







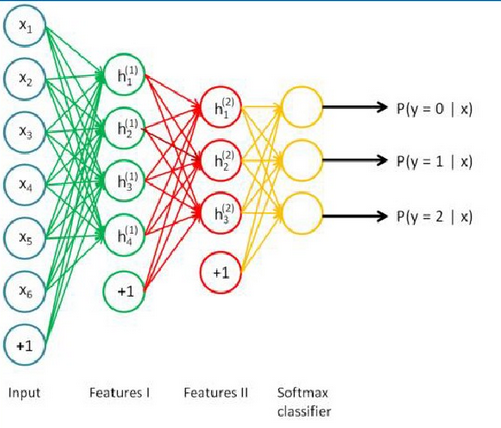
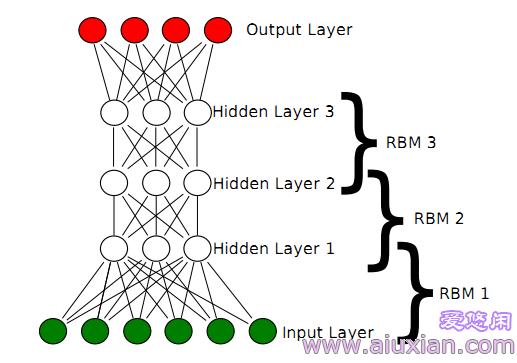
深度信念网
utils.h
#ifndef UTILS_H
#define UTILS_H
#include "stdlib.h"
#include "math.h"
double uniform(double, double);
int binomial(int, double);
double sigmoid(double);
#endifutils.cpp
#include "utils.h"
//产生[min, max)上的随机数
double uniform(double min, double max)
{
return (double)(rand() % RAND_MAX) / ((double)RAND_MAX) * (max - min) + min;
}
/*
二项分布
n:次数
p:概率
返回:成功的次数
*/
int binomial(int n, double p)
{
if(p < 0 || p > 1)
return 0;
int i;
int c = 0;
double r;
for(i=0; i<n; i++)
{
r = (double)rand() / (RAND_MAX + 1.0);
if (r < p)
c++;
}
return c;
}
//激活函数
double sigmoid(double x)
{
return 1.0 / (1.0 + exp(-x));
}dbn.h
#ifndef DBN_H
#define DBN_H
#include "hiddenlayer.h"
#include "logisticregression.h"
#include "rbm.h"
typedef struct
{
int N; //训练样例数
int n_ins; //输入单元数
int *hidden_layer_sizes; //各隐层的单元数
int n_outs; //输出单元数
int n_layers; //隐层数
HiddenLayer *sigmoid_layers; //隐层
RBM *rbm_layers; //RBM
LogisticRegression log_layer; //最上层,用来分类
} DBN;
void DBN__construct(DBN*, int, int, int*, int, int);
void DBN__destruct(DBN*);
void DBN_pretrain(DBN*, int*, double, int, int);
void DBN_finetune(DBN*, int*, int*, double, int);
void DBN_predict(DBN*, int*, double*);
#endif
dbn.cpp
#include "dbn.h"
//构建深度信念网DBN
void DBN__construct(DBN* dbn, int N, \
int n_ins, int *hidden_layer_sizes, int n_outs, int n_layers)
{
int i, input_size;
dbn->N = N; //训练样例数目
dbn->n_ins = n_ins; //输入单元数
dbn->hidden_layer_sizes = hidden_layer_sizes; //各隐层的单元数
dbn->n_outs = n_outs; //输出单元数
dbn->n_layers = n_layers; //隐层数
dbn->sigmoid_layers = new HiddenLayer[n_layers];
dbn->rbm_layers = new RBM[n_layers];
// 创建层
for(i=0; i<n_layers; i++)
{
if(i == 0) //如果是第一层
{
input_size = n_ins; //该层输入单元数 = 实际输入单元数
}
else //否则,该层输入单元数 = 上一层的输出单元数
{
input_size = hidden_layer_sizes[i-1];
}
// 构建 sigmoid_layer
HiddenLayer__construct(&(dbn->sigmoid_layers[i]), \
N, input_size, hidden_layer_sizes[i], NULL, NULL);
// 构建 rbm_layer
RBM__construct(&(dbn->rbm_layers[i]), N, input_size, hidden_layer_sizes[i], \
dbn->sigmoid_layers[i].W, dbn->sigmoid_layers[i].b, NULL);
}
// 输出层使用 LogisticRegression
LogisticRegression__construct(&(dbn->log_layer), \
N, hidden_layer_sizes[n_layers-1], n_outs);
}
//析构
void DBN__destruct(DBN* dbn)
{
/*
for(int i=0; i<dbn->n_layers; i++)
{
HiddenLayer__destruct(&(dbn->sigmoid_layers[i]));
RBM__destruct(&(dbn->rbm_layers[i]));
}
*/
delete dbn->sigmoid_layers;
delete dbn->rbm_layers;
}
