







我想彻底搞清楚:这9个词语的区别与联系,以前我以为我懂了,但发现并没有达到真正的毫不迟疑的那种懂!

虽然我看过那些pdf官方文档给出的各自的定义 :

我在看 http://www.cnblogs.com/mikewolf2002/archive/2011/12/18/2291741.html http://bbs.gpuworld.cn/thread-10422-1-1.html http://www.cnblogs.com/mikewolf2002/archive/2011/12/18/2291911.html http://www.cnblogs.com/mikewolf2002/archive/2011/12/18/2291584.html 这些前辈讲的以及以前大神告诉我的我记录在 http://blog.csdn.net/wd1603926823/article/details/76577402 中的。
但现在我罗列的这9个参数我还没有完全扯清楚区别和联系:等我扯清楚了再好好总结一下:
我刚刚看到 http://m.fx114.net/qa-233-129813.aspx 这个人说了关于device改变buffer中的值是否会应该host_ptr 看到他的程序:CL_MEM_READ_ONLY 型的buffer在gpu上竟然可以被重新赋值啊?!
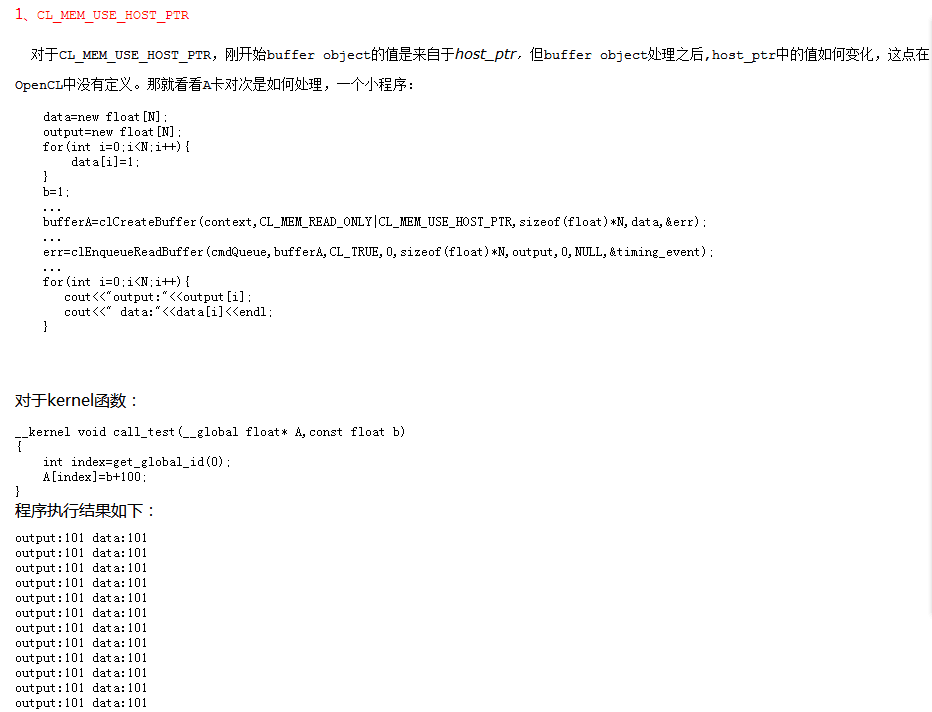
然后我自己按照他的运行了一个实例结果真的可以?!!!而且结果与他的一致!!!但是现在我还是改成我以前认为的CL_MEM_WRITE_ONLY来讨论关于写回host_ptr的问题:
#include <stdio.h>
#include <stdlib.h>
#include <CL/cl.h>
#define MAX_SOURCE_SIZE (0x100000)
__kernel void example(__global int *array)
{
int gld=get_global_id(0);
array[gld]=101;
if(get_global_id(0)==0)
{
printf("run the kernel...\n");
}
}
int main(void)
{
//host data
int i;
const int LIST_SIZE = 50;
int *A = (int*) malloc(sizeof(int) * LIST_SIZE);
int *B = (int*) malloc(sizeof(int) * LIST_SIZE);
for (i = 0; i < LIST_SIZE; i++)
{
A[i] = 1;
B[i] = 1;
}
FILE *fp;
char *source_str;
size_t source_size;
fp = fopen("/home/jumper/OpenCL_projects/MemoryContrastTest/fortest.cl", "r");
if (!fp)
{
fprintf(stderr, "Failed to load kernel.\n");
exit(1);
}
source_str = (char*) malloc(MAX_SOURCE_SIZE);
source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp);
fclose(fp);
// Get platform and device information
cl_platform_id platform_id = NULL;
cl_device_id device_id = NULL;
cl_uint ret_num_devices;
