










在TLD(Tracking-by -Detection)算法中,多目标跟踪问题里用之前的跟踪目标学习到的特征,直接对新的视频进行跟踪,一直是一个巨大的难点。本文作者将在线的多目标跟踪问题规划成一个Markov Decision Processes(MDP)中的决策,将每一个目标建立一个MDP模型,来进行解决。在MDP中,学习一个policy主要涉及学习相似数据的关联性,policy learning主要使用强化学习的方法,更有利于离线数据和在线数据之间的关联性。同时,本文的方法对于目标的产生和消失,主要看做是MDP中的状态迁移来完成。实验证明,MDP_Tracking方法在MOT比赛上效果良好。
Related Work
1)Multi-Object Tracking
在通过学习进行跟踪的算法中,大部分算法的目标都是通过训练数据,学习到一个反映数据关联性的相似性函数,而本文的突出贡献这是在多目标跟踪中通过增强学习算法学习数据关联性。
2)Online Single Object Tracking
在单目标跟踪算法中,大部分都是在线学习对于目标的外形描述的模型,并用该模型进行跟踪。而在多目标跟踪中,场景中目标还没有出现等情况的存在,使得该方法较难运用。本文的方法通过MDP对一个目标的整个出现时间阶段建模。
3)MDP in Vision
马尔科夫决策过程在CV中运用广泛,如识别中的特征提取,行为预测,人机协同等。MDP主要在需要一系列决策和执行行为的任务的动态环境下表现突出。本文中将目标跟踪看做MDP的任务,通过增强学习学习到MDP的policy,并用多个MDP去跟踪多个目标。
MDP Tracking 算法主要框架
1、Markov Decision Process
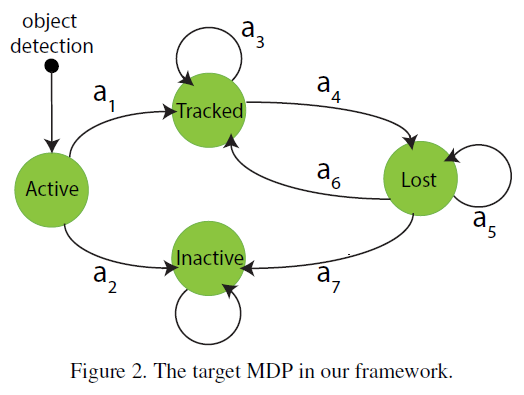
s定义目标的状态(state),a定义目标的动作(action),状态转移函数T描述任何一个状态下一个动作的影像,实值奖励函数R描述将动作a在状态s下的执行的实时奖励。
State:
在MDP中,主要划分4个状态子空间,即S状态包含Active,Tracked,Lost,Inactive四个状态空间,每个子状态空间都记录了目标特征信息,包含目标外形,位置,大小和历史等。上图展示了四个子空间的转移过程。“Active”是每个目标的初始状态,当目标被目标检测算法检测出来,即进去“Active”状态。该状态可以转移到“Tracked”或“Inactive”状态,目标检测出来的true positive进入“Tracked”状态,而false alarm进入“Inactive”状态。被跟踪的目标可以继续被跟踪,或者进入“Lost”状态,如离开视野时。“Lost”状态的目标可以保持该状态,也可以因为再次出现转移到“Tracked”状态,或者因长时间未出现一直处于lost而转移到“Inactive”状态。所有目标的最终状态为“Inactive”状态,该状态只能保持不能转移。
Actions and Transition Function:
如上图中定义了7种动作(action),也分别对应的定义了7种可能的转移函数。在MDP中,给定当前状态和一个动作,即可给出目标新的状态。
Reward Function:
本文中使用的MDP通过训练样本自主学习得到奖励函数。
2、Policy
在MDP中,policy是一个状态S到动作A的映射,即: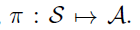
1)Policy in an Active State
在Active状态s下,MDP在目标检测出来的结果转移到tracked和inactive状态之间决策。目标检测中的非极大值抑制和检测分数的阈值在这里被利用。本文使用SVM来分类检测结果是进入tracked还是inactive状态,其中SVM使用5维特征向量,包括2维坐标、宽、高和检测的分数。训练样本来自训练视频。学习Active的奖励函数的方法如下:

