









1、准备正负样本
首先需要对自己要训练的样本进行准备。样本的准备主要分为两部分:样本+样本描述文件。这里的样本为机器学习类样本,类似imagenet比赛的分类数据样本,一张一张图直接是一个个截取的目标。正样本最好统一大小,尽量resize到比较小的分辨率,训练时候更快消耗内存更少。
我这里由于是现有Faster RCNN训练下的样本,有图片和其对应目标位置的xml文件,因为针对xml文件,编写MATLAB程序读取目标位置并截图,获得正样本。(记录一下,非此类样本的直接略过)
foldername=dir('image');% 用于打开图片所在文件夹
n=1;%记录机器学习样本数
for i=1:2:length(foldername)-2
imagename=strcat('image\',foldername(i+2).name);% 读取子文件夹的名字和路径
im=imread(imagename);
filename=strcat('image\',foldername(i+3).name);% 读取子文件夹标签,txt格式
xmlDoc = xmlread(filename, '%s');
bbox_array = xmlDoc.getElementsByTagName('bndbox');
n_object=bbox_array.getLength();%找到bbox有几个
for j=1:n_object
bbox = str2num(bbox_array.item(j-1).getTextContent());
rect=[bbox(1),bbox(2),(bbox(3)-bbox(1)),(bbox(4)-bbox(2))];%x1,y1,x2,y2->x1,y1,w,h
im2 = imcrop(im,rect);
imwrite(imresize(im2,[64,64]),strcat('result2\',num2str(n),'.jpg'));%保存64*64大小
n=n+1;
end
end获得正负样本图片后,生成样本描述文件,均用txt保存即可。其中,正负样本描述文件格式分别如下:
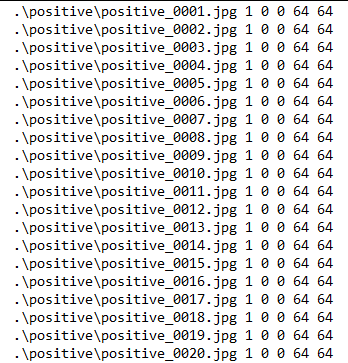

左边正样本每行为:图片路径+该图正样本个数+正样本的位置x、y+正样本的宽和高w、h;右边负样本只需要保存负样本图片路径。具体windows下可以在控制台语句 dir imgDir /b > filename.txt 产生路径,ctrl+F 替换 jpg 成 jpg 1 0 0 64 64 方式修改后面完成描述文件。
2、拷贝所需程序
在opencv的安装路径里找到训练所需程序,如D:\opencv2.4.9\build\x64\vc12\bin文件夹(该文件夹在安装opencv时候应该已经配置到了系统环境变量)里,找到所需exe: opencv_createsamples.exe,opencv_traincascade.exe 拷贝到样本描述文件所在的文件夹里,现有文件夹里文件如下:

positive文件夹存放正样本数据,negative文件夹存在负样本数据,两个txt分别为描述文件。
3、生成正样本.vec文件
在该文件夹内shift+鼠标右键,点击“在此处打开命令窗口”,打开控制台cmd,运行opencv_createsamples.exe,生成训练所需要的vec格式的文件。运行参数示例如:
opencv_createsamples.exe -info positive.txt -bg negative.txt -vec pos.vec -num 2000 -w 64 -h 64具体opencv_createsamples函数参数(转自http://www.cnblogs.com/panxiaochun/p/5345412.html):
<-vec> 输出文件,内含用于训练的正样本;
<-img> 输入图像文件名(例如一个公司的标志);
<-bg> 背景图像的描述文件,文件中包含一系列的图像文件名,这些图像将被随机选作物体的背景;
<-num> 生成的正样本的数目;
<-maxxangle> X轴最大旋转角度,必须以弧度为单位;
<-maxyangle> Y轴最大旋转角度,必须以弧度为单位;
<-maxzangle> Z轴最大旋转角度,必须以弧度为单位;
<-w> 输出样本的宽度(以像素为单位);
<-h> 输出样本的高度(以像素为单位)。
4、训练分类器
采用opencv_traincascade函数训练分类器,这里本来是打算采用opencv_haarTraining训练器,然而其在opencv2.4.9里面还有,2.4.10后就没有了,而opencv_traincascade一直存在并且特征可选择。利用opencv_traincascade的运行命令如下:
opencv_traincascade.exe -data data -vec pos.vec -bg negative.txt -numPos 800 -numNeg 500 -featureType HOG -w 64 -h 64 -numStages 20其中的-data指定生成的分类器xml存储文件夹名字,-bg指定负样本描述文件,-vec是指定前面输出vec文件的文件名,-numPos表示每级分类器训练时所用到的正样本数目,-numNeg表示每级分类器训练时所用到的正样本数目,-featureType指定训练使用HOG特征,-w和-h分别指正样本的宽和高,-numStages表示训练分类器的级数。这里注意:每级分类器训练时所用到的正样本数目,应小于vec文件中正样本的数目,具体见下面参数。
具体opencv_traincascade函数参数(转载自:http://blog.csdn.net/quincuntial/article/details/50436699):
<-data> 训练的分类器的存储目录;
<-vec> 正样本文件,由open_createsamples.exe生成,正样本文件后缀名为.vec;
<-bg> 负样本说明文件,主要包含负样本文件所在的目录及负样本文件名;
<-numPos> 每级分类器训练时所用到的正样本数目,应小于vec文件中正样本的数目,具体数目限制条件为:numPos+(numStages-1)*numPos*(1-minHitRate)<=vec文件中正样本的数目;
<-numNeg> 每级分类器训练时所用到的负样本数目,可以大于-bg指定的图片数目;
<-numStages> 训练分类器的级数,强分类器的个数;
<-precalcValBufSize> 缓存大小,用于存储预先计算的特征值,单位MB;
<-precalcIdxBufSize> 缓存大小,用于存储预先计算的特征索引,单位MB;
<-baseFormatSave> 仅在使用Haar特征时有效,如果指定,级联分类器将以老格式存储。5、训练

训练的过程可以随时停止,重新训练时,训练器会读取之前的参数,从停止的地方开始。训练中和训练完成可以看到-data文件夹下的产生的文件,打开可以看到stage中的参数等。
















 2578
2578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









