







接着上一篇文章,剩下的那几个功能未完成,在这片文章中我们通过CrawlSpider来完善它
一、CrawlSpider简介
CrawlSpider是一个比较有用的组件,其通过正则表达匹配对应url并爬取,通过Xpath解析网页内容,再在新页面抽取url继续爬取。CrawlSpider派生自InitSpider派生自BaseSpider(最基本爬虫组件).CrawlSpider主要通过Rule类进行正则表达式的设定,设定相应的回调函数等
1.Rule类如下
class Rule(object):
def __init__(self, link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None):
self.link_extractor = link_extractor
self.callback = callback
self.cb_kwargs = cb_kwargs or {}
self.process_links = process_links
if follow is None:
self.follow = False if callback else True
else:
self.follow = follow参数:link_extractor 一个url抽取器对象,通过它设定正则,允许匹配什么类型的url,不匹配那些都可以通过它设定
callback 回调函数可传函数的对象 或者函数字符串表现形式,此回调函数主要处理抓取到的数据到Item对象
函数形式为:def 函数名(self,response[,**cb_kwargs])
cb_kwargs 回调函数参数 字典类型
follow 是否继续爬取,true 继续爬取,false 到此停止
process_link 是一个可选的回调函数,接受一个list参数(list元素是通过正则匹配返回url列表),此函数为什么
可选? 主要是处理例如:list 参数里元素url是相对路径,可通过此回调处理加上域名形成一个完整的URL。反正是对路径做一些附加处理。
2.CrawlSpider
CrawlSpider类通过parse函数解析response
def parse(self, response):
return self._response_downloaded(response, self.parse_start_url, cb_kwargs={}, follow=True)parse 函数调用 _response_downloaded函数并返回,返回类型必须是Item 或 Request 对象的列表,这是Scrapy 规定的。再看看_response_downloaded函数
def _response_downloaded(self, response, callback, cb_kwargs, follow):
if callback:
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
if follow and settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True):
for request_or_item in self._requests_to_follow(response):
yield request_or_item函数表达的意思为:
调用callback回调函数(如果callback实例函数有效),否则返回()空元组,callback返回的是item或Request对象list,一开始回调函数为parse_start_url 函数,如果不重写此函数相当于种子页面不处理。默认返回空list调用process_results函数,此函数可重写,如果不重写,返回的是callback返回值,接下来通过follow判断完成通过正则抽取的URL的爬取,此时调用_requests_to_follow 函数
def _requests_to_follow(self, response):
seen = set()
for rule in self._rules:
links = [l for l in rule.link_extractor.extract_links(response) if l not in seen]