//预训练 使用非监督贪婪逐层方法去预训练获得权值
/*
1. 首先充分训练第一个 RBM;
2. 固定第一个 RBM 的权重和偏移量,然后使用其隐性神经元的状态,作为第二个 RBM 的输入向量;
3. 充分训练第二个 RBM 后,将第二个 RBM 堆叠在第一个 RBM 的上方;
4. 重复以上三个步骤任意多次;
5. 如果训练集中的数据有标签,那么在顶层的 RBM 训练时,这个 RBM 的显层中除了显性神经元,还需要有代表分类标签的神经元,
一起进行训练。
*/
void DBN_pretrain(DBN* dbn, int *input, double lr, int k, int epochs)
{
int i, j, l, m, n, epoch;
int *layer_input;
int prev_layer_input_size;
int *prev_layer_input;
int *train_X = new int[dbn->n_ins];
for(i=0; i<dbn->n_layers; i++) // layer-wise
{
for(epoch=0; epoch<epochs; epoch++) // 训练周期
{
for(n=0; n<dbn->N; n++) // 训练样例
{
// 初始输入
for(m=0; m<dbn->n_ins; m++)
train_X[m] = input[n * dbn->n_ins + m];
// 层输入
for(l=0; l<=i; l++)
{
if(l == 0)
{
layer_input = new int[dbn->n_ins];
for(j=0; j<dbn->n_ins; j++)
layer_input[j] = train_X[j];
}
else
{
if(l == 1)
prev_layer_input_size = dbn->n_ins;
else
prev_layer_input_size = dbn->hidden_layer_sizes[l-2];
prev_layer_input = new int[prev_layer_input_size];
for(j=0; j<prev_layer_input_size; j++)
prev_layer_input[j] = layer_input[j]; //前一层的输入
delete layer_input;
layer_input = new int[dbn->hidden_layer_sizes[l-1]]; //本层的输入
//构建前一层的输出,layer_input,也就是本层的输入
HiddenLayer_sample_h_given_v(&(dbn->sigmoid_layers[l-1]), \
prev_layer_input, layer_input);
delete prev_layer_input;
}
}
//对比散度算法,更新当前玻尔兹曼机dbn->rbm_layers[i]的权重、偏置
RBM_contrastive_divergence(&(dbn->rbm_layers[i]), layer_input, lr, k);
}
}
}
delete train_X;
delete layer_input;
}
//调整
/*
生成模型使用 Contrastive Wake-Sleep 算法进行调优,其算法过程是:
1. 除了顶层 RBM,其他层 RBM 的权重被分成向上的认知权重和向下的生成权重;
2. Wake 阶段:认知过程,通过外界的特征和向上的权重 (认知权重) 产生每一层的抽象表示 (结点状态) ,
并且使用梯度下降修改层间的下行权重 (生成权重) 。
3. Sleep 阶段:生成过程,通过顶层表示 (醒时学得的概念) 和向下权重,生成底层的状态,同时修改层间向上的权重。
*/
void DBN_finetune(DBN* dbn, int *input, int *label, double lr, int epochs)
{
int i, j, m, n, epoch;
int *layer_input;
int *prev_layer_input;
int *train_X = new int[dbn->n_ins];
int *train_Y = new int[dbn->n_outs];
for(epoch=0; epoch<epochs; epoch++) //训练次数
{
for(n=0; n<dbn->N; n++) // 输入样例 x1...xN
{
// 初始输入
for(m=0; m<dbn->n_ins; m++)
train_X[m] = input[n * dbn->n_ins + m];
for(m=0; m<dbn->n_outs; m++)
train_Y[m] = label[n * dbn->n_outs + m];
// 层输入
for(i=0; i<dbn->n_layers; i++)
{
if(i == 0)
{
prev_layer_input = new int[dbn->n_ins];
for(j=0; j<dbn->n_ins; j++)
prev_layer_input[j] = train_X[j];
}
else
{
prev_layer_input = new int[dbn->hidden_layer_sizes[i-1]];
for(j=0; j<dbn->hidden_layer_sizes[i-1]; j++)
prev_layer_input[j] = layer_input[j];
delete layer_input;
}
layer_input = new int[dbn->hidden_layer_sizes[i]];