cl_uint ret_num_platforms;
cl_int ret = clGetPlatformIDs(1, &platform_id, &ret_num_platforms);
ret = clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_GPU, 1, &device_id, &ret_num_devices);
cl_context context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);
cl_command_queue command_queue = clCreateCommandQueue(context, device_id, 0,&ret);
cl_mem a_mem_obj = clCreateBuffer(context, CL_MEM_WRITE_ONLY | CL_MEM_USE_HOST_PTR, LIST_SIZE * sizeof(int), A, &ret);
cl_program program = clCreateProgramWithSource(context, 1,(const char **) &source_str, (const size_t *) &source_size, &ret);
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
cl_kernel kernel = clCreateKernel(program, "example", &ret);
ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *) &a_mem_obj);
size_t global_item_size = LIST_SIZE;
size_t local_item_size = 1;
ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,&global_item_size, &local_item_size, 0, NULL, NULL);
clFinish(command_queue);
int *C = (int*) malloc(sizeof(int) * LIST_SIZE);
ret = clEnqueueReadBuffer(command_queue, a_mem_obj, CL_TRUE, 0, LIST_SIZE * sizeof(int), C, 0, NULL, NULL);
for (i = 0; i < LIST_SIZE; i++)
{
printf("primer-host-A:%d GPU-return:%d host-A:%d\n", B[i], C[i],A[i]);
}
ret = clFlush(command_queue);
ret = clFinish(command_queue);
ret = clReleaseKernel(kernel);
ret = clReleaseProgram(program);
ret = clReleaseMemObject(a_mem_obj);
ret = clReleaseCommandQueue(command_queue);
ret = clReleaseContext(context);
free(A);
free(B);
free(C);
return 0;
}
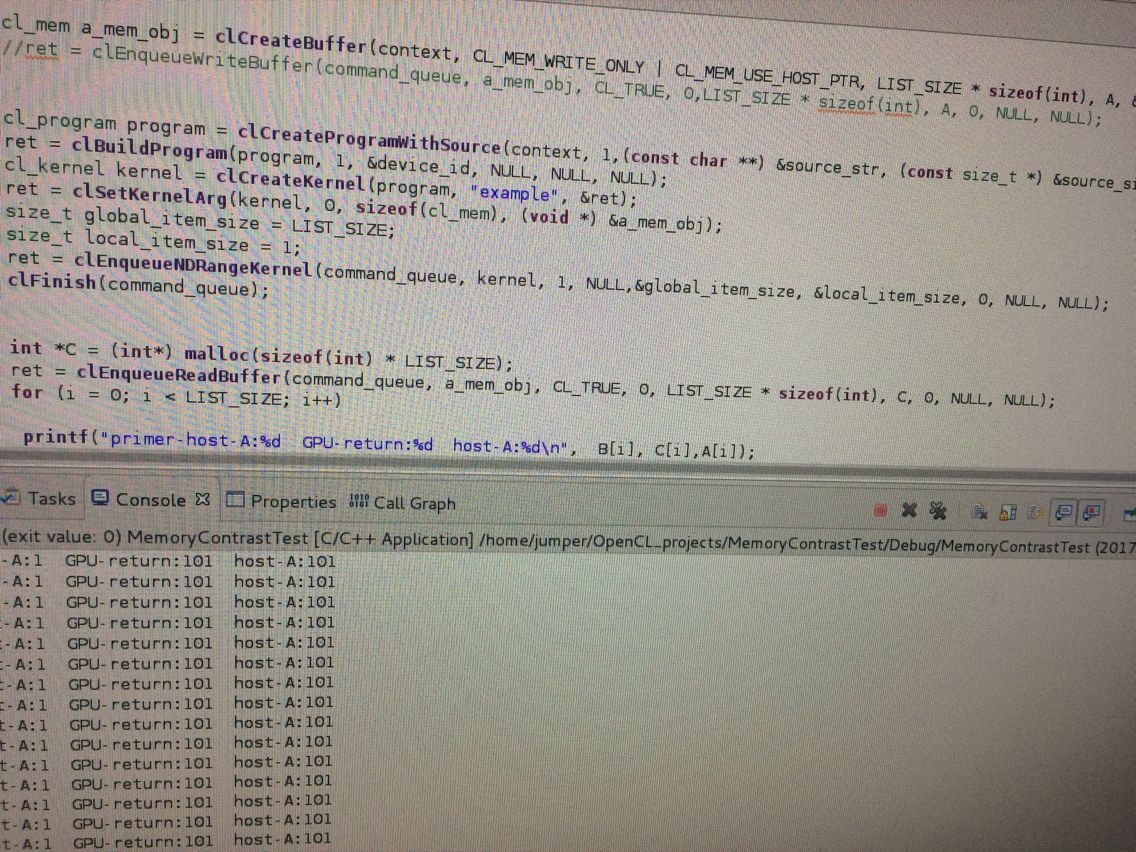
如果将CL_MEM_USE_HOST_PTR改成CL_MEM_COPY_HOST_PTR则不会写回host_ptr!!!!