if links and rule.process_links:
links = rule.process_links(links)
seen = seen.union(links)
for link in links:
r = Request(url=link.url)
r.meta['link_text'] = link.text
r.deferred.addCallback(self._response_downloaded, rule.callback, cb_kwargs=rule.cb_kwargs, follow=rule.follow)
yield r通过response参数传进当前页面信息,seen = set() 防止正则抽取到一样的路径,循环通过对rule对象设置进行正则抽取,并过滤重复的url,接着通过process_links函数(前面提到的URL加工函数)如果该函数对象实例存在。
通过links 列表循环调用Request对象进行进一步抓取。通过ddCallback(self._response_downloaded, rule.callback, cb_kwargs=rule.cb_kwargs, follow=rule.follow) 设回调,self._response_downloaded为回调函数。
3.LinkExtractor
(1)概念:
顾名思义,链接提取器。
(2) 作用:
response对象中获取链接,并且该链接会被接下来爬取。
(3) 使用:
通过SmglLinkExtractor提取希望获取的链接。
classscrapy.contrib.linkextractors.sgml.SgmlLinkExtractor(
allow=(),
deny=(),
allow_domains=(),
deny_domains=(),
deny_extensions=None,
restrict_xpaths=(),
tags=('a','area'),
attrs=('href'),
canonicalize=True,
unique=True,
process_value=None
) 主要参数:
allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
deny:与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取。
allow_domains:会被提取的链接的domains。
deny_domains:一定不会被提取链接的domains。
restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。
列:
# follow = True表示会在返回的url中继续寻找符合条件的url
Rule(LinkExtractor(allow='^https://movie\.douban\.com/subject/\d+/reviews$',restrict_xpaths=('//div[@class="review-more"]/a')),follow = True),
# callback='parse_content'表示导出的页面由parse_content()函数进行处理。
Rule(LinkExtractor(allow='^https://movie\.douban\.com/subject/\d+/reviews.*',restrict_xpaths=('//div[@id="paginator"]/a')),callback='parse_content', follow = True))
二、创建Scrapy项目
scrapy startproject douban_book创建好项目之后,通过genspider创建CrawlSpider爬虫模板:
scrapy genspider -t crawl bookspider douban.com
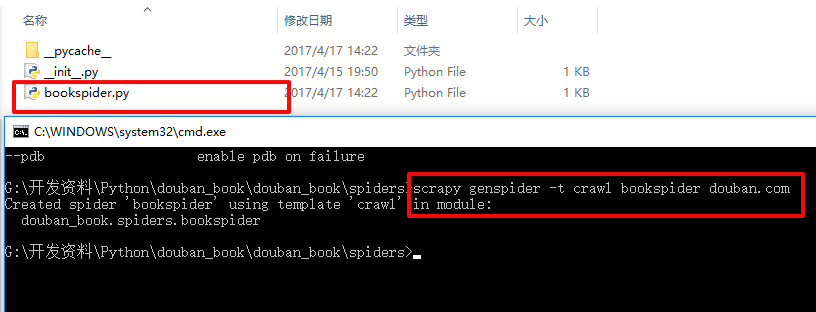
查看它的源码,可以发现它传进来的是CrawlSpider,而不是以前的scrapy.Spider!!
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class BookspiderSpider(CrawlSpider):
