







然而,RAID-0不能保证数据的可靠性,因为不管哪一块盘坏了,数据就永久丢失了。提高可靠性的最简单的方法就是将一块盘做为另一块盘的备份来组织,这就是RAID-1。RAID-1大大提高了可靠性,因为两块盘同时出问题的可能性很低,任何一块盘出了问题都可以由另一块盘补上,而且两块盘可以并行工作通过平衡负载来获得更高的吞吐率。但是用整块盘来做备份,牺牲了磁盘空间,数据空间只占整个磁盘空间的50%。
于是经过一系列的发展到了RAID-3456。RAID-3和RAID-4简单的说就是在一个RAID-0阵列的基础上又加了一个盘存储校验信息。这样做提高了RAID-0的可靠性,同时提高了磁盘空间利用率,假设3块盘的RAID-4只有一块盘用来存储冗余数据,因此磁盘空间利用率上升到66.6%。可靠性的提高通过校验盘来获得,如果有一块数据盘坏了,就可以利用校验盘和另一块数据盘上的数据计算出缺失的数据。但是把校验数据都集中放在一个盘上,使得这个盘的负载很重,成为整个阵列的性能的瓶颈。RAID-5的出现就是为了解决这个问题。RAID-5的基本思想就是将校验数据均匀的分布在各个盘上以解除瓶颈。RAID-345虽然提高了可靠性,但是只能容忍一块磁盘出问题,如果阵列中有两块磁盘坏了,那么整个整列数据可靠性都无法保证了。RAID-6就是在RAID-345的基础上再加入一个校验盘,利用两个冗余校验数据就能容忍阵列中两个磁盘出问题。
RAID在linux内核中的位置
RAID 的代码在linux内核代码中的driver/md目录下,这个目录下除了RAID的代码外还可以看到LVM的代码,devicemapper相关的代码都以dm-打头。估计这里MD表示multiple disk,或者multiple device,我没有考证过,以后直接称为MD设备就行。MD设备是linux内核提供的一种块设备驱动程序,但是这个设备驱动程序具体是怎样工作的则由其内部使用哪种磁盘组织形式,如RAID-0156。在 driver/md目录下,我们可以除了可以看到RAID-0156的代码以外还可以看到linear,multipath, 这些都是MD提供的内部组织形式。我们可以将MD设备看作是介于块设备驱动程序与RAID层之间的一层,但我常常将其视为包装了RAID的一个统一的管理器,他提供了通用的管理接口,而且并没有直接干预数据处理,一旦创建了MD设备以后,所有的数据都会直接送入RAID。实际上用面向对象的观点来看MD设备层可能更好:MD实际上是对各种RAID的抽象,也就是他们的抽象父类,提供了一些共性的属性方法,而各RAID子类,则拥有自己的属性方法,如果没有具体化为某个RAID对象,某个MD设备就不能直接使用。所以实际当中我们通常还是将MD和RAID统称为RAID层。
mdadm
如果将RAID编译到内核中,就可以使用各种RAID了,一般而言,通过"cat /proc/mdstat"就能看到MD设备的状态。而且用户可以通过 sysfs中提供的方式来访问RAID属性,具体如何使用这里就不多讲了,在以后的讨论中也许也会提到一些。但是,如何在应用层创建RAID并使用它的功能呢?linux软件RAID的作者Neil Brown也实现了一个应用层的工具mdadm。mdadm工具很方便也很强大,它几乎涵盖了RAID的方方面面。关于这个工具并不是我想讨论的重点,internet上应该可以获得更详尽的信息。
参考文献
我在这一年里对linux内核的整体认识来源于两本书:《Linux Device Drivers 3e》(LDD3) Understanding Linux Kernel 3e》(ULK3)。其他linux的知识则主要是从互联网上获得,当然LDD3和ULK3在网上都能找到电子版。在正式介绍RAID的过程中我会尽可能提供某些内容的出处,当然,能找到出处的内我就没有必要细说了,学习linux是离不开 internet的。
通常阅读RAID的代码,都是从RAID-0开始,因为RAID-0中并没有复杂的逻辑,而是仅仅是将送入RAID-0的数据重新映射并送入下层设备。我最初也是从RAID-0开始的,但是由于工作关系目前我对RAID-5更熟悉一些,还是从
好吧,那就开始进入RAID-5之旅…
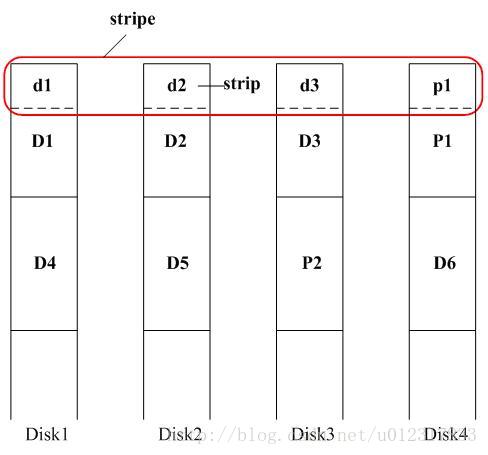
stripe, strip 与 P
RAID-5的I/O处理,特别是写请求,通常是以stripe为单位进行的。什么是stripe呢?三言两语还挺难表述的,画个图来说说吧。其中 D1,D2,D3,P1被称为chunk,磁盘上的数据就按照chunk组织到各个disk上。这样,这一排chunk也可以看成是一个stripe,但这种磁盘空间组织上的stripe,还不是RAID-5中的处理单元的stripe。RAID-5中的一个stripe的宽度总是4K(1 page),如图中的d1,d2,d3,p1组成的stripe。也就是说D1,D2,D3数据时连续的,但是d1,d2,d3数据时跳跃的。那么每一个 d1,d2,d3或p1在RAID-5中我们称之为strip。
P(parity)表示校验数据,校验数据的计算非常简单,就是xor,也就是P=D1+D2+D3,(这里+表示xor)。
查看大图
RAID-5基本原理
