









散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位。
散列表通过将数据的关键值经过散列函数处理得到值即为散列表中对应的散列数组下标。
为了使用除法散列函数,在计算f(k)之前,需要把关键字转换为非负整数。C++的STL中的模板类hash<T>是实现散列的专业版。
template <class K> class hash;
template<>
class hash<string>
{
public:
size_t operator()(const string theKey) const
{// Convert theKey to a nonnegative integer.
unsigned long hashValue = 0;
int length = (int) theKey.length();
for (int i = 0; i < length; i++)
hashValue = 5 * hashValue + theKey.at(i);
return size_t(hashValue);
}
};
template<>
class hash<int>
{
public:
size_t operator()(const int theKey) const
{return size_t(theKey);}
};
template<>
class hash<long>
{
public:
size_t operator()(const long theKey) const
{return size_t(theKey);}
};散列表的线性表示方法。用数组table[]表示,类型为pair<const K,E>*
#include "hash.h" //将数据的关键字映射为非负整数
template<class K, class E>
class hashTable
{
public:
hashTable(int theDivisor=11){
divisor=theDivisor;
size=0;
table=new pair<const K,E>*[divisor];
for(int i=0;i<divisor;i++)
{
table[i]=NULL;//每个指针都要初始化为NULL
}
~hashTable(){
delete [] table;
}
//如果找到了关键字是k的hash表数组的项则返回位置,如果没有找到就返回可以插入的位置。
//如果找了一圈最后又回到散列函数计算的下标位置,表示散列表已满,返回该下标位置
int search(const K& k) const
{
int i=hash(k)%divisor;
int j=i;
do{
if(table[j]==NULL||table[j]->first==k)
return j;
j=(j+1)%divisor;
}while(j!=i)
return j;
}
pair<const K, E>* find(const K& k) const{
int i=search(k);
if(table[i]->first==k)
return table[i];
return NULL;
}
void insert(const pair<const K, E>& thepair){
int i=search(thepair.first);
if(table[i]==NULL) //散列表有空位置可以插入
table[i]=new pair<K,E>(thepair);
else{
if(table[i]->first==thepair.first)//散列表存在关键字为thepair的关键字的项
table[i]->second=thepair.second;
else throw ... //散列表已满
}
}
private:
hash<K> hash; //映射类型k到非负整数
pair<const K,E>** table;
int size;
int divisor;//散列函数的除数
}使用链表来实现散列表。散列表table[]的每一项是一个指向字典链表的指针,这样每一个桶可以存放不止一项数据。因此table[]的类型是sortedNode<K,E>。如图
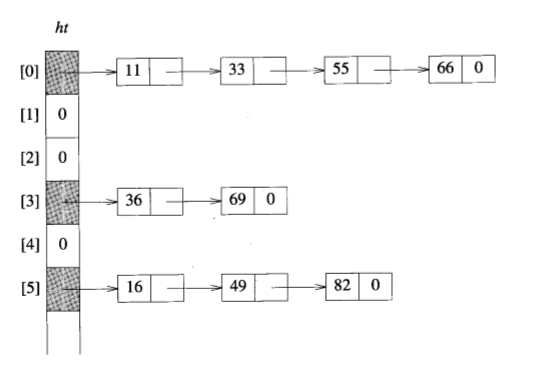
class hashchain:public dictionary{
public:
hashchain(int theDivisor=10){
divisor=theDivisor;
table=new sortedNode<K,E>[divisor];
size=0;
}
~hashtable(){
delete [] table;
}
int search(const K& k) const
{
int i=hash(k)%divisor;
}
pair<const K, E>* find(const K& k) const{
int i=hash(k)%divisor;
return table[i].find(k);
}
void insert(const pair<const K, E>& thepair){
int i=hash(thepair.first)%divisor;
int chainsize=table[i].size();
table[i].insert(thepair);
//表示链表中之前没有关键字等于thepair的关键字的节点,插入了新的节点,此时所有节
//点的总数增加1
if(chainsize<table[i].size)
size++;
}
private:
hash<K> hash;
sortedNode<K,E>* table;
int size;
int divisor;
}













 3484
3484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