name = 'bookspider'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i三、定义items
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanBookItem(scrapy.Item):
""" 定义需要抓取的字段名 """
name = scrapy.Field() # 书名
images = scrapy.Field() # 图片
author = scrapy.Field() # 作者
press = scrapy.Field() # 出版社
date = scrapy.Field() # 出版日期
page = scrapy.Field() # 页数
price = scrapy.Field() # 价格
score = scrapy.Field() # 读者评分
ISBN = scrapy.Field() # ISBN号
author_profile = scrapy.Field() # 作者简介
content_description = scrapy.Field() # 内容简介
link = scrapy.Field() # 详情页链接四、定义爬虫Spider
1、列表页翻页规律
第一页:https://book.douban.com/tag/心理学?start=0&type=T
第二页:https://book.douban.com/tag/心理学?start=20&type=T
第三页:https://book.douban.com/tag/心理学?start=40&type=T
会发现start后面的数字是有规律递增的,知道这个就好办了,于是用于翻页的url正则表达式我们可以这样写:
r "https://book.douban.com/tag/心理学\?start=\d+&type=T"注:Python中 r 表示的是原始字符的意思
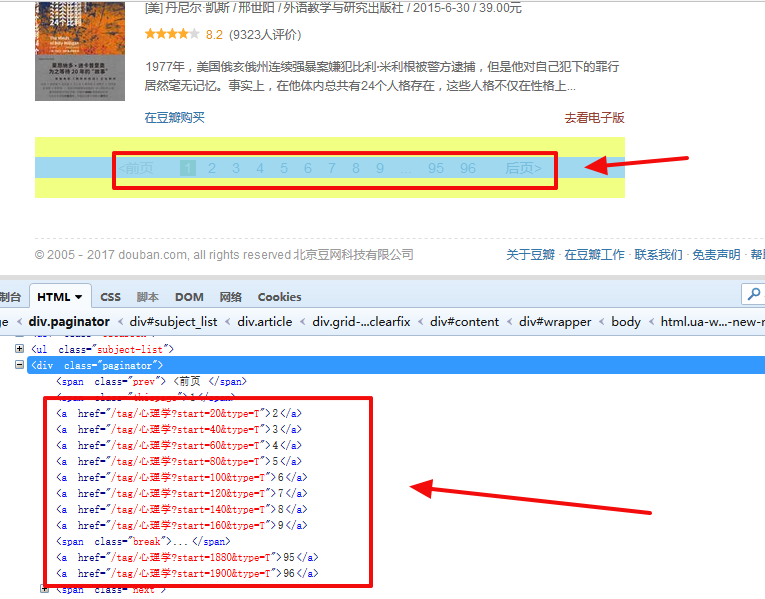
2、列表页的html源码分析
会发现每一本书的详情页链接都类似,只是后面的一串数字不同而已
https://book.douban.com/subject/26805083/
我们可以得出在列表页中查找图书详情页ulr的正则表达式了
r "http://book.douban.com/subject/\d+/$"
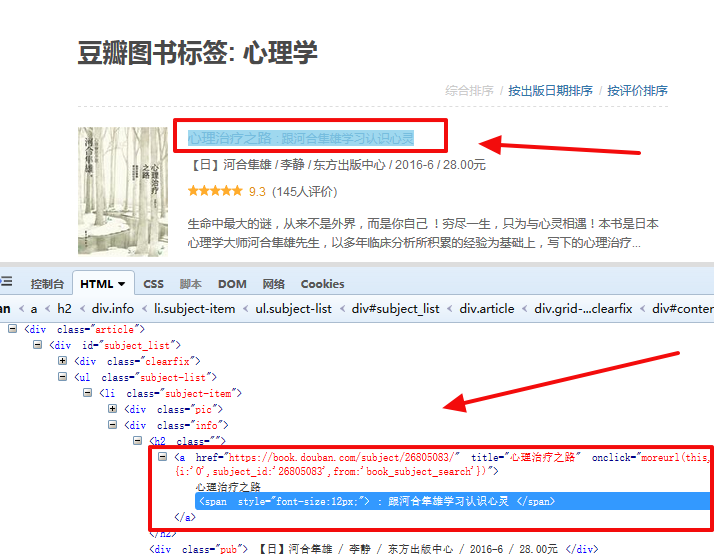
3、书籍详情页html源码分析
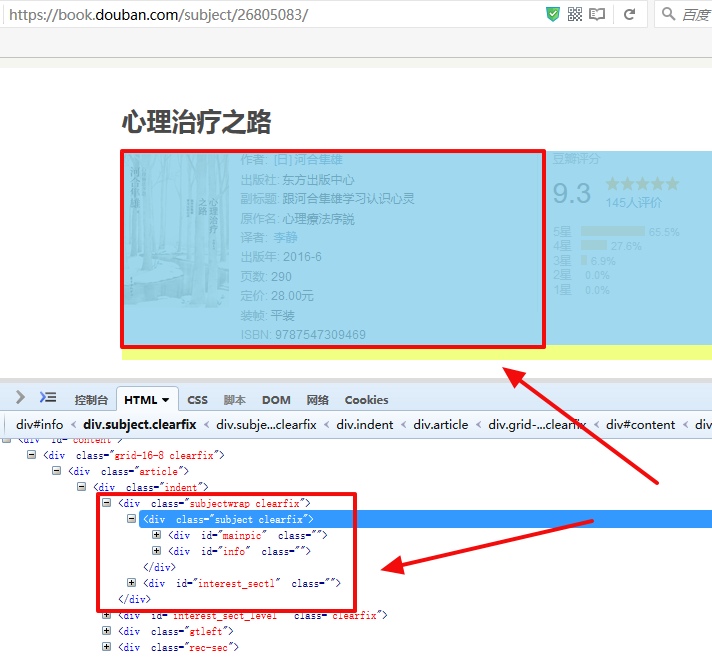
我们可以在终端中用以下命令来进行debug,验证我们spider中的代码是否准确无误抓取到了我们想要的字段:
C:\Users\fendo>scrapy shell "https://book.douban.com/subject/26805083/" --nolog
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x000002C363CFAD68>
[s] item {}
[s] request <GET https://book.douban.com/subject/26805083/>
[s] response <200 https://book.douban.com/subject/26805083/>
[s] settings <scrapy.settings.Settings object at 0x000002C366107B38>
[s] spider <DefaultSpider 'default' at 0x2c36638d208>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]:1.图书名
In [1]: response.xpath("//div[@id='wrapper']/h1/span/text()").extract()[0].strip()
Out[1]: '心理治疗之路'2.读者评分
In [7]: response.xpath("//div[@class='rating_self clearfix']/strong/text()").extract()[0].strip()
