器必须要知道长度才能在内存中找出一段连续的内存来保存你的变量。第二个缺点也就是上一句中说到的,数组在内存中的地址必须是连续的,这样就可以通过数组首地址再根据下标求出偏移量,快速访问数组中的内容。现在计算机内存越来越大,这也算不上什么缺点。第三个缺点,也是非常难以克服的缺点,就是在数组中插入一个元素是非常费劲的。比如一个长度为n的数组,你要在数组下标为0处插入一个元素,在不额外申请内存的情况下,就需要把数组中的元素全部后移一位,还要舍弃末尾元素,这个时间开销是很大的,时间复杂度为o(n)。
数组的改良版本就是vector向量,它很好的克服了数组长度固定的缺点,vector的长度是可以动态增加的。如果明白向量的内部实现原理,那么我们知道,vector的内部实现还是数组,只不过在元素数量超过vector长度时,会按乘法或者指数增长的原则,申请一段更大的内存,将原先的数据复制过去,然后释放掉原先的内存。
如果你的数据不需要在数组中进行插入操作,那么数组就是个很好的选择,如果你的元素数组是动态增长的,那么vector就可以满足。
链表很好的克服了数组的缺点,它在内存中不需要连续的内存,插入或者删除操作o(1)时间复杂度就能解决,长度也是动态增长。如果你的元素需要频繁的进行插入、删除操作,那么链表就是个很好的选择。下图是数组和链表在内存中的组织形式
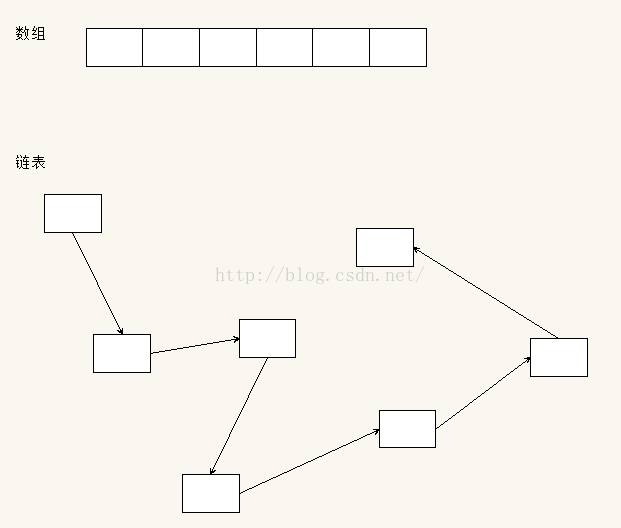
可以看到数组在内存中是连续的,用起始地址加上偏移地址就可以直接取出其中的元素,起始地址就是数组名,偏移地址就是数组的下标index*sizeof(t),t就是数组的类型。
但是链表在内存中是不连续,为什么叫链表,就是感觉像是用链子把一个个节点串起来的。那么一个个节点是怎么串接起来的呢,就是指针,每一个节点(末尾节点除外)都包含了指向下一个节点的指针,也就是说指针中保存着下一个节点的首地址,这样,1号节点知道2号节点保存在什么地址,2号节点知道3号节点保存在什么地址...以此类推。就像现实中寻宝一样,你只知道1号藏宝点,所以你先到达1号藏宝点,1号藏宝点你会得到2号藏宝点的地址,然后你再到达2号藏宝点...直到你找到了你需要的宝藏。链表的遍历就是用这种原理。
链表已经超出了基本数据类型的范围,所以要使用链表,要么使用STL库,要么自己用基本数据类型实现一个链表。如果是编程中正常的使用,当然是推荐前者,如果想真正搞懂链表这个数据结构,还是推荐后者。那样不仅知道标准库提供的API,也知道这种数据结构内部 的实现原理。这样的一个好处就是在你编程的时候,尤其是对时间空间复杂度比较敏感的程序,你可以根据要求选择一种最适合的数据结构,提高程序运行的效率。
一个个节点按顺序串接起来,就构成了链表。显然这一个个节点是很关键的,假设我们要构造一个int类型的链表,那么一个节点中就需要包含两个元素,一个是当前节点所保存的值,设为int value。另一个就是指向下一个节点的指针,我们再假设这个节点类是node,那么这个指针就是 node *next。这里一定不是int *next。因为这个指针指向的下一个元素是一个类的实例,而不是int类型的数据。那么node这个类最简单的实现就如下
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};拿到这个类以后,假设我们生成两个这个类的实例,node1和node2,再将node1的next指针指向node2,就构成了有两个元素的链表。这样如果我们拿到node1这个节点,就可以通过next指针访问node2。比如下面的代码
