






在写代码时总是会纠结把大任务放内层循环还是小任务放内层,<<代码大全2>> 中也提及, 总是将忙的任务放在内层. 于是做个试验, 并就此分析. 此为背景.
以下为最简单的一个双重 for 循环, 分别检测内层繁忙和外层繁忙的情况下的运行时间, 以下为示例代码:

代码图
打印出运行十次的时间:
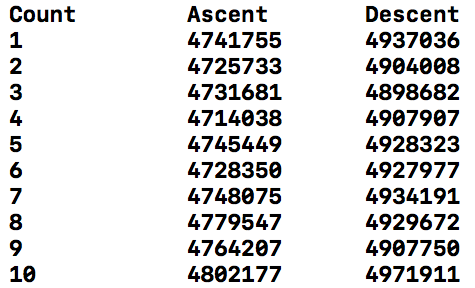
运行时间
从图中可以看出, 在升序排列(从外到内递增)时速度比降序快(复杂任务时更为明显),那么为什么呢?
分析他们的差异点:
1, 循环变量的操作次数
对比他们的反汇编代码, 一模一样, 函数调用栈的虚地址和 call 的地址都丝毫不差, 汇编上并未发现差异.
下面是调试代码图:

升序循环调试图
调试过程中发现, 整个循环的 i 和 j 只使用了一个栈地址空间, 这样就不计算创建和销毁空间的时间开销.(释放后重新申请到同一块空间 OR 编译器优化根本未释放?)
每一次外环进入内环时, 会将立即数0送入BP 内(即初始化 j = 0), 每次跳转之前会递增一次(j++), 再进行比较(j<n)
| i 初始化次数 | i 递增次数 | i 比较次数 | j 初始化次数 | j 递增次数 | j 比较次数 | |
| 升序 | 1 | 10 | 10 | 10 | 10^7 * 10 | 10^7 * 10 |
| 降序 | 1 | 10^7 | 10^7 | 10^7 | 10^7 * 10 | 10^7 * 10 |
上表中降序时有额外的初始化次数,递增和比较次数.
所以, 升序循环可以在循环变量的操作上节省开销.
2,分支预测
目前的编译器和 CPU 都有着分支预测的功能, 简单说即预测接下来几步操作并提前布置好指令, 如果预测正确则直接执行此指令, 失败则会损失预测所消耗的资源, 并回溯到分支处重新开始. 分支预测失败甚至会比未开启此功能时更低效,所以需要保持高的预测正确率.
假设每次预测为上一次的操作, 即第一次和最后一次失败.
| i 失败次数 | j 失败次数 | 正确率 | |
| 升序 | 2 | 2*10 | 1-(2+2*10)/(10^7*10) = 99.99% |
| 降序 | 2 | 10^7*2 | 1-(2+10^7*2)/(10^7*10) = 79.99% |
升序循环的分支预测成功率更高.
3,cache 命中率
示例代码中仅仅只有一个 value++ 操作, 并没有涉及 cache 命中率问题.
BTW, 对连续空间操作的时候 cache 命中率将会大大影响操作时间.(Cache RAM 读写速度几十倍于普通RAM)
e.g.双层 for 循环内对array[i][j]的操作将会远远快于 array[j][i], 因为在往寄存器(cache)内加载 array[0][0]时还会同时加载 array[0][1],array[0][2],所以在循环操作连续空间时效率更高.
4,cpu 主频, 架构, 操作系统时间片,程序优先级等
cpu 和操作系统等也是因素, 还需要更深入的学习了解.
总结造成示例代码升序循环效率更高的原因:
1,循环变量的操作次数 2, 分之预测成功率
实际任务当然会比此示例复杂得多, 可以作为实际应用的参考.















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