有了上面的概念以后,就可以简单描述RAID-5工作的基本过程。假设一个读请求送到RAID-5,那么RAID-5要做的只是找到他储存在哪个磁盘上的哪个位置并将其从磁盘中读出即可。如果一个写请求到来,假设为d2',RAID-5则要先将d2的数据从盘中读出,计算出p1'=p1+d2,然后再计算出 p1''=d2'+p1'作为新的校验数据,然后将d2'和p1''写回磁盘覆盖旧的数据。如果其中一个数据盘无法使用了,此时校验数据就能用来恢复数据。假设disk2无法访问,而此时需要读d2数据,那么RAID-5将会读出d1,d3和p1于是d2=d1+d3+p1;如果需要写d2',那么 RAID-5也会读出d1,d3和p1,于是只需计算新的p1'=d1+d2'+d3,将p1'写回即可。从中也可以看出RAID-5是以stripe作为单位来处理的。
bio 与 stripe_head
在linux块设备驱动中有一个非常重要的数据结构那就是bio。bio取代了2.4内核中的buffer head来表示块设备的I/O请求,以获得更大的性能和灵活性。简单来说,bio包含了一个块设备完成一次I/O请求所需要的一切信息。其中跟RAID层相关的几个重要字段是:
struct block_device *bi_bdev; /* 指向实际执行I/O的设备 */
sector_t bi_sector; /* I/O的起始扇区 */
unsigned int bi_size; /* I/O的大小 */
unsigned long bi_rw; /* 区分读,写*/
bio_end_io_t *bi_end_io; /* 指定I/O结束的callback函数 */
struct bio_vec *bi_io_vec; /* 这是一个数组,组织了参与I/O的page */
如果在今后的讨论中需要用到其它字段,届时再作介绍。
struct stripe_head在RAID-5代码中就对应于前面所说的stripe,在讨论中,我们常常把stripe_head直接称为stripe,但事实上 stripe_head更多的是内存和代码方面的概念。实际上,RAID-5是通过stripe_head结构来管理I/O缓冲区。在一个stripe 上,每一个disk都会分配一个缓冲区。不可能RAID-5设备中的每一个stripe都分配一个stripe_head,所以stripe_head的数量是有限的。在RAID-5开始运行的时候,stripe_head的总数被设为NR_STRIPES,通常为256。下面从该结构中挑出几个重要的来说说:
intpd_idx; /* 指示校验strip在stripe中的位置 */
unsigned long state; /* 指示stripe的状态 */
struct r5devdev[] /* 此结构用于管理每一个disk的缓冲区 */
stripe的状态可以处于下列一个或多个状态:
STRIPE_HANDLE /* 该stripe需要下一步处理 */
STRIPE_SYNCING /* 该stripe在处理resync或recovery请求 */
STRIPE_INSYNC /* 该stripe已经完成resync或recovery请求 */
STRIPE_PREREAD_ACTIVE /* 需要先预读某些disk上的数据到缓冲区中 */
STRIPE_DELAYED /* 推迟某些预读 */
STRIPE_DEGRADED /* 该stripe有disk已经被移除 */
STRIPE_BIT_DELAY /* 为了处理bitmap而作延迟 */
这里提到了一些概念,比如resync,recoivery,预读,bitmap。RAID-5设备创建完以后校验数据尚未准备好,因此需要在正式写RAID-5设备之前必须将校验数据计算出来,否则得到的校验数据将是错误的,这就需要通过一次resync请求来完成。recovery则更简单,就是用其它数据盘和校验盘的数据来恢复某个盘上的数据。以后会专门讨论这些过程。
在一个stripe中每一个strip都有一个struct r5dev结构体管理的缓冲区:
struct bio req; /* 转送入下层设备的bio */
struct bio_vec vec; /* 对应于req中的bi_io_vec */
struct page *page; /* 缓冲区内存页 */
struct bio *toread,*towrite,*written; /* 这是3个链表,分别记录在该缓冲区上的读,写,已写的bio */
sector_t sector; /* 该strip在整个RAID-5设备中的的扇区位置 */
unsigned long flags; /* 该缓冲区的状态标志 */
R5_UPTODATE /* 缓冲区内存页中已经包含了当前数据 */
R5_LOCKED /* 已经将"req"送交下层设备 */
R5_OVERWRITE /* 要写的数据覆盖了整个缓冲区 */
R5_Insync /* disk状态正常 */
R5_Wantread /* 需要从下层读出数据 */
R5_Wantwrite /* 需要向下层写入数据 */
R5_Overlap /* toread中的bio有重叠 */
R5_ReWrite /* 将重构的数据写回disk */