//由前一层的输入构建前一层的输出,也就是本层的输入
HiddenLayer_sample_h_given_v(&(dbn->sigmoid_layers[i]), \
prev_layer_input, layer_input);
delete prev_layer_input;
}
//更新dbn->log_layer的权值,偏置参数
LogisticRegression_train(&(dbn->log_layer), layer_input, train_Y, lr);
}
// lr *= 0.95;
}
delete layer_input;
delete train_X;
delete train_Y;
}
//预测
void DBN_predict(DBN* dbn, int *x, double *y)
{
int i, j, k;
double *layer_input;
// int prev_layer_input_size;
double *prev_layer_input;
double linear_output;
prev_layer_input = new double[dbn->n_ins];
for(j=0; j<dbn->n_ins; j++)
prev_layer_input[j] = x[j];
// 层激活
// 用上一层的输出计算当前层每个单元被激活的概率
// 然后当前层的输出再作为下层的输入
for(i=0; i<dbn->n_layers; i++)
{
layer_input = new double[dbn->sigmoid_layers[i].n_out];
linear_output = 0.0;
for(k=0; k<dbn->sigmoid_layers[i].n_out; k++)
{
for(j=0; j<dbn->sigmoid_layers[i].n_in; j++)
{
linear_output += dbn->sigmoid_layers[i].W[k][j] * prev_layer_input[j];
}
linear_output += dbn->sigmoid_layers[i].b[k];
layer_input[k] = sigmoid(linear_output);
}
delete prev_layer_input;
if(i < dbn->n_layers-1) //记录当前层每个单元被激活的概率,供计算下一层使用
{
prev_layer_input = new double[dbn->sigmoid_layers[i].n_out];
for(j=0; j<dbn->sigmoid_layers[i].n_out; j++)
prev_layer_input[j] = layer_input[j];
delete layer_input;
}
}
//分类,预测
for(i=0; i<dbn->log_layer.n_out; i++)
{
y[i] = 0;
for(j=0; j<dbn->log_layer.n_in; j++)
{
y[i] += dbn->log_layer.W[i][j] * layer_input[j];
}
y[i] += dbn->log_layer.b[i];
}
LogisticRegression_softmax(&(dbn->log_layer), y);
delete layer_input;
}
受限玻尔兹曼机
rbm.h
#ifndef RBM_H
#define RBM_H
#include "utils.h"
typedef struct
{
int N; //训练样例数目
int n_visible; //可视层结点个数
int n_hidden; //隐层结点个数
double **W; //权重矩阵W[h_i][v_j]表示可视单元v_j连向隐藏单元h_i的权重
double *hbias; //隐层偏置向量
double *vbias; //可视层偏置向量
} RBM;
void RBM__construct(RBM*, int, int, int, double**, double*, double*);
void RBM__destruct(RBM*);
void RBM_contrastive_divergence(RBM*, int*, double, int);
void RBM_sample_h_given_v(RBM*, int*, double*, int*);
void RBM_sample_v_given_h(RBM*, int*, double*, int*);
double RBM_propup(RBM*, int*, int, double);
double RBM_propdown(RBM*, int*, int, double);
void RBM_gibbs_hvh(RBM*, int*, double*, int*, double*, int*);
void RBM_reconstruct(RBM*, int*, double*);
#endif
rbm.cpp
#include "rbm.h"
//构造受限玻尔兹曼机RBM
void RBM__construct(RBM* rbm, int N, int n_visible, int n_hidden, \
double **W, double *hbias, double *vbias)
{
int i, j;
double a = 1.0 / n_visible;
rbm->N = N; //样例个数
rbm->n_visible = n_visible; //可视层结点个数
rbm->n_hidden = n_hidden; //隐层结点个数
