









深度信念网络,DBN,Deep Belief Nets,神经网络的一种。既可以用于非监督学习,类似于一个自编码机;也可以用于监督学习,作为分类器来使用。
从非监督学习来讲,其目的是尽可能地保留原始特征的特点,同时降低特征的维度。从监督学习来讲,其目的在于使得分类错误率尽可能地小。而不论是监督学习还是非监督学习,DBN的本质都是Feature Learning的过程,即如何得到更好的特征表达。
作为神经网络,神经元自然是其必不可少的组成部分。DBN由若干层神经元构成,组成元件是受限玻尔兹曼机(RBM)。
首先来了解一下受限玻尔兹曼机(RBM):
RBM是一种神经感知器,由一个显层和一个隐层构成,显层与隐层的神经元之间为双向全连接。如下图所示:
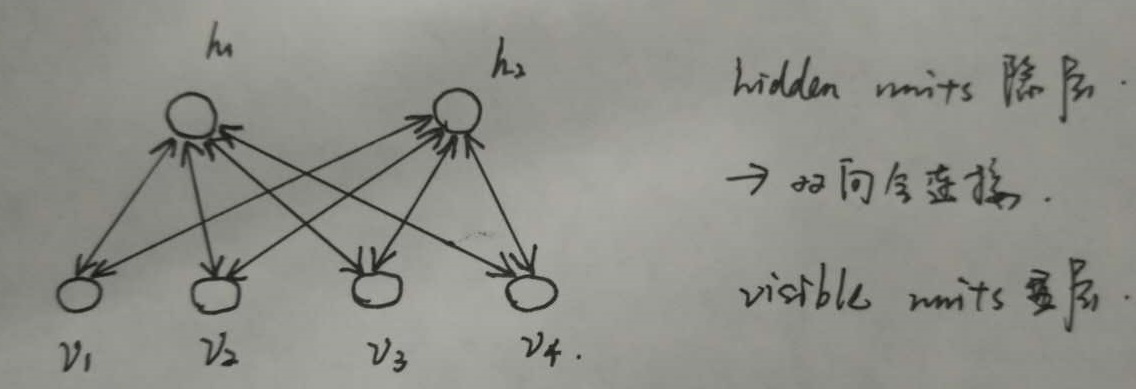
在RBM中,任意两个相连的神经元之间有一个权值w表示其连接强度,每个神经元自身有一个偏置系数b(对显层神经元)和c(对隐层神经元)来表示其自身权重。
这样,就可以用下面函数表示一个RBM的能量:
在一个RBM中,隐层神经元 hj 被激活的概率:
由于是双向连接,显层神经元同样能被隐层神经元激活:
其中, σ 为 Sigmoid 函数,也可以设定为其他函数。
值得注意的是,当 σ 为线性函数时,DBN和PCA(主成分分析)是等价的。
同一层神经元之间具有独立性,所以概率密度亦然满足独立性,故得到下式:
以上即为受限玻尔兹曼机(RBM)的基本构造。其结构并不复杂。下面来看看它的工作原理:
当一条数据(如向量
x
)赋给显层后,RBM根据(3)式计算出每个隐层神经元被开启的概率
P(hj|x),j=1,2,...,Nh
,取一个0-1的随机数
μ
作为阈值,大于该阈值的神经元则被激活,否则不被激活,即:
由此得到隐层的每个神经元是否被激活。
给定隐层时,显层的计算方法是一样的。
了解工作原理之后就可以看看RBM是如何通过数据学习的了:
RBM共有五个参数:h、v、b、c、W,其中b、c、W,也就是相应的权重和偏置值,是通过学习得到的。(v是输入向量,h是输出向量)
对于一条样本数据
x
,采用对比散度算法对其进行训练:
- 将 x 赋给显层 v1 ,利用(2)式计算出隐层中每个神经元被激活的概率 P(h1|v1) $;
- 从计算的概率分布中采取Gibbs抽样抽取一个样本:
h1∼P(h1|v1)
- 用 h1 重构显层,即通过隐层反推显层,利用(3)式计算显层中每个神经元被激活的概率 P(v2|h1) ;
- 同样地,从计算得到的概率分布中采取Gibbs抽样抽取一个样本:
v2∼P(v2|h1)
- 通过 v2 再次计算隐层中每个神经元被激活的概率,得到概率分布 P(h2|v2)
- 更新权重:
若干次训练后,隐层不仅能较为精准地显示显层的特征,同时还能够还原显层。当隐层神经元数量小于显层时,则会产生一种“数据压缩”的效果,也就类似于自动编码器。
深度置信网络(DBN):
将若干个RBM“串联”起来则构成了一个DBN,其中,上一个RBM的隐层即为下一个RBM的显层,上一个RBM的输出即为下一个RBM的输入。训练过程中,需要充分训练上一层的RBM后才能训练当前层的RBM,直至最后一层。
很多的情况下,DBN是作为无监督学习框架来使用的,并且在语音识别中取得了很好的效果。
若想将DBM改为监督学习,方式有很多,比如在每个RBM中加上表示类别的神经元,在最后一层加上softmax分类器。也可以将DBM训出的W看作是NN的pre-train,即在此基础上通过BP算法进行fine-tune。实际上,前向的算法即为原始的DBN算法,后项的更新算法则为BP算法,这里,BP算法可以是最原始的BP算法,也可以是自己设计的BP算法。
DBN的实现(DeepLeranToolBox):
这里是将DBN作为无监督学习框架来使用的,将“学习成果”赋给ANN来完成分类。
训练集是60000张28*28的手写数字图片,测试集是10000张28*28的手写数字图片,对应的单幅图片的特征维度为28*28=784
% function test_example_DBN
load mnist_uint8;
train_x = double(train_x) / 255;
test_x = double(test_x) / 255;
train_y = double(train_y);