http://blog.csdn.net/wcj0626/article/details/19616107 的第三点 使用CL_MEM_USE_PERSISTENT_MEM_AMD 我竟然在我电脑上没找到这个声明,难道在extension里面?原来在cl_ext.h里面
我找找。。。终于找到了,哎最近谷歌都打不开 郁闷
#include <stdio.h>
#include <stdlib.h>
#include <CL/cl.h>
#include <CL/cl_ext.h>
#include <string.h>
#define MAX_SOURCE_SIZE (0x100000)
int main(void)
{
//host data
int i;
const int LIST_SIZE = 50;
int *A = (int*) malloc(sizeof(int) * LIST_SIZE);
int *B = (int*) malloc(sizeof(int) * LIST_SIZE);
for (i = 0; i < LIST_SIZE; i++)
{
A[i] = 1;
B[i] = 1;
}
FILE *fp;
char *source_str;
size_t source_size;
fp = fopen("/home/jumper/OpenCL_projects/MemoryContrastTest/fortest.cl", "r");
if (!fp)
{
fprintf(stderr, "Failed to load kernel.\n");
exit(1);
}
source_str = (char*) malloc(MAX_SOURCE_SIZE);
source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp);
fclose(fp);
// Get platform and device information
cl_platform_id platform_id = NULL;
cl_device_id device_id = NULL;
cl_uint ret_num_devices;
cl_uint ret_num_platforms;
cl_int ret = clGetPlatformIDs(1, &platform_id, &ret_num_platforms);
ret = clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_GPU, 1, &device_id, &ret_num_devices);
cl_context context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);
cl_command_queue command_queue = clCreateCommandQueue(context, device_id, 0,&ret);
cl_mem a_mem_obj = clCreateBuffer(context, CL_MEM_WRITE_ONLY | CL_MEM_USE_PERSISTENT_MEM_AMD, LIST_SIZE * sizeof(int), 0, &ret);
cl_program program = clCreateProgramWithSource(context, 1,(const char **) &source_str, (const size_t *) &source_size, &ret);
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
cl_kernel kernel = clCreateKernel(program, "example", &ret);
ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *) &a_mem_obj);
size_t global_item_size = LIST_SIZE;
size_t local_item_size = 1;
ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,&global_item_size, &local_item_size, 0, NULL, NULL);
clFinish(command_queue);
int *maptr=(int*)clEnqueueMapBuffer(command_queue,a_mem_obj,CL_TRUE,CL_MAP_WRITE,0,LIST_SIZE*sizeof(int),0,NULL,NULL,&ret);
memcpy(maptr,A,LIST_SIZE*sizeof(int));
for (i = 0; i < LIST_SIZE; i++)