if(W == NULL) //创建权重矩阵
{
rbm->W = new double*[n_hidden];
for(i=0; i<n_visible; i++)
rbm->W[i] = new double[n_visible];
for(i=0; i<n_hidden; i++)
{
for(j=0; j<n_visible; j++)
{
rbm->W[i][j] = uniform(-a, a); //随机数
}
}
}
else
{
rbm->W = W;
}
if(hbias == NULL) //创建隐藏偏置向量
{
rbm->hbias = new double[n_hidden];
for(i=0; i<n_hidden; i++)
rbm->hbias[i] = 0;
}
else
{
rbm->hbias = hbias;
}
if(vbias == NULL) //创建可视层偏置向量
{
rbm->vbias = new double[n_visible];
for(i=0; i<n_visible; i++)
rbm->vbias[i] = 0;
}
else
{
rbm->vbias = vbias;
}
}
//析构
void RBM__destruct(RBM* rbm)
{
for(int i=0; i<rbm->n_hidden; i++)
delete rbm->W[i];
delete rbm->W;
delete rbm->hbias;
delete rbm->vbias;
}
/*
contrastive divergence(对比散度)算法,更新参数
input:可视层结点状态
lr:学习速率
k:第k次采样,得到马尔科夫链中的一个采样(v, h)
*/
void RBM_contrastive_divergence(RBM* rbm, int *input, double lr, int k)
{
int i, j, step;
double *ph_means = new double[rbm->n_hidden];
int *ph_sample = new int[rbm->n_hidden];
double *nv_means = new double[rbm->n_visible];
int *nv_samples = new int[rbm->n_visible];
double *nh_means = new double[rbm->n_hidden];
int *nh_samples = new int[rbm->n_hidden];
/* CD-k 对比散度contrastive divergence, CD算法*/
//由可见层得到隐藏层样本
RBM_sample_h_given_v(rbm, input, ph_means, ph_sample);
for(step=0; step<k; step++)
{
if(step == 0)
{
//初次Gibbs采样
RBM_gibbs_hvh(rbm, ph_sample, nv_means, nv_samples, nh_means, nh_samples);
}
else
{
//第step次Gibbs采样,马尔可夫转移
RBM_gibbs_hvh(rbm, nh_samples, nv_means, nv_samples, nh_means, nh_samples);
}
}
//更新W, vbias, hbias
for(i=0; i<rbm->n_hidden; i++)
{
for(j=0; j<rbm->n_visible; j++)
{
rbm->W[i][j] += lr * (input[j] * ph_means[i] - nv_samples[j] * nh_means[i]) / rbm->N;
}
rbm->hbias[i] += lr * (ph_means[i] - nh_means[i]) / rbm->N;
}
for(i=0; i<rbm->n_visible; i++)
{
rbm->vbias[i] += lr * (input[i] - nv_samples[i]) / rbm->N;
}
delete ph_means;
delete ph_sample;
delete nv_means;
delete nv_samples;
delete nh_means;
delete nh_samples;
}
/*
由可见层得到隐藏层样本
v0_sample:初始可视层结点状态
h1_mean:隐层结点被激活的概率
h1_sample:将h1_mean映射到0、1
*/
void RBM_sample_h_given_v(RBM* rbm, int *v0_sample, double *h1_mean, int *h1_sample)
{
int i;
for(i=0; i<rbm->n_hidden; i++)
{
//期望,第i个隐藏结点被激活的条件概率
h1_mean[i] = RBM_propup(rbm, v0_sample, i, rbm->hbias[i]);
//通过二项分布采样,将概率映射到0、1
h1_sample[i] = binomial(1, h1_mean[i]);
}
}
/*
由隐藏层重构可见层样本
即,给定隐层结点状态,对可视层结点采样
v0_sample:初始隐层结点状态
v1_mean:可视层结点被激活的概率
v1_sample:将v1_mean映射到0、1
*/
void RBM_sample_v_given_h(RBM* rbm, int *h0_sample, double *v1_mean, int *v1_sample)
{
int i;