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node node1,node2;
node1.value = 1;
node2.value = 2;
node1.next = &node2;
cout << (node1.next)->value << endl;
}将刚刚的代码稍作修改
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node node1,node2;
node1.value = 1;
node2.value = 2;
node1.next = &node2;
cout << sizeof(node) << endl;
cout << &node1 << endl;
cout << &node2 << endl;
}输出是这样的
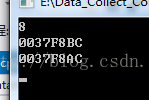
这样我们就可以根据输出画出它们在内存中的非常详细结构图
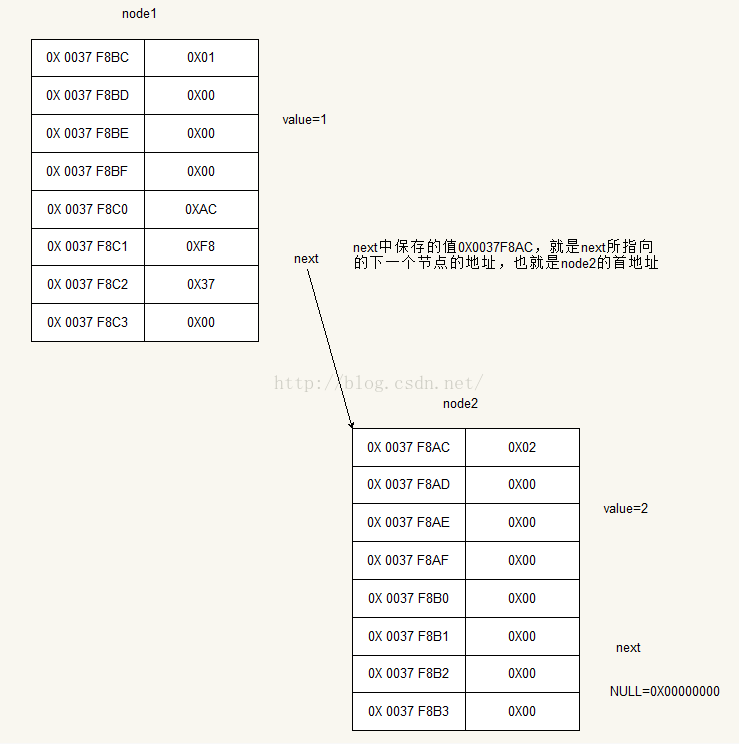
这样就构成了一个最简单的链表,如果还有新的节点出现,那么就如法炮制,链在表尾或者表头,当然插在中间也是没问题的。
但是这样还有个问题就是node1和node2是我们提前声明好的,而且知道这两个实例的名称,如果我们需要1000甚至跟多节点,这种方式显然是不科学的,而且在很多时候,我们都是动态生成一个类的实例,返回的是这个实例的首地址。下面的代码我们用一个for循环,生成11个节点,串起来形成一个链表
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node *head,*curr;
head = new node();
head->next = NULL;
head->value = 15;
for (size_t i = 0; i < 10; i++)
{
curr = new node();
curr->value = i;
curr->next = head;
head = curr;
}
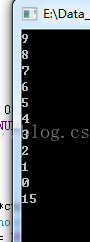
cout << head->value << endl;
}那么链表该如何遍历呢,刚开头的时候就说,遍历链表需要从头到尾,访问每一个元素,直到链表尾。也就是说不断地访问当前节点的next,直到NULL。下面是链表的遍历输出
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node *head,*curr;
head = new node();
head->next = NULL;
head->value = 15;
for (size_t i = 0; i < 10; i++)
{
curr = new node();
curr->value = i;
curr->next = head;
head = curr;
}
while (head!=NULL)
{
cout << head->value << endl;
head = head->next;
}
}
链表相对于数组有个非常明显的优点就是能以时间复杂度o(1)完成一个节点的插入或者删除操作。