UPTODATE 和LOCKED两个状态位是最重要的,这两个状态位组合表示了缓冲区的4个状态:Empty,Want,Dirty,Clean。Empty表示缓冲区中尚未有数据;Want表示为缓冲区向下层发出读请求;Dirty表示缓冲区中已写入数据,并已向下层发出写请求;Clean表示缓冲区的数据已经与disk上一致了。这两个状态位与这些状态的关系包括状态之间的转换,在raid5.h中已开始就做了详尽的注释,也就不用多说了,具体的到下面讨论具体实现时再论述。这里要提一下的是Wantread和Wantwrite两个标志位,个人认为他们就是前两种状态的补充,只不过是在将req送到下层之前用来判断是该读还是该写。最后ReadError和ReWrite是用于Bad Sector Remapping(BSR,有译作硬盘坏轨映射机制的),这个在以后会集中讨论。strip和stripe实在是太像了,以后的strip我还是统一用dev来表示strip。
在 RAID-5中重要的数据结构还有raid5_private_data,就是代码里常见的conf,感觉没有必要去细说,看看在需要时再解释。在阅读 RAID层的代码时,会遇到很多变量名叫mddev,rdev,这些都是用于MD管理的结构对象,mddev就是指RAID-5所处的MD设备,rdev 则是组成该MD设备的子设备指针,其类型为mdk_rdev_t。这里可能要提一提mdk_rdev_t中,在RAID-5的数据路径中用得比较多的字段:flags。其中状态及含义在include/linux/raid/md_k.h中都有比较详细的说明,我要说的是我可能会将Faulty==0和 In_sync==0的状态更多的称为spare状态。
一次简单的读处理
这一切都是从make_request开始的。make_request的其中一个参数就是bio,至于一个bio是怎么送到make_request中的,这与块设备驱动内容相关,具体内容可以查看LDD3和ULK3,你或者可以从block/ll_rw_blk.c的generic_make_request函数开始寻找答案。
在make_request中,我们首先需要知道这个bio是要读哪个stripe的哪个dev。这些信息从raid5_compute_sector函数中获得。这两个信息就被放在new_sector和dd_idx中,根据new_sector信息,我们调用get_active_stripe取出一个 stripe_head即sh来处理这次读请求,根据dd_idx信息,我们调用add_stripe_bio将bio放入相应的dev,也就是放入 sh->dev[dd_idx].toread链表。
到此,就可以将sh送入handle_stripe函数中作第一轮处理。既然说是一次简单的读请求,那么我们忽略掉部分复杂的处理。在 handle_stripe中,看到相应dev的toread链表有请求,而且这个dev状态为Empty,我们就会将本dev标记为Want,最后将这个dev的req标记为读请求通过generic_make_request送交下层disk处理。还记得么,Empty状态,Want状态,req在前面已经介绍过了。请注意,在送到下层之前req的bi_rw标记为读以外还将其bi_end_io这个callback设为 raid5_end_read_request。就这样第一轮的handle_stripe结束,这个sh也被放入handle_list等待第二轮处理。在make_request中,可以看到这些动作都处在一个循环之中,关于这个循环的作用暂且先放一放。
如此这般,一次简单的读请求处理完毕。
一次简单的写处理
写处理相对于读则更加复杂,因为除了正常的数据以外还要计算及写入校验数据。
写处理也是从make_request开始的,前面读处理中描述的get_active_stripe和add_stripe_bio在写处理中也是一样的,唯一的区别是bio将被放入dev的towrite链表。接着sh被送入handle_stripe处理。
为了简化起见,我们假设这次sh中要处理只有一个写bio,而且这次写的内容覆盖了整个dev的缓冲区页。handle_stripe首先需要决定是要做 read-modify-write(rmw)还是reconstruct-write(rcw)。这两个概念以后会解释。根据我们的假设,这里rmw的可能性更高,所以我按rmw来解释。于是如果这个有towrite的dev和parity的dev的状态仍为Empty,handle_stripe就会将它们状态转为Want。大家如果看代码,这里会看到只有在这个sh状态为STRIPE_PREREAD_ACTIVE才会将dev由Empty转为 Want,这是RAID-5中一个巧妙的地方,这里我们只是假设sh的状态已经符合条件。接下了这些dev的req被作为读请求送到下层设备,第一轮的 handle_stripe处理就此结束。
下层写完成之后,callback函数raid5_end_write_request被调用,dev的状态由Dirty转为Clean。raid5再次醒来对这个sh做第三轮处理。这一轮处理非常简单,看到数据dev和校验dev状态均为Clean,就可以调用bio的bi_end_io通知上层本次写请求完成。
make_request是RAID-5数据路径的源头,正如我们前面对读写简单叙述中提到的,make_request就是取出stripe_head并将bio插入相应的dev链表,最后对stripe_head做第一轮处理。但我们看make_request的代码,并不是就这么简单的,它还有一些特殊的情况需要处理。