for(i=0; i<rbm->n_visible; i++)
{
//期望,第i个可视结点被激活的条件概率
v1_mean[i] = RBM_propdown(rbm, h0_sample, i, rbm->vbias[i]);
//通过二项分布采样,将概率映射到0、1
v1_sample[i] = binomial(1, v1_mean[i]);
}
}
/*
给定可视层结点状态 ,求第i个隐藏结点被激活的条件概率 p(h_i=1|v)
v:随机二值向量
b:第i个隐藏结点的偏置
*/
double RBM_propup(RBM* rbm, int *v, int i, double b)
{
int j;
double pre_sigmoid_activation = 0.0;
for(j=0; j<rbm->n_visible; j++)
{
pre_sigmoid_activation += rbm->W[i][j] * v[j];
}
pre_sigmoid_activation += b;
return sigmoid(pre_sigmoid_activation);
}
/*
给定隐藏层结点状态,求第i个可视结点被激活的条件概率 p(h_i=1|v)
v:随机二值向量
b:第i个隐藏结点的偏置
*/
double RBM_propdown(RBM* rbm, int *h, int i, double b)
{
int j;
double pre_sigmoid_activation = 0.0;
for(j=0; j<rbm->n_hidden; j++)
{
pre_sigmoid_activation += rbm->W[j][i] * h[j];
}
pre_sigmoid_activation += b;
return sigmoid(pre_sigmoid_activation);
}
//一次Gibbs采样
//根据隐藏层来抽样最终得到隐藏层。其过程是h->v->h
void RBM_gibbs_hvh(RBM* rbm, int *h0_sample, double *nv_means, int *nv_samples, \
double *nh_means, int *nh_samples)
{
RBM_sample_v_given_h(rbm, h0_sample, nv_means, nv_samples);
RBM_sample_h_given_v(rbm, nv_samples, nh_means, nh_samples);
}
//重建样本: v->h->v
void RBM_reconstruct(RBM* rbm, int *v, double *reconstructed_v)
{
int i, j;
double *h = new double[rbm->n_hidden];
double pre_sigmoid_activation;
for(i=0; i<rbm->n_hidden; i++)
{
h[i] = RBM_propup(rbm, v, i, rbm->hbias[i]);
}
for(i=0; i<rbm->n_visible; i++)
{
pre_sigmoid_activation = 0.0;
for(j=0; j<rbm->n_hidden; j++)
{
pre_sigmoid_activation += rbm->W[j][i] * h[j];
}
pre_sigmoid_activation += rbm->vbias[i];
reconstructed_v[i] = sigmoid(pre_sigmoid_activation);
}
delete h;
}隐藏层
hidderlayer.h
#ifndef HIDDENLAYER_H
#define HIDDENLAYER_H
#include "utils.h"
typedef struct
{
int N; //训练样例数
int n_in; //输入单元数
int n_out; //输出单元数
double **W; //权重矩阵 W[out_i][in_j]表示输入单元in_j连向输出单元out_i的权重
double *b; //偏置
} HiddenLayer;
void HiddenLayer__construct(HiddenLayer*, int, int, int, double**, double*);
void HiddenLayer__destruct(HiddenLayer*);
double HiddenLayer_output(HiddenLayer*, int*, double*, double);
void HiddenLayer_sample_h_given_v(HiddenLayer*, int*, int*);
#endifhiddenlayer.cpp
#include "hiddenlayer.h"
//构建隐藏层
void HiddenLayer__construct(HiddenLayer* hiddenlayer, int N, int n_in, int n_out, \
double **W, double *b)
{
int i, j;
double a = 1.0 / n_in;
hiddenlayer->N = N;
hiddenlayer->n_in = n_in;
hiddenlayer->n_out = n_out;
if(W == NULL) //输入、输出连接矩阵
{
hiddenlayer->W = new double*[n_out];
for(i=0; i<n_in; i++)
hiddenlayer->W[i] = new double[n_in];
for(i=0; i<n_out; i++)
