









同样是Facebook AI Research的文章,是2016年7月新出的文章。下面我们来看一下。
简介与思想:
目标分割主要要求目标级别的信息+像素级别的信息。但是对于前馈网络来说,卷积网络中下层获取了大量的空间信息,而顶层主要由目标水平的信息组成,在姿势和外形变化时不能达到很好的效果。本文主要提出一种自上而下的refinement方法来增强前馈网络以更好分割的方法。该方法与DeepMask网络结合,取得了优秀的实验结果,取名为SharpMask方法。
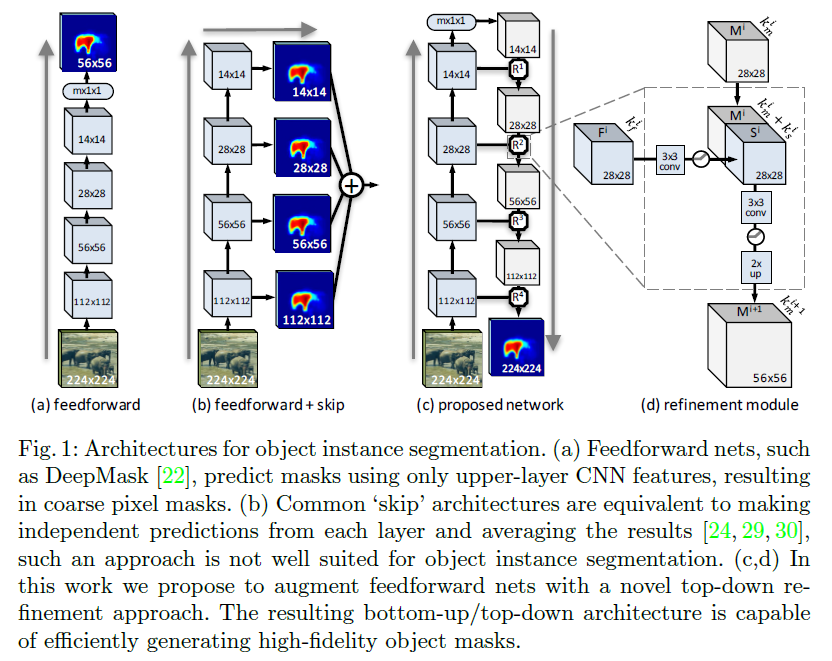
常见的object instance segmentation结构如下图。
(a):仅仅使用上层CNN特征预测mask;
该方法下产生粗略的目标mask很容易,但是很难产生像素级别精度的分割结果。
(b):每一层都得到一个独立的预测值,进行平均得到最终预测值,即skip 结构;
对于需要pixel-labeling tasks的问题使用,如语义分割,边缘检测。但是该方法在目标分割问题中区分不同目标个体是十分必要的,而仅仅使用local receptive fields是不够的,例如羊毛可以被标记成羊毛,但是没有目标级别的信息,很难判断其是哪种动物。
(c)&(d):后面的方法即为本文作者提出,增强前馈网络+top-down refinement方法。
本文提出的方法将low-level特征和high-level目标信息结合,首先在feedforward manner中产生粗略的mask encoding,即用多通道语义特征图产生,然后从earlier layers的完整信息中进行一系列refine,如图中所示,成为refinement module,用栈堆连接这些module形成一个top-down的refinement process。每一个refinement模块通过在top-down pass中产生mask encoding和在bottom-up pass中匹配特征来转化pooling的效果,直到存储了full resolution并且输出整个目标mask为止。
除此之外,其他类似问题的技术可以分类如下:
Multiscale architectures: 通过图像的multiple rescaled versions计算特征。特征在各个尺寸上得到,或者一个尺寸的输出被作为另一个尺寸下结果的额外的输入。本文采用的方法与此类似,但是不需在每一个scale上得到特征。
Deconvolutional networks: 通过CNN中转化pooling进程的过程,产生输入图像。该方法在语义分割中取得了极大成功。但是“switches”与特征值比限制了信息的transfer。
Graphical model networks: 在语义分割同样产生优秀结果,但是在多proposal图像中速度太慢。
SharpMask方法提高了segmentation mask的质量,结合DeepMask方法在COCO数据集中产生的proposal的AR提升了10-20%。对速度进行优化后,每张图片平均时间仅0.76s,提升了两倍。在加速的模型中,使用了图像尺寸的限制,速度可达0.46s,同时对于小目标的recall大大提高。同时,SharpMask方法也可以提高Fast RCNN结果。
The novel top-down refinement network:
本文的目标是将低维特征+高维语义信息结合。主要思想:
(1)object-level信息在目标分割上是必要的;
(2)在已有object-level信息基础上,segmentation应该自顶向下产生,从earlier layer上整合信息;
(3)该方法应该转化pooling带来的损失(主要从output和input匹配解决)。
本文使用的方法中,re finement module就是负责转化pooling损失的,图中用R表示,每一块Ri对应一个mask encoding:Mi。通过bottom-up pass产生的匹配特征Fi,学习合并得到新的upsampled object encoding:M(i+1).