首先,对某一个bio上述的过程被一个循环包装起来。这个循环有何作用?如果你对比一下2.4和2.6中make_request的代码,会发现2.4中的make_request并没有这个循环。在2.6中,之所以需要这个循环,是因为bio的大小不再像2.4中的bh那样受到4K的限制了。但是RAID-5的stripe宽度为4K(STRIPE_SIZE),也就是说,一个bio有可能需要插入多个stripe_head中或者同一个stripe的多个dev中。所以,这个循环的作用就是将bio插入它所覆盖的所有stripe_head的dev中。我们可以看作是将bio分成了好几段,并用bio->bi_phys_segments来记下段数。那么,每插到一个dev中,bi_phys_segments++;而每一个dev完成相应的请求,bio退出dev时,bi_phys_segments--,一旦减到0,说明此bio的各段请求都完成,于是整个bio可以返回给上层。这里有点特别的是在进入循环之前,bio->bi_phys_segments初始化为1,而在make_request返回之前又作了一次减1。我认为这里主要是为了处理read-ahead,因为只有read-ahead可能从循环中break出来,如果bio->bi_phys_segments减到0,则直接返回失败。
接下来,在make_request中调用的一个很重要的函数是get_active_stripe。它之所以重要是由于stripe_head的数量是有限的,get_active_stripe就是保证有限的stripe_head能有效工作的重要一环。这个函数的详情我打算到后面介绍stripe_head管理中论述。
在make_request中另一个不可忽视的函数就是add_stripe_bio了。这里我先忽略掉firstwrite和bitmap相关的东西,那么add_stripe_bio所做的第一件事情就是检查新加入的bio是否与现有的bio有区域重叠(overlap)。说实话,我还不是很明白具体在什么情况下能产生这样的重叠,但无论如何RAID-5中是无法同时处理这样的两的bio。于是add_stripe_bio一检查到重叠则立即将dev标记为R5_Overlap并返回。在这种情况下,make_request就会催促原有bio的处理(通过raid5_unplug_device)然后释放已经拿到手的sh,剩下的就是等待原有bio完成(放入wait_for_overlap等待队列)。如果没有出现重叠,或者重叠已经消除,那么bio就会被加入到合适的dev链表中。对于写请求,add_stripe_bio还要做一个特殊的检查,那就是这个bio的写区域是否覆盖了整个dev区域。如果是的话,这个dev就会被打上R5_OVERWRITE标记。R5_OVERWRITE标记在后面的处理sh中会经常碰到,这里我可以稍微提一提它的作用。到目前为止我们已经知道RAID-5处理是以stripe为单位的,计算Parity也是以page为处理单位,那么如果我们的写bio没有覆盖整dev页,某些情况下(具体情况会在下面分析)就不得不先将下层设备中数据读入dev页,才能将bio的数据写入dev页,这样dev页中的数据才能被用来计算新的Parity。怎么样?脑子如果还没乱,congratulations!!如果取到了stripe_head并加入了bio,第一轮handle_stripe都会在make_request中执行。Handle_stripe完成后,make_request的任务也就完成了。
对于写请求的处理,可以分为read_modify_write(rmw)和read_reconstruct_write(rcw)。由于前面介绍一次简单的写处理时假设了sh只有一个dev需要写,于是就按照rmw的过程来介绍了。但事实上,一个sh中可能有多个dev要写,这就产生了一个问题:如何能减少这次处理的所需的预读操作?正如前面描述的,为了计算Parity,一些预读处理是不可避免的。所以,区分rmw和rcw就是为了使这些预读尽可能少。
if (list_empty(&conf->handle_list) &&
atomic_read(&conf->preread_active_stripes) < IO_THRESHOLD &&
!blk_queue_plugged(mddev->queue) &&
!list_empty(&conf->delayed_list))
raid5_activate_delayed(conf);
翻译成中文,也就是说:如果RAID-5的daemon观察到handle_list中已经没有sh可以处理,而也没有sh在做预读(IO_THRESHOLD值为1),mddev已经unpluged,delay_list有sh等待,那么我就应该激活delay_list中的sh来处理。所谓激活,其实就是在raid5_activate_delayed函数,将delay_list中的sh取出放入handle_list并设置好sh的STRIPE_PREREAD_ACTIVE状态位,同时preread_active_stripes加1。咱们再来找找 preread_active_stripes何时减1。对,没错,在预读完成后,准备向下层设备写的时候清除STRIPE_PREREAD_ACTIVE状态位,preread_active_stripes减1(当然,在__release_stripe中也能看到类似的代码,但我想那里是为了清除残留的状态标记,比如在发生读写错误的时候)。
错误处理
RAID-5能提供一定程度的可靠性,也就是说能容忍一定程度的错误,那么在I/O中出现错误的时候, RAID-5时如何处理的呢?
