







引言
机器学习定义
来自 1998 年 Tom Mitchell 的定义:一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。
吴恩达视频中提到的西洋下棋程序中:
T : 下棋
P:赢得比赛的概率
E:上万次的练习获得的经验
=====================
What is Machine Learning?
Two definitions of Machine Learning are offered. Arthur Samuel described it as: “the field of study that gives computers the ability to learn without being explicitly programmed.” This is an older, informal definition.
Tom Mitchell provides a more modern definition: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
In general, any machine learning problem can be assigned to one of two broad classifications:
Supervised learning and Unsupervised learning.
监督学习
监督学习:其基本思想是,我们给了一个数据集(就是我们平时说的训练集),并且知道我们数据集中的每个样本都有相应的“正确答案”,再根据这些样本对未来的输入数据作出预测.
监督学习问题可以分为“回归”和“分类”问题。
- 在回归问题中,我们试图预测连续输出中的结果,这意味着我们试图将输入变量映射到某个连续函数。
- 在分类问题中,我们试图预测离散输出的结果。 换句话说,我们试图将输入变量映射到离散类别。
无监督学习
无监督学习:允许我们利用很少的或者根本不知道我们的结果应该是什么样子,仅仅从数据中推导出结构。一句话,不基于预测结果的反馈。
常用的无监督学习算法有聚类。
单变量线性回归
线性回归模型
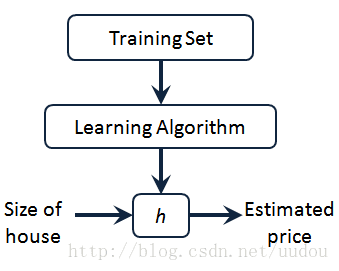
用语言描述就是:用 Training Set 喂给 Learning Algorithm 去训练,最后输出到一个假设 h 也可以认为表示一个函数,输入是房屋尺寸大小,就像你朋友想出售的房屋,因此 h 根据输入的值 x 来得出 y 值,y 值对应房子的价格 因此,h 是一个从 x 到 y 的函数映射。
对于单变量的线性回归模型而言,因为只含有一个特征/输入变量,因此输出函数 h(x) 可以表示为:h(x) = θ0 + θ1x
损失函数
损失函数:也叫成本函数,也叫代价函数,但我喜欢叫损失函数,它是用来衡量假设函数 h(x) 的准确性,换句话,就是衡量 h(x) 与实际的y 的平均误差。对于单变量线性回归模型而言,损失函数用如下公式表示:
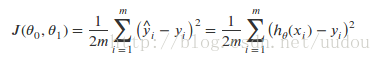
其中 hθ(xi) 是 xi 根据假设函数计算的预测值,yi是样本的实际值。m是样本的个数,损失函数亦被称之为平均均方误差,除以2是为了方便后面梯度下降算法的计算。
我们建模的目的就是要让 J(θ0, θ1) 最小,然后找到对应的 θ0 跟 θ1,进而得到 h(x) 。
梯度下降
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出损失函数 J(θ0, θ1) 的最小值。
梯度下降背后的思想是:开始时我们随机选择一个参数 (θ0, …θn) 的组合,计算损失函数,然后我们寻找下一个能让损失函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
梯度下载算法用如下公式表示:
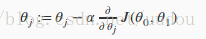
这里的 j = 0, 1;α 表示学习率,为正,表示梯度下降程度的步子有多大;损失函数的偏导表示梯度下降的方向。
在梯度下降迭代过程当中,我们需要更新 θ0 和 θ1,需要特别注意的是,我们需要同时更新 θ0 和 θ1。
梯度下降算法过程如下图:

反复按照上面的公式对 θ0 和 θ1 进行迭代,最终使得 θj 收敛于 θj。
- 我们应该调整参数 α 以确保梯度下降算法在合理的时间内收敛。 未能收敛或获得最小值的时间太多意味着我们的步长 α 是错误的。
- 梯度下降为什么能用固定的 α 收敛?
在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低时导数等于零,所以当我们接近局部最低时,导数值会自动变得越来越小,所以梯度下降将自动采取较小的幅度,这就是梯度下降的做法。所以实际上没有必要再另外减小 α。














 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









