







使用PyQt5实现UI版YOLOv8双模态检测系统
优点:UI界面直接调用图像和视频检测功能
显示检测结果信息,包含:class、box、conf
视频检测时任意改变conf以及IOU值
1 Pycharm中安装PyQt5及使用Qt Designer设计UI界面
首先使用以下指令在虚拟环境中安装PyQt5
pip install PyQt5 pip install PyQt5-tools
Pycharm外部工具添加三个插件(重点)
打开Pycharm→Setting→Tools→External Tools
点击右上角“+”号,如下图依次添加
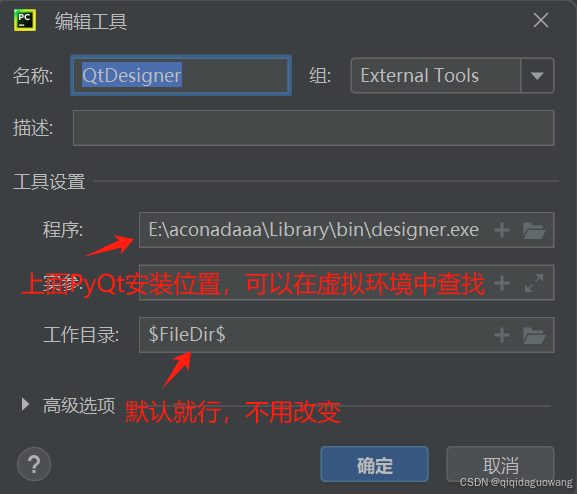
名称:QtDesigner
程序:管理虚拟环境文件夹中查找Designer(忘记路径可以在环境变量→系统变量→Path中查找)
工作目录:$FileDir$
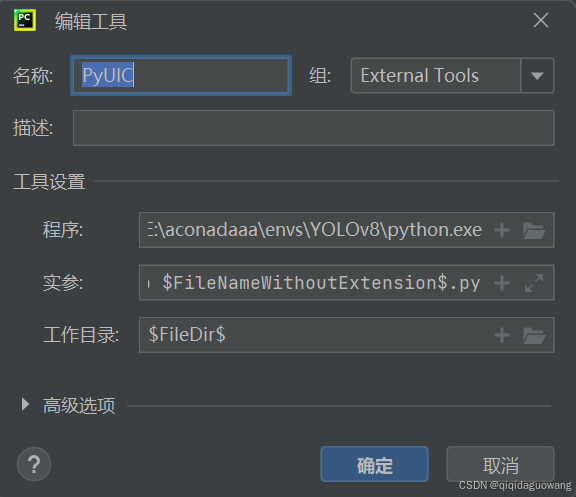
名称:PyUIC
程序:自己创建虚拟环境中查找并添加Python(博主创建环境名为“YOLOv8”)
实参:-m PyQt5.uic.pyuic $FileName$ -o $FileNameWithoutExtension$.py
工作目录:$FileDir$
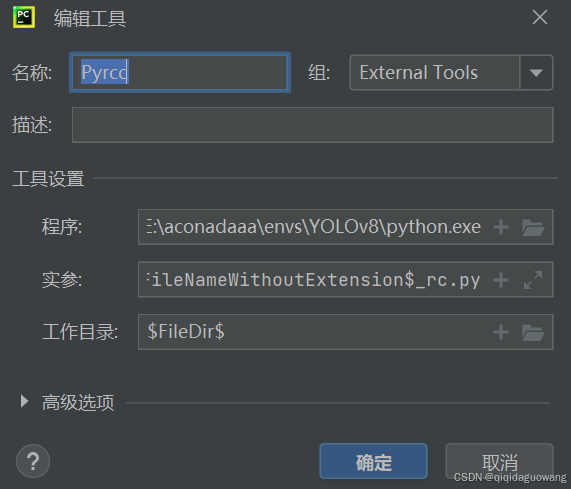
名称:Pyrcc
程序:与PyUIC一致
实参:$FileName$ -o $FileNameWithoutExtension$_rc.py
工作目录:$FileDir$
三个插件安装完成,可参考下面链接安装:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