所谓Bad Sector Remapping,就是将坏扇区中的数据写到另一个位置,将来所有对原先坏扇区的访问今后都会重新定向到新的位置。由于很多硬盘设备都已经支持BSR,要利用BSR我们所要做的工作就是将坏扇区中的数据再一次写回到相同的位置,如果设备支持BSR(在硬盘内部也许已经被重定向了) ,那么再读一次该扇区就会读成功。所以如果我们在发生读错误以后就直接将错误设备标记为Faulty,那就是相当于没有利用它的BSR的能力就将它踢出RAID-5,这实际上降低的 RAID-5的可靠性。因为RAID-5可以利用一个冗余校验盘来恢复读错误的数据,因此RAID-5完全有能力利用BSR。
所谓失效(failed),我这里指的是RAID-5下层设备无法正常工作。比方说,下层的n个设备中有两个设备发生了故障,那么在这两个设备上的数据将无法再读写,因为你无法直接读取盘上的数据,也无法通过Parity将这些数据计算出来,同时,写的时候也无法提供足够数据来计算Parity。也就是说,RAID-5已经无法正常工作。
那我们来看看RAID-5在有设备失效的情况下是怎样处理的。相应代码在handle_stripe中都能找得到。先看看只有一个下层设备失效的情况。
通过前面论述的一些RAID-5的数据路径中的一些处理,大家应该已经发现,无论是读还是写都离不开一个函数,handle_stripe。这个函数就像RAID-5数据处理的核心。前面我们所讲的一些操作如rmw和rcw,BSR,延迟写大部分的相关代码都能在handle_stripe中找到。这个函数有近500行的代码,可见这个函数要处理的内容有多么丰富,弄懂了这个函数,基本上就能理解linux中RAID-5数据是如何处理的。
实际上前面的论述,已经对handle_stripe的很多处理进行了解析,所以这里我只想对整个handle_stripe串起来再看一遍。
Handle_stripe的一开始是一个循环,这个循环中做了两件事情,其一就是返回一些读请求,另一个就是为下面的处理统计一些数据。返回读的条件很简单,那就是只要dev的 R5_Uptodate标志位被置为1,也就是说dev的状态是Dirty或者Clean就行,这表明缓冲区中的数据已经是最新的。至于统计的数据就是后续的处理所需的条件,比如说我们通过统计失效设备的个数来决定是否可以恢复一些数据或不得不放弃。
raid5d是RAID-5的守护线程,我们知道make_request将数据做了初步处理以后就结束了,那么这个stripe_head的后续处理权就都交到了raid5d的手里。
我们可以去看raid5d的代码,也就是raid5d函数。一但raid5d被唤醒,他所做的就是执行raid5d函数,这个函数所做的事情很简单,那就是将handle_list里的stripe_head一个个拿出来处理,如果handle_list里的stripe_head都处理完了,那就再看看 delay_list里有没有满足条件可以处理的,也就是被延迟写的stripe_head是否能被处理,可以处理的话就放到handle_list中,一个个让raid5d去处理。
前面其实我们已经看到了一些stripe_head管理的结构,比如handle_list,delayed_list。我们知道,stripe_head是在RAID-5开始运行的时候开辟的缓冲区,这是个有限的资源,那么除了要在数据处理过程中需要调度以外,还需要一套完整的机制去使得这些有限的资源能够满足数据情求的处理所需。
在RAID-5开始运行的时候,为所有的stripe_head分配了内存(通过grow_stripes函数)。通过看代码能发现,linux源码中最大的stripe_head数量是256,但是你完全可以通过在代码中调整这个值来调整RAID-5的内容,因为这个数量是跟性能有关。一开始的时候,所有的stripe_head都被放到了inactive_list. inactive_list和handle_list、delayed_list是在I/O处理时最重要的三个链表。除了这些链表,RAID-5为了更好的管理这些stripe_head还为建立了一个hash表来提高通过sector来查找stripe_head的速度,至于hash表是如何使用的,这应该不用多介绍了。
一切都是从头开始的,在RAID-5开始运行之初,所有的stripe_head(下面都用简写sh)都在inactive_list中,而hash表中也没有记录任何sh。最初的变化发生在make_request调用get_active_stripe以后。那就来看看get_active_stripe干了些什么。
