







注:本文中所有公式和思路来自于邹博先生的《机器学习升级版》,我只是为了加深记忆和理解写的本文。
PCA往往应用在去噪、降维方面,在数据规模很大的时候,往往问题的复杂性就提高了,我们可以考虑将多个特征综合为少数几个代表性特征:即能够代表原始特征的绝大多数信息,组合后的特征又互相不相关,降低相关性,那么就是可以认为这些特征是主成分。
对于n个特征的m个样本,将每个样本写成行向量,得到矩阵A:
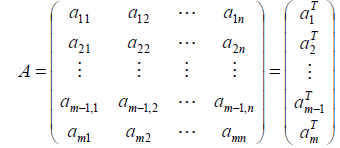
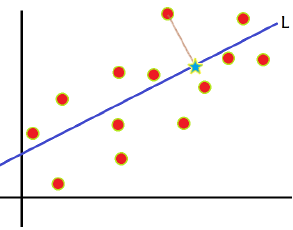
我们首先看一幅图:
寻找样本的主方向u:
将m个样本值投影到某个直线L上,得到m个位于直线L上的点,计算m个投影点的方差,认为方差最大的方向是主方向。
我们不妨来看一下,如果我们以x、y轴来计算这些样本点的话,方差不会很大,如果我们以L这条线作为轴,计算方差的话,那么就大的多了,当然了,前提是我们已经对样本数做过中心化处理,也就是去均值。
接着我们取投影直线L的延伸方向u,计算A*u的值:
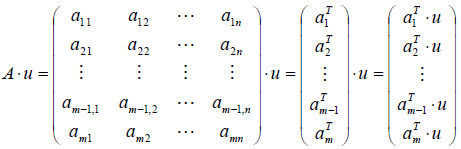
现在求一下向量A*u的方差:
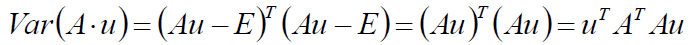
建立目标函数:
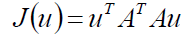
建立拉格朗日函数:
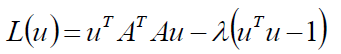
对u求偏导:
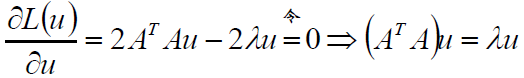
沿着梯度优化,直至收敛。
以上即为PCA的核心推导过程。
那实际中的算法过程是什么样的呢?
PCA算法描述:
1: 将原始数据按列组成n行m列矩阵X
2: 将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3: 求出协方差矩阵
4: 求出协方差矩阵的特征值及对应的特征向量
5: 将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6: Y=PX即为降维到k维后的数据
PCA比较简单,在去噪降维方面用的很广泛。















 5336
5336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