{
for(j=0; j<n_in; j++)
{
hiddenlayer->W[i][j] = uniform(-a, a);
}
}
}
else
{
hiddenlayer->W = W;
}
if(b == NULL) //偏置
{
hiddenlayer->b = new double[n_out];
for(int i=0; i<n_out; i++)
hiddenlayer->b[i] = 0;
}
else
{
hiddenlayer->b = b;
}
}
//析构
void HiddenLayer__destruct(HiddenLayer* hiddenlayer)
{
for(int i=0; i<hiddenlayer->n_out; i++)
delete hiddenlayer->W[i];
delete hiddenlayer->W;
delete hiddenlayer->b;
}
//得到当前隐藏单元被激活的概率
double HiddenLayer_output(HiddenLayer* hiddenlayer, int *input, double *w, double b)
{
int j;
double linear_output = 0.0;
for(j=0; j<hiddenlayer->n_in; j++)
{
linear_output += w[j] * input[j];
}
linear_output += b;
return sigmoid(linear_output);
}
//由可见层得到隐藏层样本
void HiddenLayer_sample_h_given_v(HiddenLayer* hiddenlayer, int *input, int *sample)
{
int i;
for(i=0; i<hiddenlayer->n_out; i++)
{
sample[i] = binomial(1, HiddenLayer_output(hiddenlayer, input, hiddenlayer->W[i], hiddenlayer->b[i]));
}
}
softmax回归
logisticRegression.h
#ifndef LOGISTICREGRESSION_H
#define LOGISTICREGRESSION_H
#include "utils.h"
typedef struct
{
int N; //训练样例数
int n_in; //输入的单元数
int n_out; //要分成的类别数
double **W; //权重矩阵 W[out_i][in_j]表示输入单元in_j连向输出单元out_i的权重
double *b; //偏置
} LogisticRegression;
void LogisticRegression__construct(LogisticRegression*, int, int, int);
void LogisticRegression__destruct(LogisticRegression*);
void LogisticRegression_train(LogisticRegression*, int*, int*, double);
void LogisticRegression_softmax(LogisticRegression*, double*);
void LogisticRegression_predict(LogisticRegression*, int*, double*);
#endif
logisticRegression.cpp
#include "logisticregression.h"
//构建逻辑回归
void LogisticRegression__construct(LogisticRegression *lr, int N, int n_in, int n_out)
{
int i, j;
lr->N = N;
lr->n_in = n_in; //输入的单元数
lr->n_out = n_out; //要分成的类别数目
lr->W = new double*[n_out]; //权重矩阵
for(i=0; i<n_out; i++)
lr->W[i] = new double[n_in];
lr->b = new double[n_out]; //偏置
for(i=0; i<n_out; i++)
{
for(j=0; j<n_in; j++)
{
lr->W[i][j] = 0;
}
lr->b[i] = 0;
}
}
//析构
void LogisticRegression__destruct(LogisticRegression *lr)
{
for(int i=0; i<lr->n_out; i++)
delete lr->W[i];
delete lr->W;
delete lr->b;
}
//训练,更新权值,偏置参数
void LogisticRegression_train(LogisticRegression *lrg, int *x, int *y, double lr)
{
int i,j;
double *p_y_given_x = new double[lrg->n_out]; //y的预测值
double *dy = new double[lrg->n_out]; //梯度
for(i=0; i<lrg->n_out; i++)
{
p_y_given_x[i] = 0;
for(j=0; j<lrg->n_in; j++)
{
p_y_given_x[i] += lrg->W[i][j] * x[j];
}
p_y_given_x[i] += lrg->b[i];
}