get_active_stripe中首先调用find_stripe在hash表中找找看指定sector的stripe是否已经存在了?如果存在的话,那说明这个sh刚有人用过,我们可以直接拿来用,可以省去初始化的动作。但是这个sh可能已经处于handle_list或者delayed_list中的一个,此时我们必须要先从这个list中删除。如果hash表中不存在,那么就调用get_free_stripe从inactive_list中取出一个sh来,也就是说从 inactive_list中删除。这时取出来的sh就必须进行初始化了,初始化的工作由init_stripe负责。但是sh既然是紧缺资源,那总会有用光的一天,这也就是说,通过find_stripe和get_free_stripe都找不到sh来使用。这种情况下我们能怎么办呢?没办法,那就等吧。于是我们在get_active_stripe中看到了wait_event_lock_irq调用的代码。这个看似函数东西其实是个宏定义,由于他是在md中定义,在RAID-1456中都有广泛使用,所以我想稍微提一提。这个宏的作用是,如果条件不满足,调用make_request的线程就会被加入到一个等待队列(此时为wait_for_stripe队列),但是在放弃CPU之前,这个函数还会执行一个cmd(此时是 unplug_slaves(conf->mddev)),这通常就是个敦促其他线程去赶紧处理,使得等待的条件(event)尽早满足。在 get_active_stripe这个要等待的event有些特别:
!list_empty(&conf->inactive_list) &&
(atomic_read(&conf->active_stripes)< (conf->max_nr_stripes *3/4)
为什么说他特别呢?因为这个等待并不是只要inactive_list不空就能结束等待,而是要等到active的sh的数量低于所有sh数量的 3/4(256*3/4=192)。这个3/4是如何得出的我无从知晓,但是可以肯定的是,如果只要inactive_list不空就结束等待性能是很差的。由于有这样一个等待,我们就可以看看何时去唤醒这个等待队列的。我想只要搜索wait_for_stripe应该就能明白,所以我也不必多说。看完这个函数,我们就知道get_active_stripe最终一定能(除了readahead外)取得一个active的sh,而且这个sh游离于任何list之外。
如果sh处于游离状态,说明它需要被handle_stripe处理。处理完后,就需要将它再放入某个list,这个工作总是通过 release_stripe函数来完成。所以在调用handle_stripe之后,我们总能看到release_stripe的调用。但是 release_stripe并不是都在handle_stripe之后,搜索一下就能知道。在end_read_request和 end_write_request的最后也会调用release_stripe,我们观察一下release_stripe的代码就知道,他必须等到 sh->count减到0为止,才重新决定sh的位置。而我们也可以看到,sh->count除了在get_active_stripe出来以后会加1以外,在handle_stripe中如果有读写要往下送,sh->count也会增加,而每次减少就是又release_stripe来做,直到减到0,release_stripe就要重新决定sh该放到哪个list中。
走入release_stripe内部…如果sh->count已经减到0,那就首先看它有没有置STRIPE_HANDLE位。如果没有,那么说明这个sh已经处理完毕,应该放回inactive_list中,这时如果有人在等待空闲的stripe_head就把它唤醒。如果sh置了STRIPE_HANDLE位,那么再根据它是否置了STRIPE_DELAYED或STRIPE_BIT_DELAY位来确定是要把它放入 delayed_list还是bitmap_list。如果这两个位都为0,那么就放入handle_list。最后就是唤醒raid5d准备处理。所以整个sh的生命周期是从inactive_list开始,处理时在handle_list和delayed_list之间切换,处理完以后又被放回 inactive_list。
下一篇会讨论一下RAID-5中的resync和recovery :)
resync和recovery的大部分工作都是由MD设备来调度的,但是不同的RAID可能处理sync请求的方式不一样。关于resync和recovery是如何调度的,由于这是MD的主要工作之一,所以在后面说到MD时会着重讨论。
但是我们有必要知道resync和recovery在RAID-5中的作用。我们知道RAID-5在写数据时需要计算Parity,更重要的是如果做的是 rmw,那就要求Parity在写之前必须已经正确的写到下层设备中。而在RAID-5刚刚创建的时候这些Parity可能都是错误的,所以resync对RAID-5的作用就是从头到尾将每一个stripe的Parity计算出来,计算完成后我们就说这些stripe是In_sync的。所谓 recovery,其实就是用一个空闲设备来替换失效的设备,在空闲设备上恢复失效设备上数据的过程就称之为recovery。这两个过程很相近,都是通过计算写入某个设备的数据。如果使用过mdadm来创建RAID-5设备,我们会发现创建出来的RAID-5并不是做resync,而是对某个盘做 recovery,如果你要让RAID-5做resync,就必须加上--force选项。这样做的目的我想是出于这么一种考虑:如果做resync,那么在resync完成之前,在还没有In_sync的stripe上做了rmw,那么会得到一个错误的Parity,这就可能是数据错误的隐患;而如果做 recovery,那么如果要恢复的数据不是Parity,那就是假设原始的Parity是正确的,而这样做是无害的,不用担心rmw的问题。但是做 recovery也有他的问题,那就是在没有完成recovery之前,这个RAID-5设备就失去了他的容错能力。
