









Hinton神经网络公开课编程题2--神经概率语言模型(NNLM)
注:这只是一个小白做作业的总结感悟,并没有什么高大上的东西,甚至可能很low,错误很多。如果有错误欢迎指正
这周的编程题主要是实现一个神经概率语言模型(
NNLM
),不过基础的大框架都搭好了,需要编程的部分也是以选择题的形式给出的。这都不重要,重要的还是我们要理解这个神经概率语言模型是如何work的,其实这其中最重要的点就是
word embedding
(词嵌入)了。这个模型我看了很长时间,因为我刚开始接触NLP,而且这篇博客只当做个人的笔记,因此其中如有错误之处,还请大家留言指正。
| 模型的基本结构
神经概率语言模型最经典的还是bengio在2001年发表的论文
《A Neural Probabilistic Language Model》
,不过03年又在
JMLR
上发表了同名论文,现在一般都看这一篇。其实最早提出用神经网络训练语言模型的应该是百度
IDL
的徐伟。先来看下这周编程题的神经概率语言模型的基本结构(和
bengio
的论文上的结构有微小的区别)图片来自:
Burak Himmetoglu
:
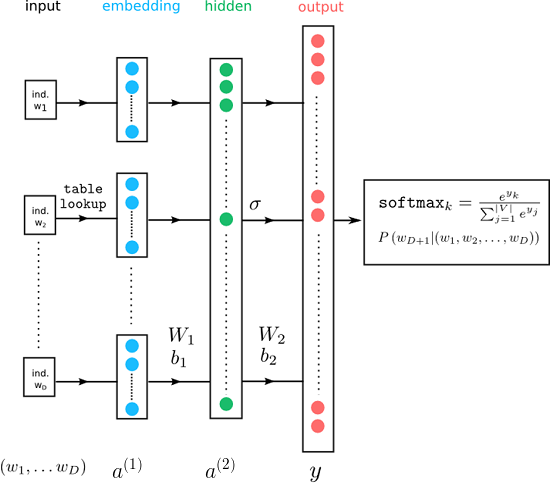
神经概率语言模型可以分为四层,即输入层,
embedding
层,隐藏层,输出层。(也可以分为三层,即把
embedding
层当做输入层,然后隐藏层、输出层,其实在实际操作中实际的输入就是
embedding
层(词向量))。下面就来一层一层的说(还是按照上图的四层来介绍):
1.输入层
输入的单词一般用one-hot编码(关于one-hot编码见博客:
scikit-learn中离散特征二值化
),至于怎么具体的one-hot,我们整个模型首先要拥有一个大小为 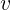 的词表用作字典,然后对于输入的单词去查该单词在词表的位置,比如
it
单词在词表中的位置为
3
,那么
it
的one-hot编码就为
[0,0,1,0....0]
,维度大小和词表大小一样为
的词表用作字典,然后对于输入的单词去查该单词在词表的位置,比如
it
单词在词表中的位置为
3
,那么
it
的one-hot编码就为
[0,0,1,0....0]
,维度大小和词表大小一样为  。但在实际操作中一般不这样做,因为这样的话会导致矩阵比较稀疏,特别是对于大词表来说。更简单的办法是只存该单词在词表中的位置(下标),比如几个单词:
I am a programmer
,在词表中的位置是
2 28 0 6
,只要存这几个下标就行了。然后根据下标去word_embedding矩阵中找对应的行,这个下面编程时会具体介绍。
。但在实际操作中一般不这样做,因为这样的话会导致矩阵比较稀疏,特别是对于大词表来说。更简单的办法是只存该单词在词表中的位置(下标),比如几个单词:
I am a programmer
,在词表中的位置是
2 28 0 6
,只要存这几个下标就行了。然后根据下标去word_embedding矩阵中找对应的行,这个下面编程时会具体介绍。
的词表用作字典,然后对于输入的单词去查该单词在词表的位置,比如
it
单词在词表中的位置为
3
,那么
it
的one-hot编码就为
[0,0,1,0....0]
,维度大小和词表大小一样为
。但在实际操作中一般不这样做,因为这样的话会导致矩阵比较稀疏,特别是对于大词表来说。更简单的办法是只存该单词在词表中的位置(下标),比如几个单词:
I am a programmer
,在词表中的位置是
2 28 0 6
,只要存这几个下标就行了。然后根据下标去word_embedding矩阵中找对应的行,这个下面编程时会具体介绍。
2.embedding层
embedding层实际上是一个矩阵,这个矩阵又叫look-up table。这个矩阵长这个样子,行数为 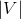 ,就是词表的大小,列数为
,就是词表的大小,列数为 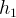 ,即每个词向量的维度,这个维度一般要比one-hot表示的词向量(维度为词表大小)小很多。矩阵的值开始时随机初始化。这样矩阵的每一行就为一个词向量(BP后,每行都是 的实数,后面讲具体怎么得到),可以用来表示一个单词。
,即每个词向量的维度,这个维度一般要比one-hot表示的词向量(维度为词表大小)小很多。矩阵的值开始时随机初始化。这样矩阵的每一行就为一个词向量(BP后,每行都是 的实数,后面讲具体怎么得到),可以用来表示一个单词。
,就是词表的大小,列数为 ,即每个词向量的维度,这个维度一般要比one-hot表示的词向量(维度为词表大小)小很多。矩阵的值开始时随机初始化。这样矩阵的每一行就为一个词向量(BP后,每行都是 的实数,后面讲具体怎么得到),可以用来表示一个单词。
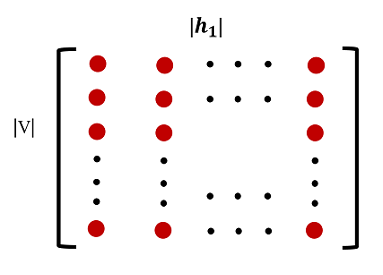
(图片版本所有,任何人不得盗用)
这样做的和one-hot编码相比主要有个两个优点:
- 维度比one-hot编码的维度小,从而起到降维的作用,避免稀疏性
- one-hot编码无法表示语义,因为每个one-hot词向量之间的距离都为
,而word_embedding词向量训练后可以表示语义,即同义词在分布上比较接近(如下图所示,图片来自hinton神经网络公开课,注意观察框起来的单词的意思)。