LogisticRegression_softmax(lrg, p_y_given_x);
for(i=0; i<lrg->n_out; i++) //更新参数:权重矩阵、偏置
{
dy[i] = y[i] - p_y_given_x[i];
for(j=0; j<lrg->n_in; j++)
{
lrg->W[i][j] += lr * dy[i] * x[j] / lrg->N;
}
lrg->b[i] += lr * dy[i] / lrg->N;
}
delete p_y_given_x;
delete dy;
}
//softmax
void LogisticRegression_softmax(LogisticRegression *lr, double *x)
{
int i;
double max = 0.0;
double sum = 0.0;
for(i=0; i<lr->n_out; i++)
if(max < x[i])
max = x[i];
for(i=0; i<lr->n_out; i++)
{
x[i] = exp(x[i] - max);
sum += x[i];
}
for(i=0; i<lr->n_out; i++)
x[i] /= sum;
}
//预测
void LogisticRegression_predict(LogisticRegression *lr, int *x, double *y)
{
int i,j;
for(i=0; i<lr->n_out; i++)
{
y[i] = 0;
for(j=0; j<lr->n_in; j++)
{
y[i] += lr->W[i][j] * x[j];
}
y[i] += lr->b[i];
}
LogisticRegression_softmax(lr, y);
}
测试
test.h
#include "time.h"
#include "stdio.h"
#include "stdlib.h"
#include "dbn.h"
#include "string.h"
//测试RBM
void test_rbm(void)
{
srand(time(NULL)); ;
int i, j, epoch;
double learning_rate = 0.1; //学习速率
int training_epochs = 1000; //训练次数
int k = 1;
int train_N = 6; //训练样例数目
int test_N = 2; //测试样例数目
int n_visible = 6; //可视层结点数目
int n_hidden = 6; //隐层结点数目
// training data
int train_X[6][6] =
{
{1, 1, 1, 0, 0, 0},
{1, 0, 1, 0, 0, 0},
{1, 1, 1, 0, 0, 0},
{0, 0, 1, 1, 1, 0},
{0, 0, 1, 0, 1, 0},
{0, 0, 1, 1, 1, 0}
};
// construct RBM
RBM rbm;
RBM__construct(&rbm, train_N, n_visible, n_hidden, NULL, NULL, NULL);
// train
for(epoch=0; epoch<training_epochs; epoch++)
{
for(i=0; i<train_N; i++)
{
RBM_contrastive_divergence(&rbm, train_X[i], learning_rate, k);
}
}
// test data
int test_X[2][6] =
{
{1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 0}
};
double reconstructed_X[6][6];
// test
for(i=0; i<test_N; i++)
{
RBM_reconstruct(&rbm, test_X[i], reconstructed_X[i]);
for(j=0; j<n_visible; j++)
{
printf("%.5f ", reconstructed_X[i][j]);
}
printf("\n");
}
// destruct RBM
RBM__destruct(&rbm);
}
//测试逻辑回归分类器
void test_logisticRegression()
{
srand(time(NULL));
int i, epoch;
double learning_rate = 0.01; //学习速率
int training_epochs = 200; //训练次数
int train_N = 6; //训练样例数目
int test_N = 3; //测试样例数目
int n_in = 6; //输入结点数目
int n_out = 2; //输出结点数目
// training data
int train_X[6][6] =
{
{1, 1, 1, 0, 0, 0},
{1, 0, 1, 0, 0, 0},
{1, 1, 1, 0, 0, 0},
{0, 0, 1, 1, 1, 0},
{0, 0, 1, 1, 0, 0},
{0, 0, 1, 1, 1, 0}
};
int train_Y[6][2] =
{
{1, 0},
{1, 0},
{1, 0},
{0, 1},
{0, 1},
{0, 1}
};
// construct
LogisticRegression lr;
LogisticRegression__construct(&lr, train_N, n_in, n_out);
// train
