







在当今互联网时代,数据要会挖,得先学会爬!爬的过程是痛苦的,因为在计算机程序开发领域,网络爬虫的开发是一个很专业的方向,技术门槛比较高,它所要求的综合知识很多,相信很多同学都望而却步了。别急,说话说到后面往往都有但是滴。
但是该领域的几个非常方便的工具已经被集成到R的一些第三方包中了,所以我们完全可以基于R用一种很容易实现的方式来实现互联网数据的抓取,让我们可以直接去挖掘互联网这座金矿。
有了XML包,RCurl包,尤其是最近新出的rvest包(听说简直就是神器,是不是吹的呢),妈妈再也不用担心我的数据了。
今天下午学了一下RCurl包,很抱歉没有太多中文文档,看英语学来的,英语真的很重要,谁让编程软件都是由老外开发的呢,爬取了杭州安居客九堡租房信息,瞎操练的,实践出真知,慢慢懂了。。。
坑爹的地方真多,不同情况不同处理方法,还有有的网站URL本身就是加密的,如淘宝的https,还有些网页需要登录之后才能查看,有的网页甚至你点它的下一页,url居然还一样,源代码不变的,真是百思不得姐了。为什么没有大神写一本书,我给它起叫做,《那些年,爬虫我们遇到过的坑》。
data:2015-11-7
author:laidefa
library(XML)
library(RCurl)
loginURL<-"http://hz.zu.anjuke.com/fangyuan/jiubao/"
cookieFile<-"E://cookies.txt"
loginCurl<-getCurlHandle(followlocation=TRUE,verbose=TRUE,ssl.verifyhost=FALSE,
ssl.verifypeer=FALSE,cookiejar=cookieFile,cookiefile=cookieFile)
#获取第一页的url
web<-getURL(loginURL,curl=loginCurl)
#获取第2-10页的url
url_list = ""
i=1:9
url_list[i]<-paste0('http://hz.zu.anjuke.com/fangyuan/jiubao/p',i+1,'/')
#循环读取url
for(url in url_list){
web1 <-getURL(url,curl=loginCurl)
web<-rbind(web,web1)
}
#解析url树结构
doc<-htmlParse(web)
zufang_title<-sapply(getNodeSet(doc,"//div[@class='zu-info']//h3//a[@title]"),xmlValue)
type<-sapply(getNodeSet(doc,"//div[@class='zu-info']//p[1]"),xmlValue)
address<-sapply(getNodeSet(doc,"//div[@class='zu-info']//address"),xmlValue)
address<-substring(address,34)
price<-sapply(getNodeSet(doc,"//div[@class='zu-side']//p[1]"),xmlValue)
price<-price[-seq(53,520,53)]
contacts<-sapply(getNodeSet(doc,"//p[@class='bot-tag']//span[1]"),xmlValue)
#合并数据框
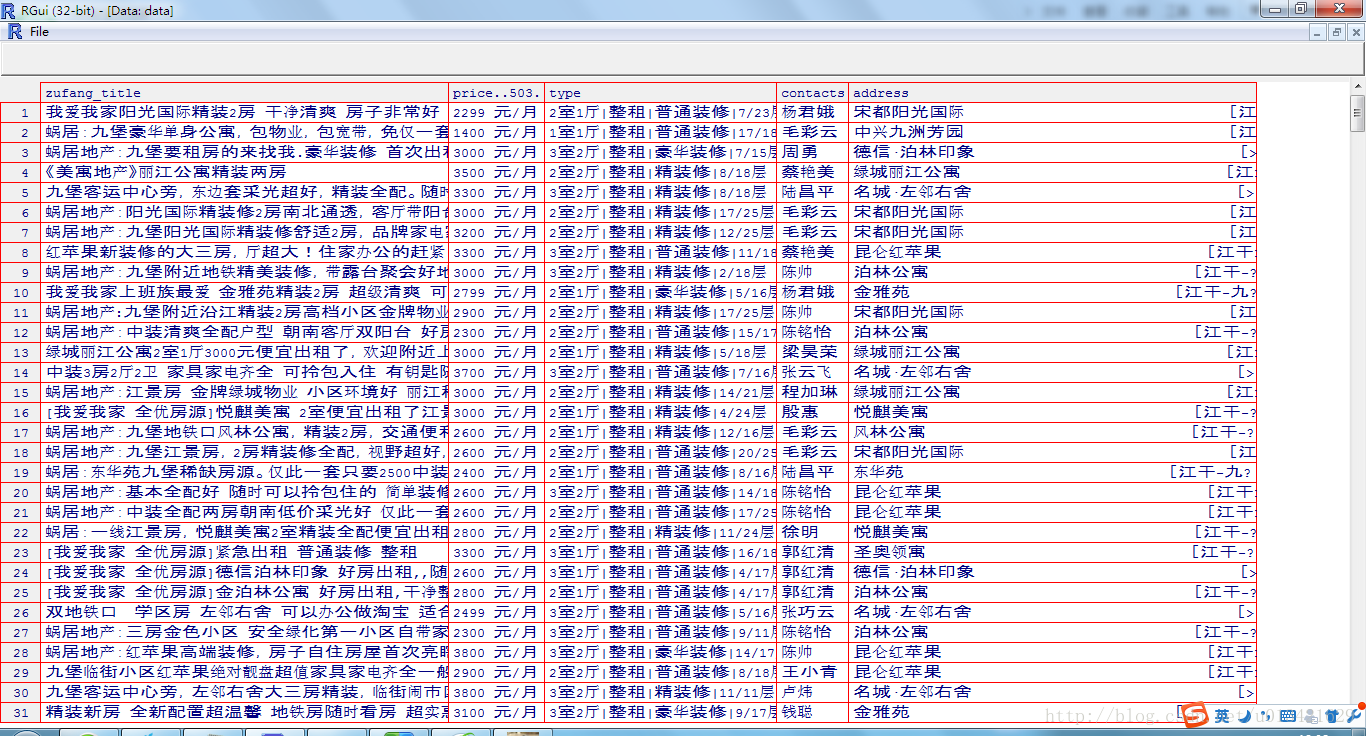
data<-data.frame(zufang_title,price[-503],type,contacts,address)
View(data)
















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