即: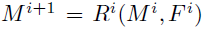
具体来说,每一个refi nement module(Ri)合并粗略的mask(Mi)+从对应层得到的特征(Fi),这里的Fi使用该层pooling层对应的最后一个卷积层。在结构上,M和F具有相同的维度,R模块的目的就是使得mask:M(i+1)有M,F两倍的维度。其中,有几个pooling层就对应几次迭代,知道特征图feature map与input维度一致。
由于mask(Mi)的通道km往往远小于Fi的通道kf,简单的相加结合是不合适的。因此对通过3*3的卷积模块+ReLU来减少kf,得到适合合并的通道数ks。最终,结合Mi和Si得到一个有km+ks通道的feature map,并应用另一个3*3的卷积+ReLU,降采样后即可得到新的mask encoding:M(i+1)。
Training主要包括2个stage:
(1)训练一个coarse pixel-wise segmentation mask+object score,模型
(2)不动feedforward path,训练refinement模块。
Feedforward Architecture
虽然文章重点在mask refinement,作者还是对两种设计的feedforward网络类型下,产生精确目标mask的能力进行了讨论,主要讨论了the network `trunk' and `head'.
trunk部分作者详细描述其细节,这里不再赘述。而对于head结构文章尝试了几种不同类型的结构,如下图:
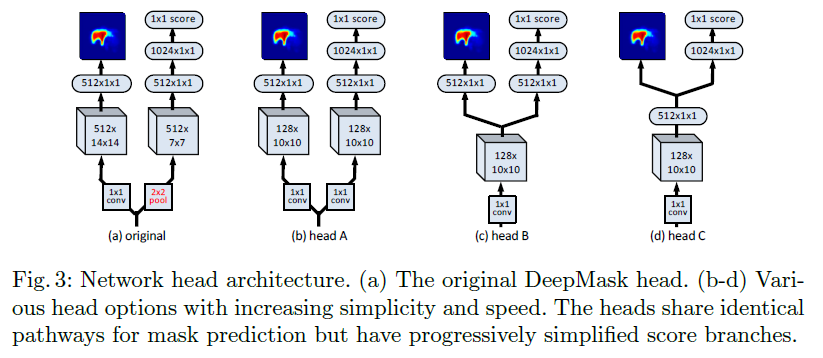
head部分,作者尝试了一系列简化的网络结构使得部分branches共享计算,在实验部分分别进行了各方面的对比。
下面来关注一下这篇文章的实验部分,实验部分该文章提出的方法SharpMask是与DeepMask代码结合一起完成的目标检测实验,主要在COCO数据集上训练和检测,通过IoU(预测mask和ground truth)评价精度。本文的结果具体通过计算10,100,1000个proposal下的AR和averaged across all counts (AUC)来评价。
其中,在学习率1e-3情况下进行训练,在Tesla K40m GPU上需要2天的时间。实验部分结果如下图:(其他更多实验分析与对比请参照原文)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