插入操作的原理很简单,假设现在有三个节点,一个是当前节点curr,一个是当前节点的下一个节点,也就是后继节点,假设为next,还有一个待插入的节点,假设为insert。插入操作就是让当前节点的后继节点指向insert节点,insert节点的后继节点指向next节点。以下是示意图
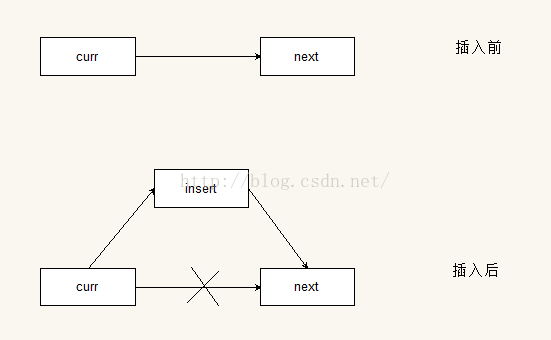
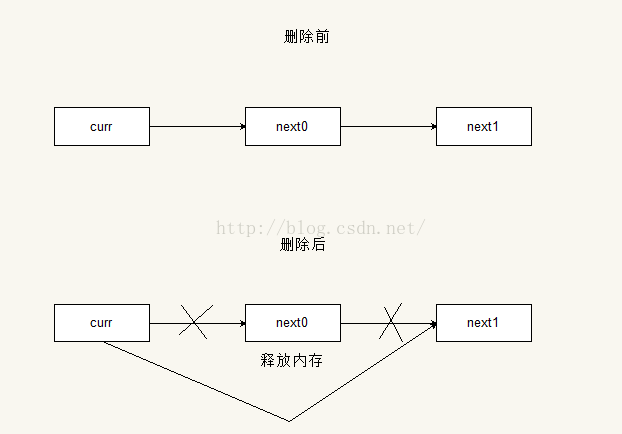
删除操作的原理也是类似的,就是让当前节点的后继节点指向它后继节点的后继节点。示意图如下
那么插入和删除操作用代码如何实现呢,我们还有原先的链表,先插入一个值为20的节点,输出链表的全部元素。然后再删除链表中这个值为20的元素,输出元素的全部内容。代码如下
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node *head=NULL,
*curr=NULL, //当前节点
*insert=NULL, //插入节点
*next=NULL, //后继节点
*pre=NULL; //前驱节点
head = new node();
head->next = NULL;
head->value = 15;
for (size_t i = 0; i < 10; i++)
{
curr = new node();
curr->value = i;
curr->next = head;
head = curr;
}
curr = head; //取出头结点
while (curr->value != 5)
{
curr = curr->next;
}
//找到值为5的节点
next = curr->next; //找到值为5的节点的后继节点
insert = new node(); //生成一个新的节点,值为20
insert->value = 20;
curr->next = insert; //当前节点的后继节点为插入节点
insert->next = next; //插入节点的后继节点为值为5的节点的后继节点
curr = head; //遍历链表,输出每一个元素
while (curr!=NULL)
{
cout << curr->value<<endl;
curr = curr->next;
}
curr = head; //找到头结点
while (curr->value!=20)
{
pre = curr;
curr = curr->next;
}
//找到值为20的节点,注意现在是单向链表,每个节点中不保存它的前驱节点,所以在遍历的过程中要人为保存一下前驱节点
next = curr->next; //找到当前节点的后继节点(当前节点就是值为20的节点)
pre->next = next; //当前节点的前驱节点的后继节点为当前节点的后继节点
delete curr; //删除当前节点
curr = head; //遍历这个链表输出每个元素
while (curr != NULL)
{
cout << curr->value << endl;
curr = curr->next;
}
while (true)
{
}
}输出如下:
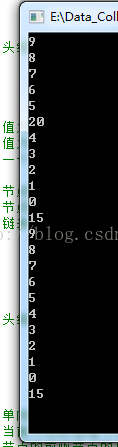
至于完整的链表,STL中有标准的库,也有功能非常全面的API,只要我们知道内部的实现原理,调用这些API是非常简单的事,用起来也会得心应手。














 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