由于resync和recovery请求都是由MD内部发起,所以不能通过make_request函数,因为这是上层发起的请求。在RAID-5 中,resync和recovey请求是由sync_request函数发起的。我们说不同RAID的处理不同,其不同处理就是通过提供各自的 sync_request来实现的。sync_request的工作过程其实和make_request很像,都是通过 get_active_stripe拿到一个stripe_head,然后交给handle_stripe做第一轮处理。所不同的是下面几点:
1.不需要和上层bio打交道
2.对于resync,会检查是否已经有设备失效
3.get_active_stripe的调用有点奇怪
4.很多bitmap处理
关于第2点,其实很简单,resync不能有失效设备,否则是无法检查或计算Parity的。如果存在失效设备,那么就把所有剩下没有resync的 stripe均跳过不做,通过做这种方式通知MD停止resync。关于第3点,我还没有完全理解作者这样做的用意,所以不敢妄加议论。
实际上,在handle_stripe中我们还有resync相关的一部分没有讨论,现在是时候了。在to_read处理的部分,我们还能看到这样的条件 syncing && (uptodate < disks),意思就是说,如果是做syncing,我们必须使所有的dev都成为Uptodate的。syncing表明在sync_request中置了STRIPE_SYNCING,说明这是在做resync或recovery。在这一部分,resync与recovery的处理是不同的,由于 resync没有失效设备,也就是说所有的dev都是In_sync的,那么此时所有的dev都是通过从下层设备中读出。而因为recovery有一个 dev不是In_sync的,这个dev就是我们要恢复数据的dev,是不能从下层读出的,所以必须等到其他的dev都已读出(Uptodate),此时只有一个dev没有Uptodate,这时uptodate == disks-1这个条件满足,那么handle_stripe调用compute_block函数来计算剩下的dev。
到此为止,所有的dev应该都是Uptodate的了。接下来,resync与recovery也有不同。先说说resync,他首先会检查Parity是否已经是正确的,检查的方法很简单,那就是将所有的dev中的数据做xor,如果Parity是正确的,那么xor的结果就是0。如果不是0,就用数据 dev的数据来计算Parity,再写入下层设备就行。如果是recovery,我们知道在恢复失效dev的时候已经做了计算,实际上这次计算过后整个 stripe的内容就都INSYNC了,那我们所要做的无非就是将这个正确的数据写入下层设备,完成恢复磁盘数据的过程。
看来RAID-5中该说的,能说的都七七八八了,其它零碎就放在下一篇作为收尾吧:)
前面几篇林林总总,从RAID-5原理,到错误,失效处理,主要还是围绕数据处理的方方面面来说的,但是RAID-5要能正常使用,没有一些控制函数的辅助是不可能的。我所说的这些控制函数可以在raid5.c快要结束的地方,在raid5_personality这个结构中找到他们的名字。
raid5_personality中的函数,除了make_request直接作用在数据路径中以外,其它的都是通过MD的控制函数间接调用的。关于MD中的控制函数跟RAID-5相比,繁复程度有过之而无不及,但因为没有特殊的算法,也就没有什么特殊的原理,主要是看它的处理过程。但是MD并不是我在RAID-5中的讨论的重点,只是为了理解RAID-5特定的控制函数而提及相关的内容。
其实raid5_personality中的函数可以用面向对象中的重载函数来理解,正如我们在一开始提到MD说的那样,这是RAID-5对MD父类方法的重载。废话少说,其中make_request和sync_request都已经谈过,不必重复,就从没说过的开始。
首先是run,顾名思义,很简单这就是在RAID-5开始运行时调用,进行一些初始化的操作,主要是对RAID-5中的conf进行初始化,这里面的代码也有点搞来搞去,但是只要明白了RAID-5的数据结构,那所有的代码就一目了然了。run函数在md.c的do_md_run中被调用。
如果说run有点构造函数的意思,那么stop函数就有析构函数的味道了。看看这个函数,不是unregister就是shrink,kfree,都是所有的资源一一释放。stop是在md.c的do_md_stop中调用。
下一个就是status函数,这是在md_seq_show中调用,这是个在/proc文件系统中使用的函数、我们通过”cat /proc/mdstat”命令行得到的信息就是通过md_seq_show显示的。其中RAID-5的信息则是由md_seq_show调用status函数来显示,这要是显示设备状态和resync或recovery状态。
error函数我们在讨论错误处理的时候已经提过。
