









知乎来源:https://zhuanlan.zhihu.com/p/27539515
作为新入DL的新手,前段时间突然在翻看论文的时候翻到了CycGAN,觉得很是眼前一亮呀——训练一个风格转换器,不需要打label,甚至都不需要把训练数据进行配对,满满的幸福感。
最先我是看到的CycleGAN,但是后续发现DiscoGAN与DualGAN论文似乎并无太大差别,他们的idea其实都是差不多的,模型本身答题结构也是相同的(嗯除了Generator和Discriminator的选用不同)。这里就很简单地介绍一下它们吧。
传统的GAN
当我们要训练一个深度学习模型的时候,少不了一个有效的评价指标,或者损失函数,它既能判断模型训练得好不好,又能够在反向传播时给出梯度帮助训练。
但是如果我们要训练的模型产生的结果是个图片,总不可能叫个人坐着给它打分对吧?不然一轮训练下来速度最慢的可能就是打分员了。于是有这么个想法诞生了:我们再训练一个网络,让它来给结果打分,这样就可以不需要打分员啦。传统的GAN就是为了解决这个问题而存在的。
传统的单向GAN长得什么样呢?
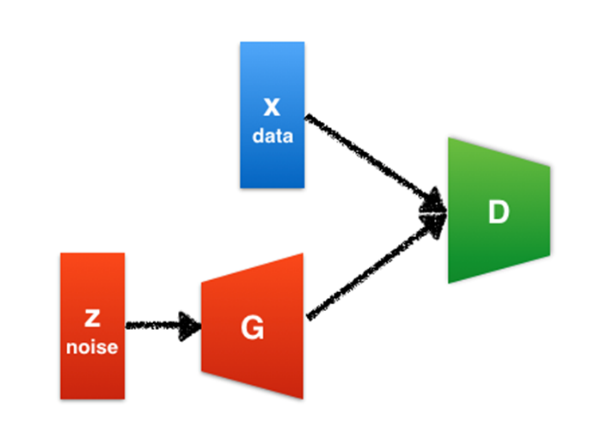 z作为信号源(往往是随机源),送数据给生成器G,处理后作为一张图片G(z)。我们的目标是让G(z)尽量像是真的一样,所以呢我们训练一个鉴别器D,同时给很多真实图片作参考,对于真实图片x,尽可能地让D(x) = 1;对于生成图片G(z),尽可能让D(z) = 0。
z作为信号源(往往是随机源),送数据给生成器G,处理后作为一张图片G(z)。我们的目标是让G(z)尽量像是真的一样,所以呢我们训练一个鉴别器D,同时给很多真实图片作参考,对于真实图片x,尽可能地让D(x) = 1;对于生成图片G(z),尽可能让D(z) = 0。
这里的D也就充当了打分员的角色,而任务呢就是鉴别图片到底是真实数据(1)还是生成器这个骗子造出来的赝品数据(0)。G呢则是造假贩子,它的目标就是让自己造出来的赝作不能被D分辨出来,让D认为D(G(z)) = 1。
这就有意思了:D和G的目标是相反的,他们仿佛是在打架一般,这就是GAN里的Adversarial,对抗一词的意义。
训练的时候,我们用每个batch轮流训练D和G,大致步骤如下:
1. 从X里掏出一张真图片real
2. 让G产生一个假图片fake
3. 拿这两张图片训练D,目标为D(real) = 1,D(fake) = 0
4. 拿这个D来训练G(此时固定住D的参数不让其参与训练修改),目标是D(G(z)) = 1
当然,这里还没说到损失函数。D的损失函数就按照习惯来就好啦(当然各种场景下各种损失函数会有训练效果上的差别,暂且不表)
例如我们用对数损失来表示D的损失函数
那么G的损失函数则可以表示成
细一点点看看生成器——风格转换
上面所说的生成器是根据一个随机数据来生成图片的。每次产生的随机的z,某种意义上是一个只有我们的G才懂的特殊编码,它决定了结果要如何表示。
那么,如果需要做图片风格转换,再用随机数做编码源是不是太不负责任了?生成结果会与原图毫无关联欸!
怎么办呢?也简单,让G不再从随机源生成图片,而是从我们给定的图片数据读入这个特殊编码。当然,为了把图片变成编码再生成图片,我们需要把单纯从随机数产生图片的生成器变为能够从现实数据提取特征编码的编码器,图片特征转换用的特征转换器,以及从特征编码恢复图片的解码器。
之前学习CNN的时候有了解到,卷积层(Convolution Layer)能够从原本图片里不断分离高阶特征,转置卷积层(Transpose Convolution Layer)能够反过来根据特征合成图片。
简单的想法就是,利用若干个卷积层构建编码器,若干个转置卷积层构建解码器,然后两者之间用一个能够产生变化的深度网络来担当特征转换器。(事实上DiscoGAN、CycleGAN、DualGAN三者的最大区别之一便在这里,DiscoGAN使用最简单直白的CNN编码器和解码器,使用全连接网络当转换器;CycleGAN则使用了ResNet充当转换器;DualGAN则是使用类似WGAN的形式来表示。)
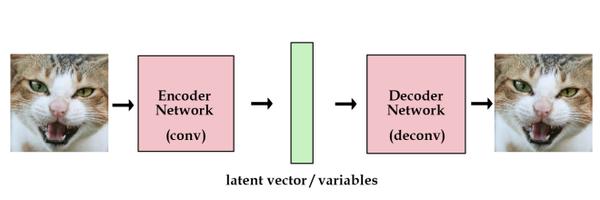 这样就能实现风格的变换了。到这里,GAN的损失函数可以写成
这样就能实现风格的变换了。到这里,GAN的损失函数可以写成
仍然与D的损失相反
那么怎么做到无配对?