test_y = double(test_y);
%% ex2 train a 100-100 hidden unit DBN and use its weights to initialize a NN
rand('state',0)
%train dbn
%对DBN的初始化
%除了输入层之外有两层,每层100个神经元,即为两个受限玻尔兹曼机
dbn.sizes = [100 100];
%训练次数
opts.numepochs = 2;
%每次随机的样本数量
opts.batchsize = 100;
%更新方向,目前不知道有什么用
opts.momentum = 0;
%学习速率
opts.alpha = 1;
%建立DBN
dbn = dbnsetup(dbn, train_x, opts);
%训练DBN
dbn = dbntrain(dbn, train_x, opts);
%至此,已完成了DBN的训练
%unfold dbn to nn
%将DBN训练得到的数据转化为NN的形式
nn = dbnunfoldtonn(dbn, 10);
%设置NN的阈值函数为Sigmoid函数
nn.activation_function = 'sigm';
%train nn
%训练NN
opts.numepochs = 3;
opts.batchsize = 100;
nn = nntrain(nn, train_x, train_y, opts);
[er, bad] = nntest(nn, test_x, test_y);
assert(er < 0.10, 'Too big error');function dbn = dbnsetup(dbn, x, opts)
%n是单个样本的特征维度,784
n = size(x, 2);
%dbn.sizes是rbm的维度,[784 100 100]
dbn.sizes = [n, dbn.sizes];
%numel(dbn.sizes)返回dbn.sizes中的元素个数,对于[784 100 100],则为3
%初始化每个rbm
for u = 1 : numel(dbn.sizes) - 1
%初始化rbm的学习速率
dbn.rbm{u}.alpha = opts.alpha;
%学习方向
dbn.rbm{u}.momentum = opts.momentum;
%第一个rbm是784-100, 第二个rbm是100-100
%对应的连接权重,初始值全为0
dbn.rbm{u}.W = zeros(dbn.sizes(u + 1), dbn.sizes(u));
%用于更新的权重,下同,不再注释
dbn.rbm{u}.vW = zeros(dbn.sizes(u + 1), dbn.sizes(u));
%第一个rbm是784,第二个rbm是100
%显层的偏置值,初始值全为0
dbn.rbm{u}.b = zeros(dbn.sizes(u), 1);
dbn.rbm{u}.vb = zeros(dbn.sizes(u), 1);
%第一个rbm是100,第二个rbm是100
%隐层的偏置值,初始值全为0
dbn.rbm{u}.c = zeros(dbn.sizes(u + 1), 1);
dbn.rbm{u}.vc = zeros(dbn.sizes(u + 1), 1);
end
endfunction dbn = dbntrain(dbn, x, opts) % n = 1; % x = train_x,60000个样本,每个维度为784,即60000*784 %n为dbn中有几个rbm,这里n=2 n = numel(dbn.rbm); %充分训练第一个rbm dbn.rbm{1} = rbmtrain(dbn.rbm{1}, x, opts); %通过第一个rbm,依次训练后续的rbm for i = 2 : n %建立rbm x = rbmup(dbn.rbm{i - 1}, x); %训练rbm dbn.rbm{i} = rbmtrain(dbn.rbm{i}, x, opts);function rbm = rbmtrain(rbm, x, opts) %矩阵x中的元素必须是浮点数,且取值为[0,1] assert(isfloat(x), 'x must be a