







本文参考Hinton2007年发表的一篇论文,链接在此
(一)简介
- 深度信念网是由多层随机潜变量latent variables (“hidden units”)构成的概率生成模型,是一种图模型,或者也可以看作一种深度神经网络。
- 当基于一组样本无监督的训练DBN时,DBN学习去概率性的重构自己的输入信号。When trained on a set of examples without supervision, a DBN can learn to probabilistically reconstruct its inputs.
无监督训练完成以后,再有监督地训练就可以实现分类任务。After this learning step, a DBN can be further trained with supervision to perform classification.
生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation|Label)和 P(Label|Observation)都做了评估,而判别模型仅仅而已评估了后者,也就是P(Label|Observation)。
- 隐层单元是用于学习显层数据中的高阶相关性。
- 最底层单元的状态表示一个数据向量。(the lowest visible layer is a training set)
- 最上面的两层之间有无向的对称连接,形成联想记忆。
- 较低的层从上面的层接收自顶向下的、定向的连接。
DBN的两个最重要的属性:
- 高效的,一层一层的过程,用于学习自顶向下的权重,这些权重决定了一层中的变量如何依赖于上一层中的变量。
- 学习之后,每一层的潜变量的值都可以通过一个自底向上的单遍历来推断,该遍历从底层的一个观察到的数据向量(输入)开始。
深度信念网是通过将一层潜变量的值作为训练下一层的数据来处理的。
这种高效的、贪婪的学习后面可以跟着/结合其他学习过程,微调所有的权重,以提高整个网络的生成或辨别性能。
- 有区分性的好的微调fine-tuning,可以通过添加表示所需输出的最后一层变量和反向传播误差导数来实现。
- 当有许多隐藏层的网络应用于高度结构化的输入数据,如图像,如果隐层的特征检测器是通过学习对图像的结构进行建模的深度信念网来更新的,反向传播就能工作地更好。
(二)深度信念网是由简单的学习模块组成的
- DBN一般由RBM堆叠而成,也可以由自编码器堆叠而成。where each sub-network’s hidden layer serves as the visible layer for the next.
一个RBM:
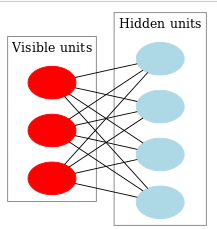
An RBM is an undirected, generative energy-based model with a “visible” input layer and a hidden layer and connections between but not within layers. This composition leads to a fast, layer-by-layer unsupervised training procedure, -
RBM只有两层神经元,第一层是显层,就是输入数据。显层单元的取值代表它们的活跃程度。第二层是隐层,取值/激活状态未知。每层内部无连接。两层之间完全对称连接。在图论里,RBM就是个二部图或完全偶图。
- 当显层单元们的活跃程度已知时,明显隐层单元们是条件独立的,因为他们相互之间没有任何连接,他们的相互关联完全是通过显层单元建立的而显层单元又确定下来了,想象那个图就很好理解的。这时候就可以在分布 P ( h ∣ v , W ) P(h|v,W) P(h∣v,W)中采样出来一个h向量了。
- 然后h确定,v里的单元们也相互条件独立,于是再从
P
(
v
∣
h
,
W
)
P(v|h,W)
P(v∣h,W)中采样出一个v向量。这样反反复复几次,就可以得到一个学习信号。这个信号就是采样开始和结束时显层单元的成对相关和隐层单元的成对相关的差值。
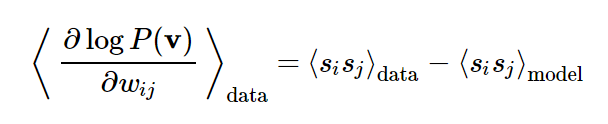
(三)学习过程的理论推导
DBN的关键思想:
RBM学到的权重W能定义隐变量的先验分布 P ( h ∣ W ) P(h|W) P(h∣W)和显变量的后验分布 P ( v ∣ h , W ) P(v|h,W) P(v∣h,W)。因为权重一旦确定了,输入数据v是有的,自然就可以得到h各种取值的概率 P ( h ∣ W ) P(h|W) P(h∣W);而h被采样到后,根据h和W自然可以算出v各种取值的概率。
所以生成显层变量v的概率就是:
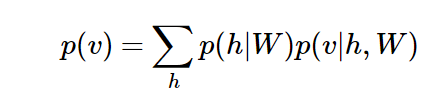
(四)带有其他类型变量的DBN
(五)用自动编码器作学习模块
- 和用RBM作为学习模块堆叠成的深度信念网络非常相近的是用自编码器autoencoder作为基本学习模块module堆叠得到的深层网络,也被称之为深度信念网。所以实际上深度信念网不特指某一种网络,而是泛指网络层数较多的基于概率生成的网络。
- 不管用RBM还是Autoencoder堆叠的DBN,都是用 逐层贪婪训练法来训练学习权重和偏置的。
- 自编码器的原理更好理解,它是直接去尝试复制再现reproduce输入数据,但是它的缺点是对训练数据里的噪声很敏感而且无法去除。RBM的原理是去努力学到有一组特定参数一个网络,使得它生成输入的概率最高,是去建模各种概率分布。















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