无配对数据是指训练时并不是每一张风格X的图片都有一张对应的风格Y图片的意思,类似如下
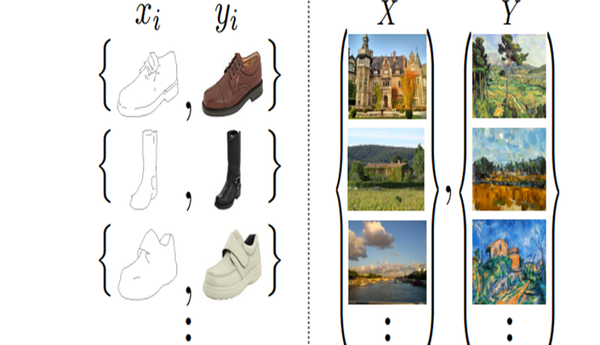 左边的时配对数据,而右边的表示无配对数据。更多的情况下,我们很容易搜集到两种风格的图片,但是很难采集到两个表示完全相同内容的两种风格的图片。
左边的时配对数据,而右边的表示无配对数据。更多的情况下,我们很容易搜集到两种风格的图片,但是很难采集到两个表示完全相同内容的两种风格的图片。
所以不配对的数据中训练网络,训练起来就没那么容易了:图片的配对相当于我们已经将特征过滤了一遍,GAN很容易学习到需要进行转换的部分;而非配对图片中,要么要大把的数据才能充分表明特征,要么训练出来的生成器搞不好就会把训练集里的奇怪的东西加到生成结果里。
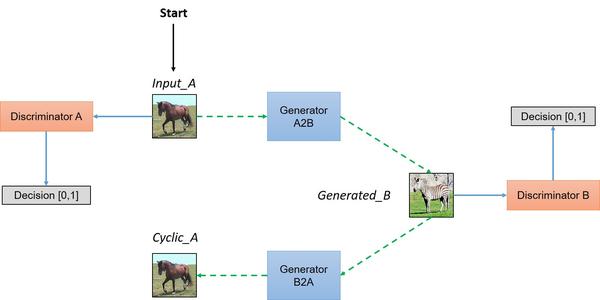
这样的对无配对数据的训练,就需要添加更多的约束条件。CycleGAN就建立在如下基础上:
如果我们同时训练两个GAN,其中一个是生成器鉴别器
,另一个是
,
,那么一张A类型的图片x,通过两次变换,应该能变回自己;B类型图片y同理,即:
只要针对这个设计一个损失函数,作为G的添加,并且轮流训练两个GAN就好了。图片对比的损失函数很容易表示:两图之间的一阶或者二阶距离都行。就拿一阶做例子吧
这个叫做循环损失,将成为总损失函数的一个组成部分。
形象一点的训练流程就直接看图
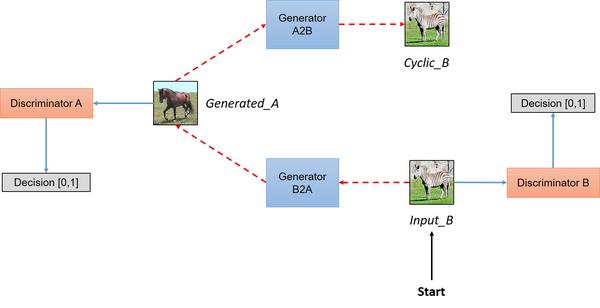
效果如何?
就目前来看,还在调参优化以及试用各种生成器和判别器结构。
下面引用原话:
如果是用Keras或者Chainer写的话其实挺容易写的,用TensorFlow会麻烦点儿。
训练过程中,能够清楚地看到两个G与两个D之间的损失函数的对抗性变化很明显,但是训练速度挺慢的……即使是DualGAN这样利用WGAN的基本生成器结构的,训练速度也明显低于单向有配对GAN,batch size为1的情况下,每个epoch训1000张图,差不多要近100个epoch才能得到比较能够接受的结果。
顺带一提,很多人喜欢的在复杂网络里用Adam这样带自适应调整学习率的结构,不是很适合于训练GAN,也包括CycleGAN模型,特别是判别器。一开始只是发现现象,之后又回过头去细读WGAN的文章时才想明白道理。毕竟在GAN中,损失函数并不代表着训练进度,甚至不能代表结果优劣。
对比之下,比CoupleGAN之类的而言,不那么挑数据,略微好一些。原作者(也是那个Conditional Adversarial Network,折腾把随手画变成猫)的那个pix2pix项目产生数据能直接喂给CycleGAN训练,效果还挺赞。














 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