3.隐藏层
这个没什么好说的,在这个编程题作业用的
sigmoid
函数作为激活函数,bengio的论文中用的
tanh
函数。
4.输出层
|公式推导及编程实现
这块主要讲NNLM模型的参数(权重及如何求得word_embedding中的词向量)的公式推导编程实现。这个编程题的任务是给三个单词首预测第四个单词。先先来对照开始给出的NNLM模型的结构定义一些变量:

公式:
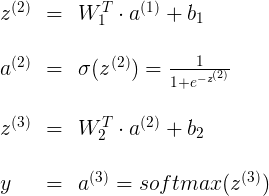
直接来看代码吧:
一些参数的初始化及权重的初始化:

这些参数中,momentum是动量,用于梯度下降中。动量的主要作用为:对于那些当前的梯度方向与上一次梯度方向相同的参数,那么进行加强,即这些方向上更快了;对于那些当前的梯度方向与上一次梯度方向不同的参数,那么进行削减,即这些方向上减慢了。因此可以获得更快的收敛速度与减少振荡。
训练数据存的都是每个单词在词表中的位置:

前三行为(红色框框起来的)为前三个单词,最后一行为需要预测的单词(真实值)。
Forward propagation

先来看下train_input,这个矩阵每列都是三个单词(一个样本),共100个样本,内容与上图类似。前面在讲embedding层的时候说过,给出每个单词的下标,然后去word_embedding矩阵里取对应的行当做这个单词的词向量,然后作为输入。下面是取词向量的代码:

