







注:本文中所有公式和思路来自于李航博士的《统计学习方法》一书,我只是为了加深记忆和理解写的本文。
开场直接套用《统计学习方法》中的一段话:
提升方法有两个问题需要回答:一是在每一轮的学习中如何改变样本的权值,二是如何将弱分类器组合成一个强分类器。第一个问题我的理解就是每一轮学习之后,对于误分的样本在下一轮学习中给予更高的权重,更加关注。第二个问题的答案是对于分类误差小的分类器给予更高的权值,使其在表决中的作用更大,分类误差大的分类器给予更小的权值。就是这么的简单思想,但那时请务必注意这两个问题,一个是针对每一个样本的权值,一个是针对每一个分类器的权值,不要混淆。
算法描述:
输入:训练数据集:
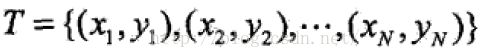
其中,
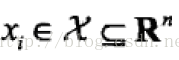
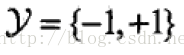
;弱学习算法。
输出:最终分类器G(x).
(1):初始化样本的权值分布:
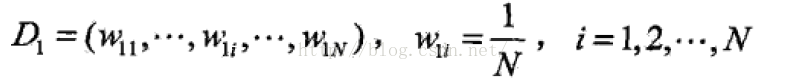
(2):对于m=1,2,3...M
(a):使用具有权重分布Dm的训练数据集合学习,得到基本分类器:
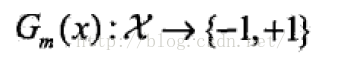
(b):计算G(x)在训练数据集合上的误差率:
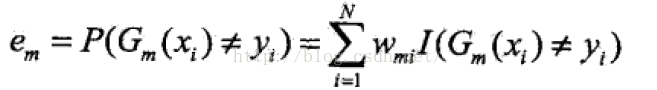
(c):计算G(x)的系数:
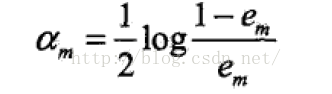
(d):更新训练数据权重分布:
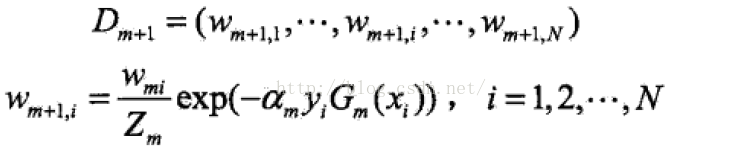
其中Z为归一化因子,可以是Dm成为一个加和为1的概率分布:
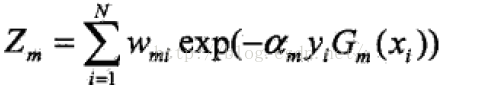
(3):构建分类器的线性组合:
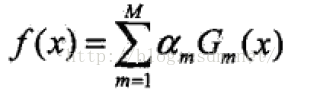
得到在最终的分类器:
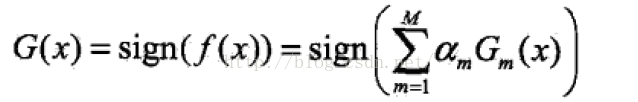
对AdaBoost算法的解释如下:
步骤(1): 假设训练数据集初始权重相同,学习得到G1(x)
步骤(2): AdaBoost反复学习基本分类器,从m=1,2...M中的每一轮顺序的执行下列操作:
(a): 使用当前的分布Dm加权的训练数据集,学习基本分类器Gm(x)
(b): 计算Gm(x)在加权的训练集上的错误率:
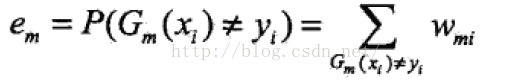
Wmi是值第m轮中第i个样本的权值,所有权值加起来为1,因此Gm在加权训练数据集上的分类错误率等于被分类器Gm误分的样本权值之和。
(c): 计算基本分类器Gm的系数αm,αm表示Gm在最终分类器中的重要程度,可以根据公式得出,当αm≤0.5,αm≥0,并且αm随着em的减少而增大,所以分类误差越小的分类器在表决中起到的着用越大。
(d): 更新训练数据集的权值分布,为下一轮准备:
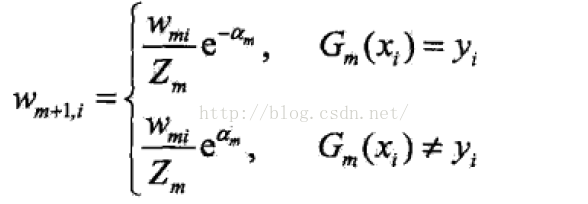
从这个公式中不难看出,如果分类错误,样本的权值就会加大。
步骤(3): 线性组合f(x)实现M个基本分类器的加权表决,其中αm为基本分类器在表决中起到的重要性,并且αm的加和不为1,这就意味着正例可能会正很多,负例可能会负很多,使得分类器的确信度更好。
到此,AdaBoost算法就介绍完了,推荐学者参考《统计学习方法》中的案例加深理解。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









