







安装方法
pip install lxml
为什么要学习Xpath和LXML类库
lxml是一款高性能的Python HTML/XML解析器,我们可以利用Xpath来快速的定位特定的元素以及获取节点的信息
什么是Xpath
Xpath是一门在HTML/XML文档中查找信息的语言,可用来在HTML/XML文档中对元素和属性进行遍历
认识XML
| 数据格式 | 描述 | 设计目标 |
|---|---|---|
| XML | 可扩展标记语言 | 被设计为传输和存储数据,其焦点是数据的内容 |
| HTML | 超文本标记语言 | 显示数据以及如何更好显示 |
XML的节点关系
节点的概念:每个XML的标记我们都称之为节点
<book>
<title>hello world</title>
<author>Bigdata J</author>
<year>2020</year>
<book>
节点选择语法
Xpath使用路径表达式来选取XML文档中的接待或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
| 表达式 | 描述 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取 |
| and | 可以起到节点连接 |
查找某个特定的节点或者包含某个指定的值的节点
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属性bookstore子元素的第一个book元素 |
| /booksrtore/book[last()] | 选取属于bookstore子元素的最后一个book元素 |
| /bookstore/book[last()-1] | 选取属于bookstore子元素的倒数第二个book元素 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于bookstore元素的子元素的book元素 |
| //title[@lang] | 选取所有拥有名为lang的属性的title元素 |
| //title[@lang=‘eng’] | 选取所有title元素,且这些元素拥有值为eng的lang属性 |
| /bookstore/book[price>35.00] | 选取bookstore元素的所有book元素,且其中的price元素的值须大于35.00 |
选择未知节点
Xpath通配符可用来选取未知的XML元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
列出了一些路径表达式,以及这些表达式的结果
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取bookstore元素的所有子元素 |
| //* | 选取文档中的所有元素 |
| html/node().meta/@* | 选择html下面任意节点下的meta节点的所有属性 |
| //title[@*] | 选取所有带有属性的title元素 |
lxml库
- lxml是一个HTML/XML的解析器,主要的功能是任何解析和提取HTML/XML数据。
- 利用etree.HTML,将字符串转化为Element对象
- lxml Python 官方文档:http://lxml.de/index.html
- lxml 可以自动修正html代码
豆瓣读书小案例
目标网站:https://book.douban.com/top250?start=0
# -*- coding: utf-8 -*-
# @Time : 2020/1/31 14:46
# @Author : 大数据小J
import requests
from lxml import etree
import csv
class douban(object):
def __init__(self):
self.url = 'https://book.douban.com/top250?start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}
def get_url_list(self):
return [self.url.format(i * 25) for i in range(0, 10)]
def get_url_html(self, url_list):
list_data = []
for url in url_list:
response = requests.get(url, headers=self.headers)
html = response.text
result = etree.HTML(html)
datas = result.xpath('//tr[@class="item"]')
for data in datas:
info = {}
name = data.xpath('./td[2]/div/a/@title')[0] # 书的名字
result = data.xpath('./td[2]/p/text()')[0].split('/')
author = result[0] # 作者
alias = result[1] if len(result) == 5 else ' ' # 别名
Press = result[2] if len(result) == 5 else ' ' # 出版社
Press_time = result[-2] # 出版时间
Price = result[-1].replace('元', '') # 价格
forewords = data.xpath('./td[2]/p/span/text()') # 引言
foreword = forewords[0] if len(forewords) == 1 else ' '
# 保存数据
info['name'] = name
info['author'] = author
info['alias'] = alias
info['Press'] = Press
info['Press_time'] = Press_time
info['Price'] = Price
info['foreword'] = foreword
list_data.append(info)
return list_data
def download(self, url_data):
with open('豆瓣读书.csv', 'w', encoding='utf-8', newline='')as f:
wirter = csv.DictWriter(f,
fieldnames=['name', 'author', 'alias', 'Press', 'Press_time', 'Price', 'foreword'])
wirter.writeheader() # 写入表头
for each in url_data:
wirter.writerow(each)
# 实现业务逻辑功能
def run(self):
url_list = self.get_url_list()
url_data = self.get_url_html(url_list)
self.download(url_data)
if __name__ == '__main__':
r = douban()
r.run()
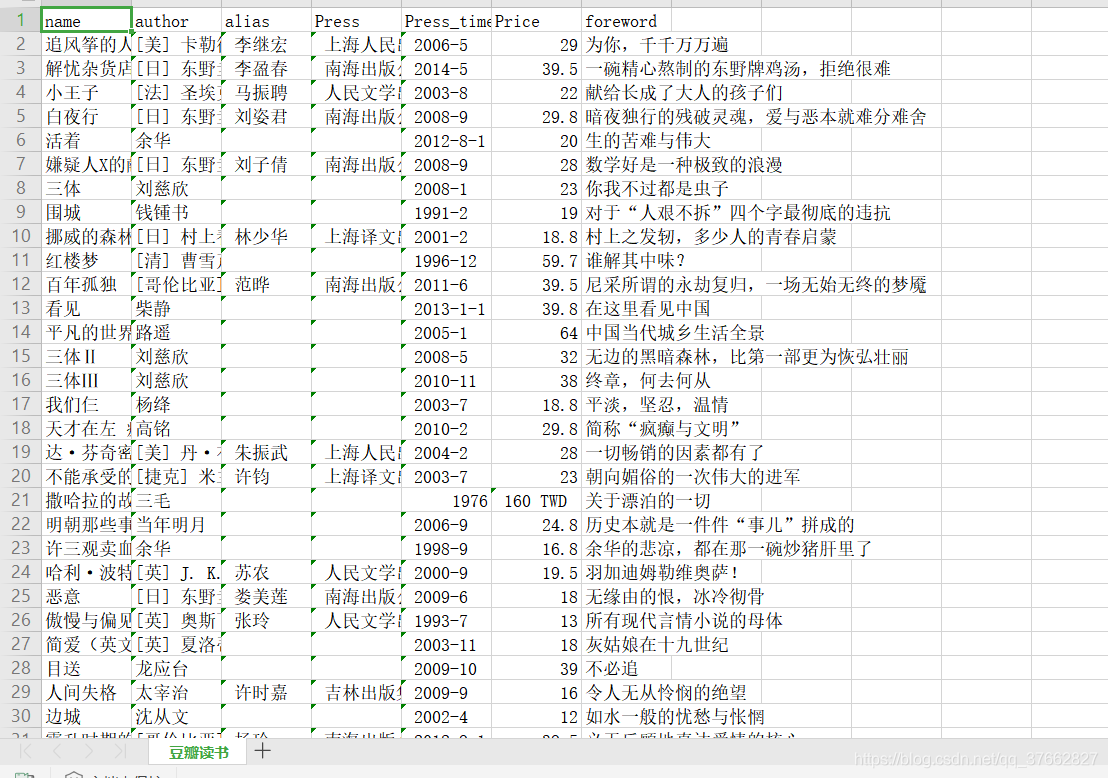
案例结果:















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









