









基本概念
InpuStream/OuputStream(字节输入流/字节输出流),它们都是抽象类,并且都实现了 Closeable 接口,表示所有字节(byte)输入流(输出流)的类。
源码分析
1.InputStream
类结构如下
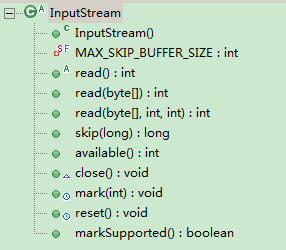
成员变量
// 成员常量,表示 skip(跳跃、丢弃)操作时能丢弃的最大数量
private static final int MAX_SKIP_BUFFER_SIZE = 2048;构造函数,它有一个默认的无参造函数。
read 方法,定义了三个 read 方法,代表不同的读取方式。
① 是一个抽象方法,留给子类实现。
② 通过调用 ③ 实现。
③ 的实际操作依靠 ① 来完成。
// ①从输入流中读取数据的下一个字节
public abstract int read() throws IOException;
// ②从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
// ③将输入流中最多 len 个数据字节读入 byte 数组
public int read(byte b[], int off, int len) throws IOException {
// 校验参数的合法性
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
// 先读取一个字节,用来判断是否到流的末尾。若是,返回 -1
int c = read();
if (c == -1) {
return -1;
}
// 将上面读取的一个字节的值添加进数组
b[off] = (byte) c;
int i = 1;
// 继续读取流,直到 len 或 流末尾
try {
for (; i < len; i++) {
// 实际通过 read 来进行操作
c = read();
if (c == -1) {
break;
}
// 字节存放的位置从 off 开始
b[off + i] = (byte) c;
}
} catch (IOException ee) {
}
return i;
}skip 方法,它表示跳跃,丢弃操作。
它可以跳过(丢弃)指定数量的字节,然后再继续读取流。
它实际上通过 read 方法来进行跳跃操作,然后创建了一个字节数组用来保存被丢弃的字节。
public long skip(long n) throws IOException {
long remaining = n;
int nr;
// 如果 n 为 0,表示不进行跳跃(丢弃)操作。
if (n <= 0) {
// 关键 -->返回值为 0 ,说明有 0 个字节被丢弃
return 0;
}
// 最多只能丢弃 2048 个字节
int size = (int) Math.min(MAX_SKIP_BUFFER_SIZE, remaining);
// 创建数组用来保存被丢弃的字节
byte[] skipBuffer = new byte[size];
while (remaining > 0) {
// 关键 --> 通过 read 方法完成该操作
nr = read(skipBuffer, 0, (int) Math.min(size, remaining));
// 如果进行该操作时,提前到达流末尾,则不再继续
if (nr < 0) {
break;
}
// 表示剩余需要丢弃字节的数量
remaining -= nr;
}
return n - remaining;
}剩余方法,大多没有具体的实现,都留给子类做扩展,这里先不细说。
// 返回流中剩下可读取的字节数量,默认返回 0
public int available() throws IOException {
return 0;
}
// 关闭流操作,空方法,留给子类实现
public void close() throws IOException {
}
// 标记操作,空方法,留给子类实现
public synchronized void mark(int readlimit) {
}
// 释放标记,与 mark 配套使用
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
// 判断是否支持标记,默认不支持
public boolean markSupported() {
return false;
}2.OutputStream
类结构如下
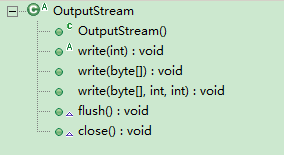
构造函数,它有一个无参的构造函数
write 方法,同样有三种写入方式。
① 是一个抽象方法,留给子类实现。
② 通过调用 ③ 实现。
③ 的实际操作依靠 ① 来完成。
// 将指定的字节写入此输出流(抽象方法)
public abstract void write(int b) throws IOException;
// 将 b.length 个字节从指定的 byte 数组写入此输出流
public void write(byte b[]) throws IOException {
write(b, 0, b.length);
}
// 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流
public void write(byte b[], int off, int len) throws IOException {
// 校验参数的合法性
if (b == null) {
throw new NullPointerException();
} else if ((off < 0) || (off > b.length) || (len < 0) || ((off + len) > b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
// 将数组中的所有字节内容写入流
for (int i = 0; i < len; i++) {
write(b[off + i]);
}
}剩余方法
//将缓存中流的内容强制输出到目的地
public void flush() throws IOException {
}
public void close() throws IOException {
}原理解释
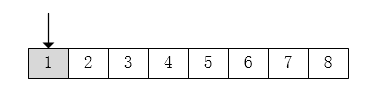
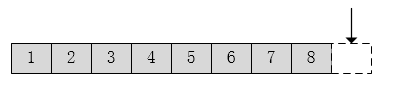
1. 按字节读取
假设下面代码一段字节流

当字节输入流按字节读取时,即 read():
- 读取第一个字节,返回值1。
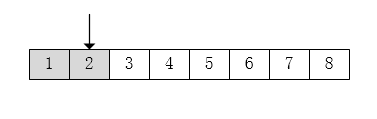
- 读取第二个字节,返回值 2.
- 读取到最后,发现已经到达流末尾了,返回 -1。
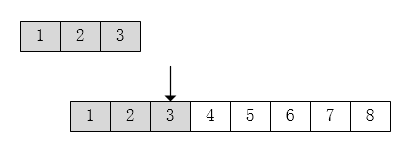
2.按字节数组读取
假设字节数组的大小为 3,即 read(buffer,0,3):
- 它会先读取 1 个字节用于判断流是否达到末尾,并将值放入数组的第一个位置(n =0)。

- 然后按照循环(n<3)来读取,并将值添加数组
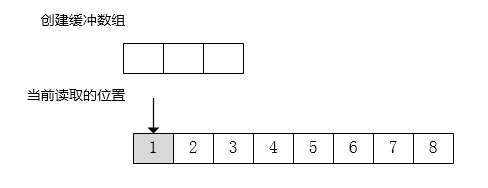
3.跳跃操作
假设现在跳跃的个数为 3。
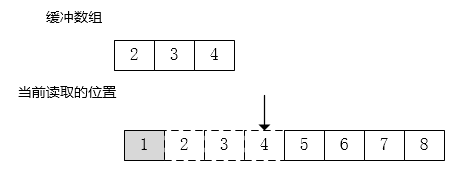
将丢弃的字节添加进缓冲数组。















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