for(epoch=0; epoch<training_epochs; epoch++)
{
for(i=0; i<train_N; i++)
{
LogisticRegression_train(&lr, train_X[i], train_Y[i], learning_rate);
}
}
// test data
int test_X[3][6] =
{
{1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 0},
{1, 1, 1, 1, 1, 1}
};
double test_Y[3][2];
memset(test_Y, 0, sizeof(test_Y));
// test
for(i=0; i<test_N; i++)
{
LogisticRegression_predict(&lr, test_X[i], test_Y[i]);
for(int j=0; j<n_out; j++)
printf("%.4f\t", test_Y[i][j]);
printf("\n");
}
// destruct LogisticRegression
LogisticRegression__destruct(&lr);
}
//测试深度信念网DBN
void test_dbn(void)
{
srand(time(NULL));
int i, j;
double pretrain_lr = 0.1; //预训练学习速率
int pretraining_epochs = 1000; //预训练次数
int k = 1; //CD算法参数
double finetune_lr = 0.1; //调整学习速率
int finetune_epochs = 500; //调整训练次数
int train_N = 6; //训练样例数
int test_N = 3; //测试样例数
int n_ins = 6; //输入单元数
int n_outs = 2; //输出单元数
int hidden_layer_sizes[] = {3, 3}; //第1层和第2层隐层单元数
int n_layers = sizeof(hidden_layer_sizes) / sizeof(hidden_layer_sizes[0]); //隐层数
// training data
int train_X[6][6] =
{
{1, 1, 1, 0, 0, 0},
{1, 0, 1, 0, 0, 0},
{1, 1, 1, 0, 0, 0},
{0, 0, 1, 1, 1, 0},
{0, 0, 1, 1, 0, 0},
{0, 0, 1, 1, 1, 0}
};
int train_Y[6][2] =
{
{1, 0},
{1, 0},
{1, 0},
{0, 1},
{0, 1},
{0, 1}
};
// 构建 DBN
DBN dbn;
DBN__construct(&dbn, train_N, n_ins, hidden_layer_sizes, n_outs, n_layers);
// 预训练
DBN_pretrain(&dbn, *train_X, pretrain_lr, k, pretraining_epochs);
// 调整
DBN_finetune(&dbn, *train_X, *train_Y, finetune_lr, finetune_epochs);
// test data
int test_X[3][6] =
{
{1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 0},
{1, 1, 1, 1, 1, 0}
};
double test_Y[3][2];
// test
for(i=0; i<test_N; i++)
{
DBN_predict(&dbn, test_X[i], test_Y[i]);
for(j=0; j<n_outs; j++)
{
printf("%.5f ", test_Y[i][j]);
}
printf("\n");
}
// destruct DBN
DBN__destruct(&dbn);
}
test.cpp
#include "test.h"
int main()
{
//test_rbm();
//test_logisticRegression();
test_dbn();
return 0;
}输入:
{1, 1, 0, 0, 0, 0}
{0, 0, 0, 1, 1, 0}
{1, 1, 1, 1, 1, 0}
输出:
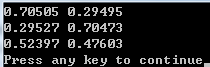
参考资料
Y. Bengio, P. Lamblin, D. Popovici, H. Larochelle: Greedy Layer-Wise Training of Deep Networks, Advances in Neural Information Processing
Systems 19, 2007
http://blog.csdn.net/zouxy09/article/details/8781396/
http://blog.csdn.net/xbinworld/article/details/45274289
http://www.chawenti.com/articles/17243.html
http://blog.163.com/silence_ellen/blog/static/176104222201431710264087/















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