{
printf("primer-host-A:%d GPU-return:%d host-A:%d\n", B[i], maptr[i],A[i]);
}
ret=clEnqueueUnmapMemObject(command_queue,a_mem_obj,maptr,0,NULL,NULL);
ret = clFlush(command_queue);
ret = clFinish(command_queue);
ret = clReleaseKernel(kernel);
ret = clReleaseProgram(program);
ret = clReleaseMemObject(a_mem_obj);
ret = clReleaseCommandQueue(command_queue);
ret = clReleaseContext(context);
free(A);
free(B);
return 0;
}
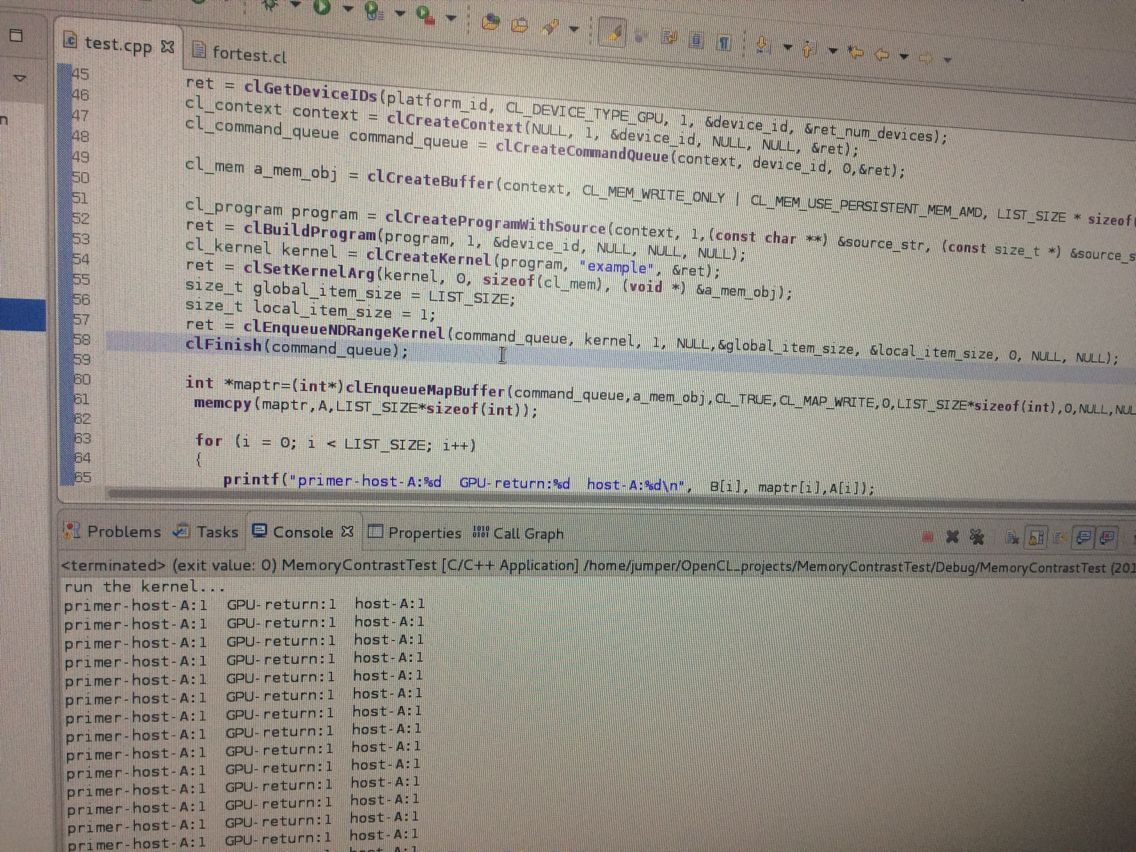
???
我暂时了解的总结了一下:不知道对不对,最近谷歌打不开,等谷歌打开会重新验证:
至于上面那个例子,应该是这样:

#include <stdio.h>
#include <stdlib.h>
#include <CL/cl.h>
#define MAX_SOURCE_SIZE (0x100000)
#include <CL/cl_ext.h>
#include <string.h>
#include <opencv2/core/ocl.hpp>
using namespace cv;
int main(void)
{
TickMeter tm;
tm.start();
//host data
int i;
const int LIST_SIZE = 50;
int *A = (int*) malloc(sizeof(int) * LIST_SIZE);
int *B = (int*) malloc(sizeof(int) * LIST_SIZE);
int *temp = (int*) malloc(sizeof(int) * LIST_SIZE);
for (i = 0; i < LIST_SIZE; i++)
{
A[i] = 1;
B[i] = 1;
temp[i] = 1;
}
FILE *fp;
char *source_str;
size_t source_size;
fp = fopen("/home/jumper/OpenCL_projects/MemoryContrastTest/fortest.cl", "r");
if (!fp)
{
fprintf(stderr, "Failed to load kernel.\n");
exit(1);
}
source_str = (char*) malloc(MAX_SOURCE_SIZE);
source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp);
fclose(fp);
// Get platform and device information
cl_platform_id platform_id = NULL;
cl_device_id device_id = NULL;
cl_uint ret_num_devices;
cl_uint ret_num_platforms;
cl_int ret = clGetPlatformIDs(1, &platform_id, &ret_num_platforms);
ret = clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_GPU, 1, &device_id, &ret_num_devices);
cl_context context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);
cl_command_queue command_queue = clCreateCommandQueue(context, device_id, 0,&ret);
//1. use the flag : CL_MEM_USE_HOST_PTR
// cl_mem a_mem_obj = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR, LIST_SIZE * sizeof(int), A, &ret);
// ret=clEnqueueWriteBuffer(command_queue,a_mem_obj,CL_TRUE,0,LIST_SIZE*sizeof(int),A,0,NULL,NULL);
//
// cl_program program = clCreateProgramWithSource(context, 1,(const char **) &source_str, (const size_t *) &source_size, &ret);
// ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
// cl_kernel kernel = clCreateKernel(program, "example", &ret);
// ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *) &a_mem_obj);
// size_t global_item_size = LIST_SIZE;
// size_t local_item_size = 1;
// ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,&global_item_size, &local_item_size, 0, NULL, NULL);
// clFinish(command_queue);
//
// int *maptr=(int*)malloc(sizeof(int)*LIST_SIZE);
// ret=clEnqueueReadBuffer(command_queue,a_mem_obj,CL_TRUE,0,LIST_SIZE*sizeof(int),maptr,0,NULL,NULL);
//
// for (i = 0; i < LIST_SIZE; i++)
// {
// printf("primer-host-A:%d GPU-return:%d host-A:%d\n", B[i], maptr[i],A[i]);
// }
//
// ret=clEnqueueUnmapMemObject(command_queue,a_mem_obj,maptr,0,NULL,NULL);
//
// ret = clFlush(command_queue);
// ret = clFinish(command_queue);
// ret = clReleaseKernel(kernel);
// ret = clReleaseProgram(program);
// ret = clReleaseMemObject(a_mem_obj);
// ret = clReleaseCommandQueue(command_queue);
// ret = clReleaseContext(context);
// free(A);
// free(B);
// free(maptr);
//2. use the flag : CL_MEM_USE_PERSISTENT_MEM_AMD
// cl_mem a_mem_obj = clCreateBuffer(context, CL_MEM_WRITE_ONLY | CL_MEM_USE_PERSISTENT_MEM_AMD, LIST_SIZE * sizeof(int), 0, &ret);
//
// cl_program program = clCreateProgramWithSource(context, 1,(const char **) &source_str, (const size_t *) &source_size, &ret);
// ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
// cl_kernel kernel = clCreateKernel(program, "example", &ret);
// ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *) &a_mem_obj);
// size_t global_item_size = LIST_SIZE;
// size_t local_item_size = 1;
// ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,&global_item_size, &local_item_size, 0, NULL, NULL);
// clFinish(command_queue);
//
// int *maptr=(int*)clEnqueueMapBuffer(command_queue,a_mem_obj,CL_TRUE,CL_MAP_READ,0,LIST_SIZE*sizeof(int),0,NULL,NULL,&ret);
// //memcpy(temp,maptr,LIST_SIZE*sizeof(int));
//
// for (i = 0; i < LIST_SIZE; i++)
// {
// printf("primer-host-A:%d GPU-return:%d host-A:%d\n", B[i], maptr[i],A[i]);