计算 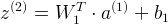 :
:
:

计算  ,顺便说下,这个编程题需要你写代码的地方是以选择题的形式给出的,当时看了好久愣是没明白让干嘛的。。。
,顺便说下,这个编程题需要你写代码的地方是以选择题的形式给出的,当时看了好久愣是没明白让干嘛的。。。
,顺便说下,这个编程题需要你写代码的地方是以选择题的形式给出的,当时看了好久愣是没明白让干嘛的。。。

计算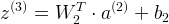 :
:
:

计算 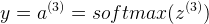 :
:
:

关于注释中根据softmax参数冗余性特点,具体详情见博客:softmax回归(Softmax Regression)。
至于整个前向传播就结束了,下面开始介绍重头戏,介绍bp。
BackPropagation:
先来看损失函数(Loss Function),这里损失函数用的交叉熵(不用平方误差的原因是,对于隐藏层而言,如果预测值和目标值差距过大,会导致梯度几乎为0,这样更新的非常慢)。交叉生损失函数为:
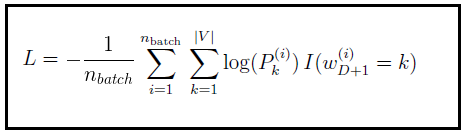
其中 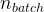 为一次
batch
的样本数量,
V
为词表大小,
为一次
batch
的样本数量,
V
为词表大小,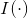 为示性函数,只有当
()
里面的值为真时取1,其他情况均取0。
为示性函数,只有当
()
里面的值为真时取1,其他情况均取0。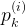 为
第
i
个样本输出类别为
k
的概率,其实就是
softmax
层的输出。因为你的真实目标值要用
one-hot
向量表示,具体这个题目上,比如:
“I am a programmer”
,前三个单词是
I、am、a
,第四个单词真实目标值是
programmer
,在词表中的位置为
6
,那么就用
[0,0,0,0,0,1,0.....0]
(250维)来表示,所以
对于一个样本
而言,
hinton
老爷子给出的交叉熵函数更直白(下面求导的时候就用这个简单版的):
为
第
i
个样本输出类别为
k
的概率,其实就是
softmax
层的输出。因为你的真实目标值要用
one-hot
向量表示,具体这个题目上,比如:
“I am a programmer”
,前三个单词是
I、am、a
,第四个单词真实目标值是
programmer
,在词表中的位置为
6
,那么就用
[0,0,0,0,0,1,0.....0]
(250维)来表示,所以
对于一个样本
而言,
hinton
老爷子给出的交叉熵函数更直白(下面求导的时候就用这个简单版的):
为一次
batch
的样本数量,
V
为词表大小,为示性函数,只有当
()
里面的值为真时取1,其他情况均取0。为
第
i
个样本输出类别为
k
的概率,其实就是
softmax
层的输出。因为你的真实目标值要用
one-hot
向量表示,具体这个题目上,比如:
“I am a programmer”
,前三个单词是
I、am、a
,第四个单词真实目标值是
programmer
,在词表中的位置为
6
,那么就用
[0,0,0,0,0,1,0.....0]
(250维)来表示,所以
对于一个样本
而言,
hinton
老爷子给出的交叉熵函数更直白(下面求导的时候就用这个简单版的):
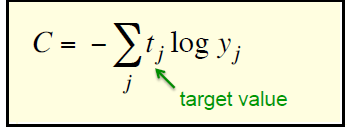
表达方式不同,结构都一样。
实现的代码为:

接下来开始逐层
bp
,
算隐藏层到输出层权重w2的梯度(hid_to_output_weights_gradient):

对应的代码实现:

embedding层到hidden层权重w1的导数(embed_to_hid_weights_gradient):

对应的代码实现:

接下来也许是这个作业的难点了,前面讲过单词要用
embedding
向量表示,这个
embedding
向量是要网络去学习的,刚开始都是随机初始化的,那么网络如何去学习这个词向量。其实这个
word_embedding
矩阵的更新和
w1,w2
的更新在本质上没什么区别,都是损失函数求导。其实对于整个网络而言,真正的输入就是这个词向量,也就是图中的 。同样也是用梯度下降来求得。
。同样也是用梯度下降来求得。
。同样也是用梯度下降来求得。
先看公式:

对应这个公式的代码为:

或者,最本质的还是把每个单词的
one-hot
向量当做输入,这样
input
到
embedding
之间还有一个权重,我们要去学习这个权重:(图片来自台大李宏毅)
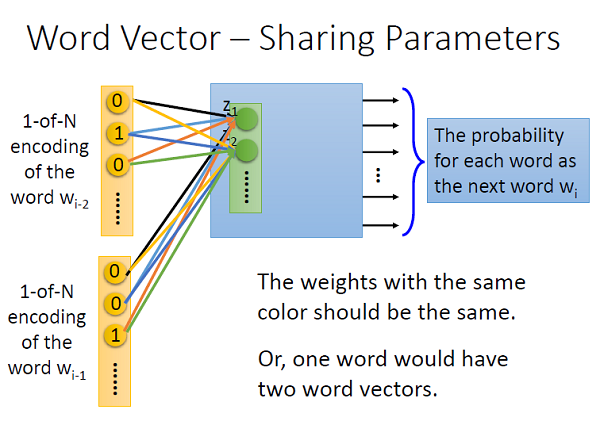
如果我们记这个权重为
C
这个就变成了
embedding
矩阵,大小就为:词表大小*降维后每个词向量大小(在这个例子中是
250*50
)。每对相同颜色的连线代表权重一样,即为权共享。
back_propagated_deriv_2
是一个
150*100
的矩阵,100是
batchsize
的大小,即100个样本。150是3个单词的
embedding
向量拼接在一起的(每个单词用50维向量表示)。这个矩阵的示意图如下:
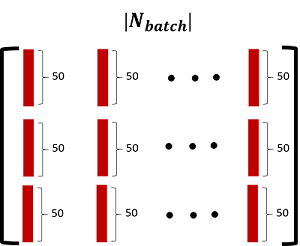
(图片版权所有,未经同意任何人不得盗用)
来看这段代码:

expansion_matrix(:, input_batch(w, :)) 是一个250*100的矩阵,250是词表大小。因为每次batch输入的单词是3*100的矩阵,即每个样本3个单词,共100个样本。w=1时,expansion_matrix(:, input_batch(1, :)) 是input_batch第一行单词对应的one-hot向量。back_propagated_deriv_2(1 + (w - 1) * numhid1 : w * numhid1, :)每次取出上图中50*100的子矩阵(第一个50行*100)。因此这样对应的相乘就能得到相应的单词的embedding向量的梯度。这个相乘可以看做是因为是左行* 右列。可以看到是把相同单词的相同特征(50维的词向量表示词,其中每一个元素可以看做是改词的一个特征。。)因为共3行(3个单词),所以循环三次,循环里的加好的意思是把每次得到的同一个单词的梯度累加(两个矩阵相加对应元素值相加),因为有的高频单词出现的次数多训练的次数也就多。所以整个模型训练完最终得到的250个词每个词的词向量。还是来个示意图说明expansion_matrix(:, input_batch(1, :)) * (back_propagated_deriv_2(1 + (1 - 1) * numhid1 : 1* numhid1, :)')是如何相乘的:
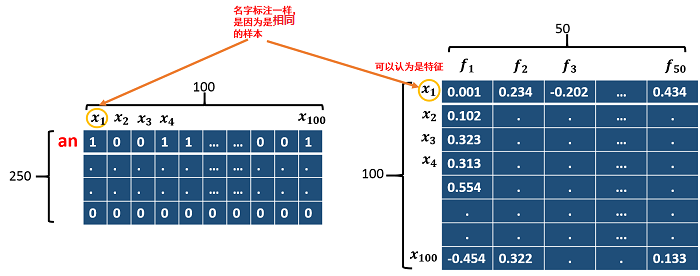
(图片版权所有,未经同意不得盗用)
来看这个题具体的,
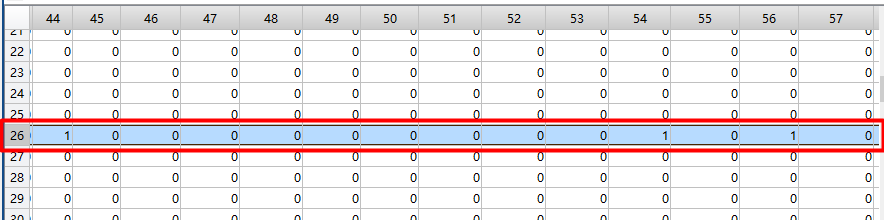
input_batch(1, :):因为100个数据,不能完全截图,我就挑我想要说明的截下:

看在词表中位置是26的单词在batch中的样本位置分别是第44,54,56个。下面再来看expansion_matrix(:, input_batch(1, :)) ,拿出了这100个样本的one-hot编码(一列是一个样本的one-hot编码)。
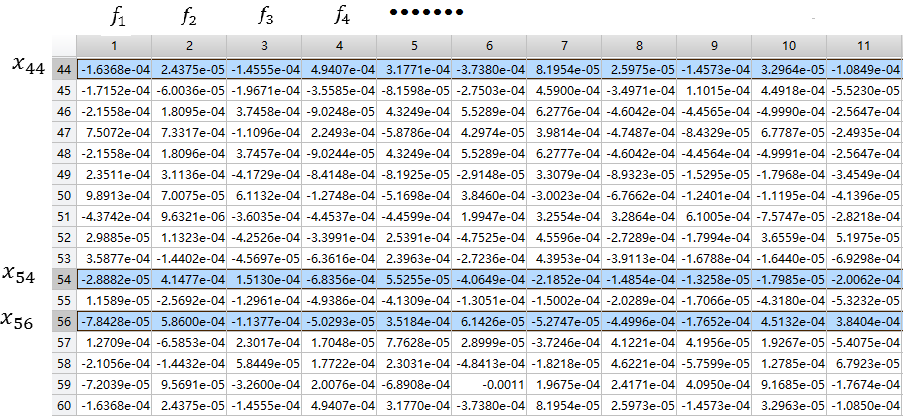
back_propagated_deriv_2(1 + (1 - 1) * numhid1 : 1 * numhid1, :)':
这样
expansion_matrix(:, input_batch(1, :))*back_propagated_deriv_2(1 + (w - 1) * numhid1 : w * numhid1, :)'就得到了这次训练的单词的梯度(出现多次的单词梯度累积),然后三个单词,循环三次,累积下。就得到了这次batch的所有单词梯度。
下面就是更新参数:

对应的代码实现:

最终训练完,会得到整个模型的所有参数:
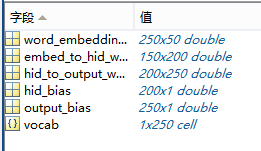
测试一个样例看看效果,"prob"(不是预测的单词)表示下一个是这个单词的概率,给出前三个单词 life in new,显然下一个单词是york的概率是最大的。

再来看看能不能识别出语义(即同义词之间的距离应该小,意思不太接近的词距离应该大):

给定一个单词,输出top-5词义最接近的单词:
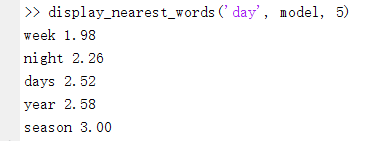
至此,结束。
注:转载请注明作者和原文链接,谢谢















 3474
3474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