Out[7]: '9.3'
In [8]: response.url
Out[8]: 'https://book.douban.com/subject/26805083/'
4.书籍图片
In [1]: response.xpath("//div[@id='mainpic']/a/img/@src").extract()[0].strip()
Out[1]: 'https://img3.doubanio.com/lpic/s28852024.jpg5.作者,出版社,出版日期,页数,价格,ISBN号,作者简介,内容简介
下面的xpath表达式主要是获取书籍的基本信息

response.xpath("//div[@id='info']//text()").extract()
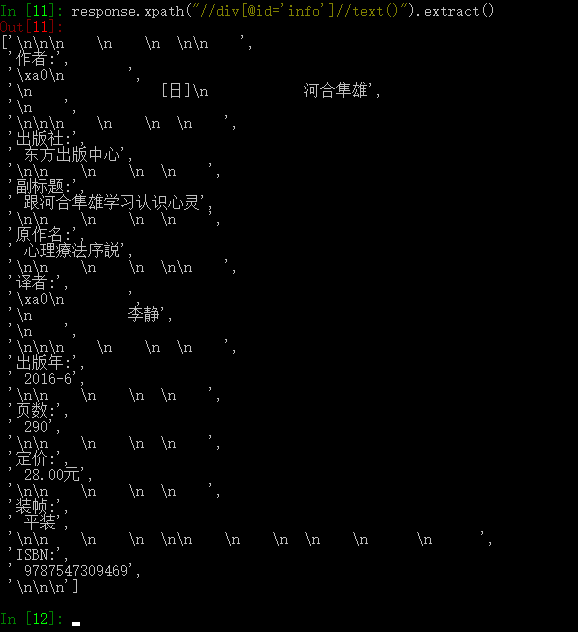
此时的数据里含有大量的换行符之类的,我们进行去除多余的换行符操作
datas = response.xpath("//div[@id='info']//text()").extract()
datas = [data.strip() for data in datas]
列表中还是含有空项,所以我们继续去除空的列表项
datas = [data for data in datas if data != ""]
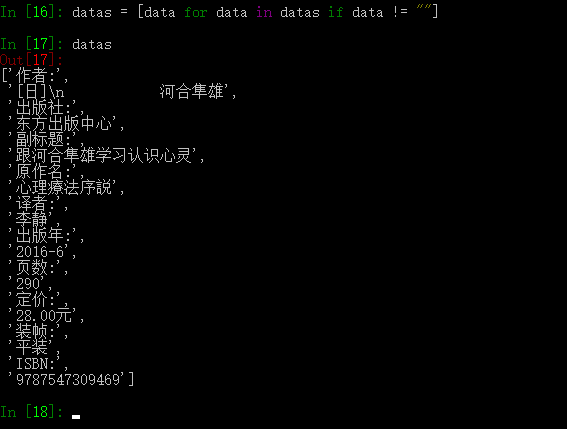
此时我们打印一下列表中的每一项看看
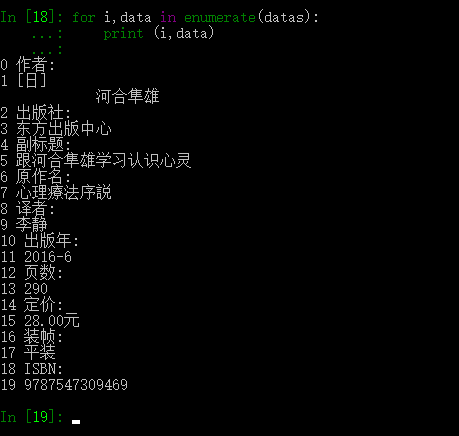
for i,data in enumerate(datas):
print (i,data)
完整的代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy.selector import Selector
from douban_book.items import DoubanBookItem
import re
import os
import urllib.request
from scrapy.http import HtmlResponse,Request
import time
class BookspiderSpider(CrawlSpider):
name = 'bookspider'
allowed_domains = ['book.douban.com']
start_urls = ['https://book.douban.com/tag/编程?start=0&type=T']
rules = (
# 列表页url
Rule(LinkExtractor(allow=(r"https://book.douban.com/tag/编程\?start=\d+&type=T"))),
# 详情页url
Rule(LinkExtractor(allow=(r"https://book.douban.com/subject/\d+/$")),callback="parse_item")
)
def parse_item(self, response):
if response.status == 200:
print ()
cks="编程"
#类别
cate=response.xpath("//div[@id='db-tags-section']/div/span/a/text()").extract()
if cks in cate:
sel = Selector(response)
item = DoubanBookItem()
# 图书名
item["name"] = sel.xpath("//div[@id='wrapper']/h1/span/text()").extract()[0].strip()
# 读者评分
item["score"] = sel.xpath("//div[@class='rating_self clearfix']/strong/text()").extract()[0].strip()
# 详情页链接
item["link"] = response.url
try:
# 内容简介
contents = sel.xpath("//div[@id='link-report']//div[@class='intro']")[-1].xpath(".//p//text()").extract()