w和b定义SVM的超平面,y(a)取1或-1,当a=a1时取1,a=a2时取-1。主要到这里,当目标检测存在错误时候,这里也会被错分类并转移成tracked状态,但是MDP的tracked和lost状态部分会进行处理。
2)Policy in a Tracked State
在Tracked状态,主要决定继续track还是lost。只要目标还在视野中,就应该继续track。类似其他单目标跟踪中的决策方法,本文建立一个基于外形(appearance)的目标在线跟踪模型来跟踪目标。该基于外形的模型只要还能在其他视频中track到目标,就继续保持tracked状态。这里的模型来自于多个其他方法的组合,在TLD tracker的基础上进行implementation。
Template Representation:目标外形简单地用视频流中的目标图片patch代表。在目标检测过程跟踪到目标,就用一个bounding box初始定义目标,如下图是一个行人的模板形成过程(a图是目标模板,文章的算法通过密集点计算模板与新的帧的光流结果,进一步用于决策,b图是一个稳定预测的例子,c图是一个不稳定预测的例子)。当目标被跟踪,MDP收集跟踪中的patch作为目标的history,来在判断目标是否lost时候使用。

Template Tracking:为了通过目标模板进行跟踪,主要通过密集均匀点计算光流结果。对于跟定的模板和其上的点,通过基于影像金字塔的迭代Lucas-Kanade方法计算光流,通过前向后向光流错误来进一步得到预测结果。由于模板检测可能存在错误,仅仅通过光流法是不稳定的,这里假设false alarm不能稳定地被长时间检测,因此如果一个tracked模板不能被检测算法检测出一段时间,则认为很可能是false alarm。最终定义的奖励函数的表达式如下:
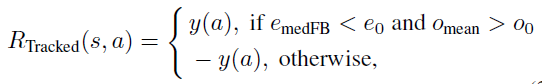
Template Updating:描述目标的外形模板需要更新。本文的检测在跟踪的过程中实时更新,通过“lazy”更新原则,借助检测结果来进行修正。当template没能检测到时,目标状态转移到lost状态。当目标从lost状态再次转移到tracked时,template用关联的检测处结果替代。
3)Policy in a Lost State
在lost状态下,MDP需要决定下一步状态是lost还是tracked还是inactive。在目标多于阈值的帧数下依然lost时候,将其转入inactive。当目标与检测的结果关联时,将其转移到tracked状态。其余情况依然属于lost状态。
Data Association:对于一个处于lost状态的目标t,数据关联的关键是找到目标和检测结果d是否关联。

(w,b)是控制函数的参数,当a=a6时,y(a)=1;当a=a5时,y(a)=-1。在lost阶段的policy学习的目标,就是来学习到决策函数中的参数(w,b)。
Reinforcement Learning:在MDP中,本文通过增强学习方法训练binary classifier。文章初始化权重(w0,b0)开始训练,并设置二类分类器的训练样本为空。这里的二类分类器值在MDP犯错时候进行更新,其主要增强学习算法流程如下:

Feature Representation:文章主要设计特征向量描述目标t和检测结果d的相似性。目标在历史K个视频流中出现被K个templates代表,通过光流法判断每个template和检测结果的相似性,后面通过光流结果加入bbox的相似性来作为特征。
3、Multi-Object Tracking with MDPs
在之前介绍的MDP的policy/reward的基础上,作者将其应用在多目标跟踪问题中。对于一个新的输入视频流,在tracked状态的目标首先确定是继续tracked还是进入lost状态。然后对于lost目标和目标检测结果计算相似性,获得相似性分数,进一步判断目标和lost目标的分配问题。针对该分配结果,一部分能够和检测结果关联的lost状态的目标转移到tracked状态,剩下的继续保持lost状态。最终,对于每一个没有被跟踪的检测结果初始化一个MDP。
实验
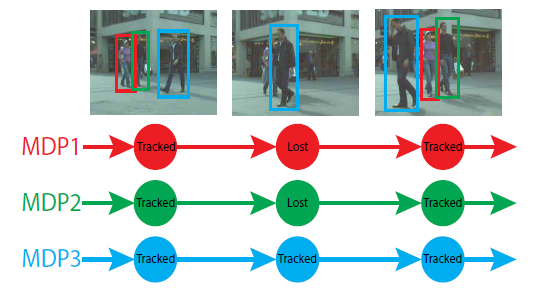
数据集采用MOT比赛数据集,主要涉及行人的跟踪,从结果看该方法在多目标跟踪方面优秀,结果示意如下:
















 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