raid5_add_disk函数是将一个rdev放入RAID-5的disk数组中。这里比较容易让人误会的是,以为这是被md.c中hot_add_disk函数调用的,我最初就是这样想当然的,但事实并非如此,这个函数真正被调用时在md_check_recovery中,而MD的hot_add_disk目的是将rdev加入到md设备,而事实上还没有加入到RAID-5中。所以,我们常将md的hot_add_disk称为为外部hot_add,而personality中hot_add_disk称为内部hot_add。
与raid5_add_disk相反,raid5_remove_disk则是从RAID-5的disk数组中将rdev踢出去。同样道理,它也不是在md的hot_remove_disk被调用,而是在md_check_recovery中被调用。但是要知道md的hot_remove_disk要想成功,前提是raid5_remove_disk已经调用成功。
raid5_spare_active函数也是在md_check_recovery中被调用,作用就是将完成了recovery的spare的rdev激活,告知RAID-5这个rdev数据已经恢复完成可以正常工作了,同时修改md的一些统计数据。
raid5_resize,这个函数应该一目了然,那就是调整RAID-5的大小。
最后一个是raid5_quiesce,这是个给外部调用来禁止或启动写操作的函数,这在某些情况下是个很重要的特性。
终于写完了。然而RAID-5只是MD的一个组成部分,要想知道RAID是怎么工作的,还是得了解MD的一些内容,接下去谈谈md.c的阅读理解。
最近一段时间又重新接触了RAID,这次是关于RAID5 Write Hole的问题。这里把我对这个问题的理解描述一下。
Write Hole是RAID5的一个重大缺陷,这个问题在我以前的日志中已经提到过,但是只是作为解释代码的引子,而没有强调它的重要性。要了解这个问题,首先要对RAID5的rcw和rmw有一定了解。我以前的文章(RAID-5(五)rmw与rcw )已经解释过这些动作。为了方便说明,假设有一个5个盘的RAID5(为什么是5个盘?因为rmw)。
我们知道在RAID5的一个IN_SYNC的stripe中,必须满足D1+D2+D3+D4+P=0,这样任何一个数据Dx才能由其他数据和P计算出来。但是在Power failure的情况下会使得D1+D2+D3+D4+P!=0。为什么呢?假设这样一种情况:我们要写D1',那么新的P'都会写到disk上,然而不幸的是在还没写完呢就停电了。这时候可能出现的情况D1和P就会变成未知数据X和Y。X当然有可能是D1也有可能是D1',更可能是D1和D1'的混合物,Y也是如此。总而言之,X+D2+D3+D4+Y = 0成立的可能性不大。这种情况我这里都统一叫Parity损坏。
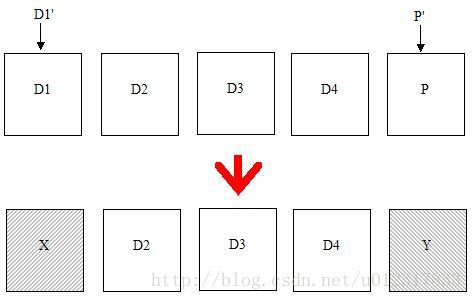
来看看会出现什么问题。最大的问题是就是这个RAID5已经没有了容许失去一个盘的功能了,换句话说,就是这个RAID5如果少了一个盘很可能就会造成数据丢失。要知道任何一个数据盘x丢失都可能造成Dx(x=1~4)的数据丢失,因为用这个错误的P算出来的Dx是错误的。假设这些是关键数据比如说文件系统的meta data...对做存储的来说数据完整性是关乎生存和发展的大事!!更为可怕的是,这个漏洞可能潜伏下来。还记得RAID5的rmw?rmw并不用其他数
据来计算P'而是用老的P来算P',那么如果P是坏的,那么P'也就是坏的。这个问题,如果RAID5是healthy的,那是可以补救的。Linux软件RAID就通过发起resync来同步Parity。它通过in_sync flag来检测是否需要resync。还可以通过设定bitmap file来减少做resync的stripe的数量。
然而第二个问题如果没有外界辅助似乎就没有办法了。那就是对degraded的RAID5,只要发生掉电导致Parity损坏,数据丢失就在所难免。为什么会这样?还是来看个例子,假设degraded RAID5少了disk4,还是写D1'而且P'被写坏,那么D4的数据就损坏了而且无法恢复。因为在degraded的情况下,D4的正确性完全依赖于disk5上的P或者P'。一旦P和P'损坏,就会导致D4损坏。而D4没有记在实体disk上,那么一旦损坏就没有办法找回了。你可能觉得这种情况应该
算是合理的,因为毕竟少了一个盘。但是你想一想,如果是4个盘的RAID0,就不会有Write Hole。
Write Hole同样存在于Linux RAID6中,但是因为RAID6没有rmw,所以如果是healthy的disk漏洞潜伏的可能性要小。但是对Degraded的RAID6,数据损坏依然不可避免(是不是这样我倒没有仔细研究过代码,但从分析上看应该是这样的)。
Write Hole是RAID5的天然缺陷,依靠RAID5本身是无法解决这个问题的。为此很多公司提出了自己的解决方案,或者干脆绕开RAID5提供替代方案。有兴趣的朋友可以自己google。














 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