float'); assert(all(x(:)>=0) && all(x(:)<=1), 'all data in x must be in [0:1]'); %m为样本数量,这里m = 60000 m = size(x, 1); %训练批次,每一批是opts.batchsize个样本,注意这里opts.batchsize必须整除m numbatches = m / opts.batchsize; %opts.batchsize必须能整除m assert(rem(numbatches, 1) == 0, 'numbatches not integer'); %opts.numepochs,训练次数 for i = 1 : opts.numepochs %随机打乱1-m的数,也就是1-m的随机数,kk是1-m的随机数向量 kk = randperm(m); %训练结果的eer err = 0; %对每一批数据进行训练 for l = 1 : numbatches %取出opts.batchsize个待训练的样本 %循环结束后所有样本都进行过训练,且仅训练了一次 batch = x(kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize), :); %赋值给v1 %这里v1是100*784的矩阵 v1 = batch; %通过v1计算h1的概率,吉布斯抽样 h1 = sigmrnd(repmat(rbm.c', opts.batchsize, 1) + v1 * rbm.W'); %通过h1计算v1的概率,吉布斯抽样 v2 = sigmrnd(repmat(rbm.b', opts.batchsize, 1) + h1 * rbm.W); %通过v2计算h2的概率,吉布斯抽样 h2 = sigm(repmat(rbm.c', opts.batchsize, 1) + v2 * rbm.W'); %至此,h1,v1,h2,v2均已计算出来,即完成了对比散度算法的大半,只剩下相应权重的更新 %权重更新的差值计算 c1 = h1' * v1; c2 = h2' * v2; rbm.vW = rbm.momentum * rbm.vW + rbm.alpha * (c1 - c2) / opts.batchsize; rbm.vb = rbm.momentum * rbm.vb + rbm.alpha * sum(v1 - v2)' / opts.batchsize; rbm.vc = rbm.momentum * rbm.vc + rbm.alpha * sum(h1 - h2)' / opts.batchsize; %更新权重 rbm.W = rbm.W + rbm.vW; rbm.b = rbm.b + rbm.vb; rbm.c = rbm.c + rbm.vc; %计算err err = err + sum(sum((v1 - v2) .^ 2)) / opts.batchsize; end %打印结果 disp(['epoch ' num2str(i) '/' num2str(opts.numepochs) '. Average reconstruction error is: ' num2str(err / numbatches)]); end end
endendfunction x = rbmup(rbm, x) %sigm为sigmoid函数 %通过隐层计算下一层 x = sigm(repmat(rbm.c', size(x, 1), 1) + x * rbm.W'); end
对于手写数字的识别结果还是很好的,即便是最简单的DBN+NN(如上参数设置),也可以达到95%的正确率。
必备知识来源文章:
DBN文章:
1. A Fast Learning Algorithm for Deep Belief Nets
2. The wake-sleep algorithm for unsupervised neural networks
DBN demo:Convolutional Deep Belief Networks
来源:















 7937
7937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