item["content_description"] = "\n".join(content for content in contents)
except:
item["content_description"] = ""
try:
# 作者简介
profiles = sel.xpath("//div[@class='related_info']//div[@class='indent ']//div[@class='intro']")[-1].xpath(
".//p//text()").extract()
item["author_profile"] = "\n".join(profile for profile in profiles)
except:
item["author_profile"] = ""
src = sel.xpath("//div[@id='mainpic']/a/img/@src").extract()[0].strip()
print("images is url-----------------------------------------: " + src)
file_name = "%s.jpg" % (item["name"]) # 图书名
file_path = os.path.join("G:\\开发资料\\Python\\douban_book\\img", file_name) # 拼接这个图片的路径
print("file_name---****************************************-file_path---: " + file_name)
opener = urllib.request.build_opener()
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(src, file_path) # 接收文件路径和需要保存的路径,会自动去文件路径下载并保存到我们指定的本地路径
item["images"] = file_path
item["tags"] = "编程"
datas = response.xpath("//div[@id='info']//text()").extract()
datas = [data.strip() for data in datas]
datas = [data for data in datas if data != ""]
for i, data in enumerate(datas):
print ("index %d " % i, data)
for data in datas:
if u"作者" in data:
if u":" in data:
item["author"] = datas[datas.index(data) + 1]
elif u":" not in data:
item["author"] = datas[datas.index(data) + 2]
elif u"出版社:" in data:
item["press"] = datas[datas.index(data) + 1]
elif u"出版年:" in data:
item["date"] = datas[datas.index(data) + 1]
elif u"页数:" in data:
item["page"] = datas[datas.index(data) + 1]
elif u"定价:" in data:
item["price"] = datas[datas.index(data) + 1]
elif u"ISBN:" in data:
item["ISBN"] = datas[datas.index(data) + 1]
return item
五、Pipeline文件持久化数据
以下代码可以把抓取的到的数据存于json文件中也可以存于MySQL数据库中
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from scrapy import log
import pymysql as db
class DoubanBookPipeline(object):
""" 将抓取到的数据存入json文件中 """
def __init__(self):
self.file = open("./items.json", "wb")
def process_item(self, item, spider):
# 由于scrapy在spider中抓取的所有字段都会转换成unicode码
# 所以我们在存入json文件之前先将每一项都转换成utf8
# 不转的话,我们存入json文件中的数据也是unicode码,中文显示方式不是我们想要的
for k in item:
item[k] = item[k].encode("utf8")
print(item[k])
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
class MySQLPipeline(object):
def __init__(self):
self.con=db.connect(user="root",passwd="123",host="localhost",db="python",charset="utf8")
self.cur=self.con.cursor()
self.cur.execute('drop table douban_booke')
self.cur.execute("create table douban_booke(id int primary key auto_increment,tags varchar(50), name varchar(255) NOT NULL, author varchar(255) NULL, press varchar(100) NULL, date varchar(30) NULL, page varchar(50) NULL, price varchar(30) NULL, score varchar(30) NULL, ISBN varchar(30) NULL, author_profile varchar(1500) NULL, content_description varchar(3000) NULL, link varchar(255) NULL )default charset=utf8;")
def process_item(self, item, spider):
self.cur.execute("insert into douban_booke(tags, name, author, press, date, page, price, score, ISBN, author_profile,content_description, link) values (%s,%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)",(item["tags"], item["name"], item["author"], item["press"], item["date"],item["page"], item["price"], item["score"], item["ISBN"],item["author_profile"], item["content_description"], item["link"]))
self.con.commit()
return item在settings中配置下:
ITEM_PIPELINES = {
# 'douban_book.pipelines.DoubanBookPipeline': 300,
'douban_book.pipelines.MySQLPipeline': 2,
}并设置下防爬虫策略:
# 为防止被识别为爬虫,应设置下载页面的延时时间
DOWNLOAD_DELAY = 2
# 模拟浏览器头部
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
}运行效果如下:
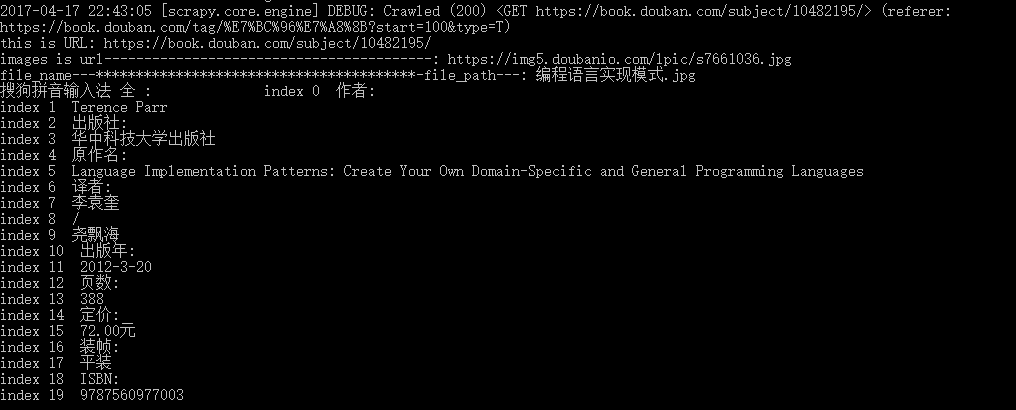
同时在img目录下生成图片
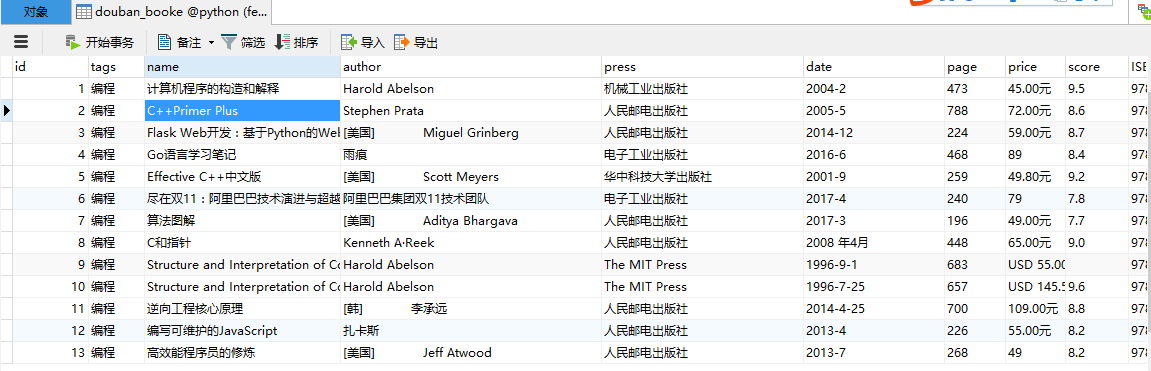
数据库中的数据














 1444
1444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