// }
//
// ret=clEnqueueUnmapMemObject(command_queue,a_mem_obj,maptr,0,NULL,NULL);
//
// ret = clFlush(command_queue);
// ret = clFinish(command_queue);
// ret = clReleaseKernel(kernel);
// ret = clReleaseProgram(program);
// ret = clReleaseMemObject(a_mem_obj);
// ret = clReleaseCommandQueue(command_queue);
// ret = clReleaseContext(context);
// free(A);
// free(B);
// free(temp);
//3. use the flag : CL_MEM_USE_PERSISTENT_MEM_AMD
cl_mem a_mem_obj = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_PERSISTENT_MEM_AMD, LIST_SIZE * sizeof(int), 0, &ret);
int *maptr=(int*)clEnqueueMapBuffer(command_queue,a_mem_obj,CL_TRUE,CL_MAP_WRITE,0,LIST_SIZE*sizeof(int),0,NULL,NULL,&ret);
memcpy(maptr,A,LIST_SIZE*sizeof(int));
ret=clEnqueueUnmapMemObject(command_queue,a_mem_obj,maptr,0,NULL,NULL);
cl_program program = clCreateProgramWithSource(context, 1,(const char **) &source_str, (const size_t *) &source_size, &ret);
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
cl_kernel kernel = clCreateKernel(program, "example", &ret);
ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *) &a_mem_obj);
size_t global_item_size = LIST_SIZE;
size_t local_item_size = 1;
ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,&global_item_size, &local_item_size, 0, NULL, NULL);
clFinish(command_queue);
int *maptr2=(int*)clEnqueueMapBuffer(command_queue,a_mem_obj,CL_TRUE,CL_MAP_READ,0,LIST_SIZE*sizeof(int),0,NULL,NULL,&ret);
//memcpy(temp,maptr,LIST_SIZE*sizeof(int));
for (i = 0; i < LIST_SIZE; i++)
{
printf("primer-host-A:%d GPU-return:%d host-A:%d\n", B[i], maptr2[i],A[i]);
}
ret=clEnqueueUnmapMemObject(command_queue,a_mem_obj,maptr2,0,NULL,NULL);
ret = clFlush(command_queue);
ret = clFinish(command_queue);
ret = clReleaseKernel(kernel);
ret = clReleaseProgram(program);
ret = clReleaseMemObject(a_mem_obj);
ret = clReleaseCommandQueue(command_queue);
ret = clReleaseContext(context);
free(A);
free(B);
free(temp);
tm.stop();
printf("process time= %f ms.\n",tm.getTimeMilli());
return 0;
}将那个图又改了下,因为看过AMD的例子慢慢发现有的地方的确是有问题的,看AMD的用法后:

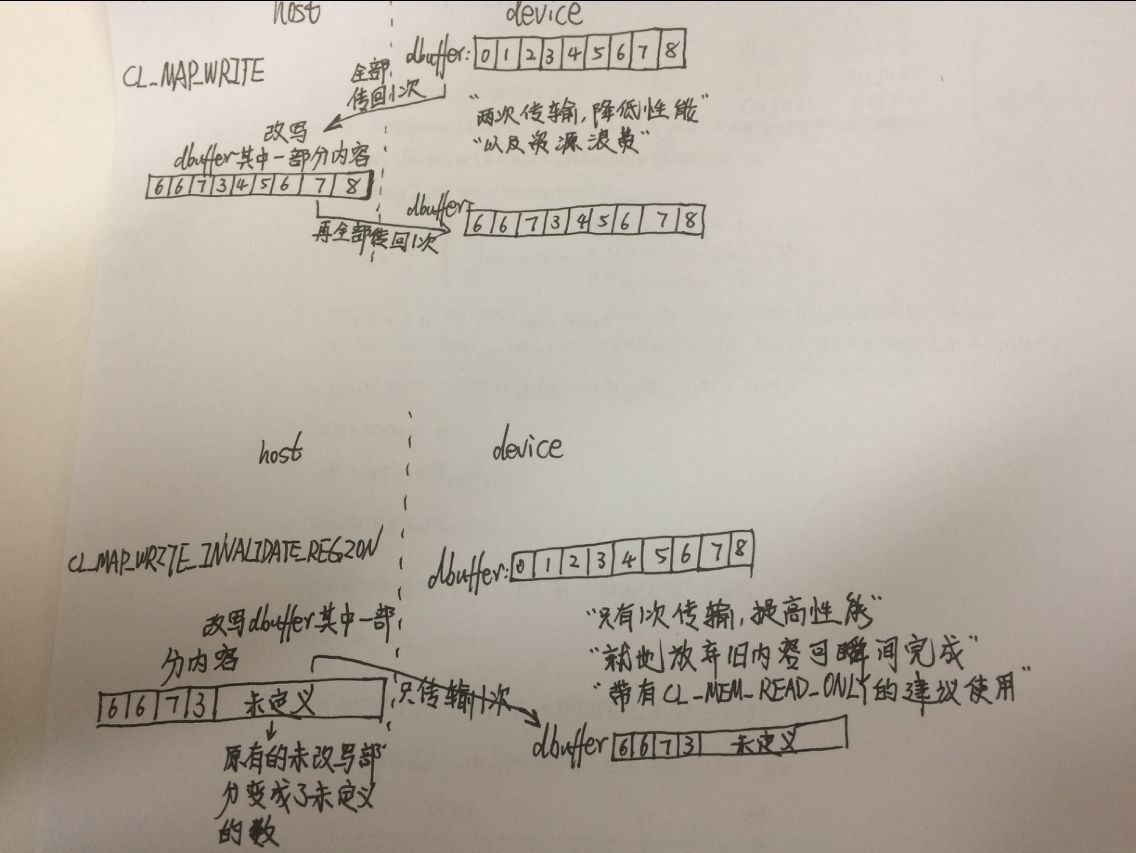
又在 https://community.amd.com/thread/168083 看到:


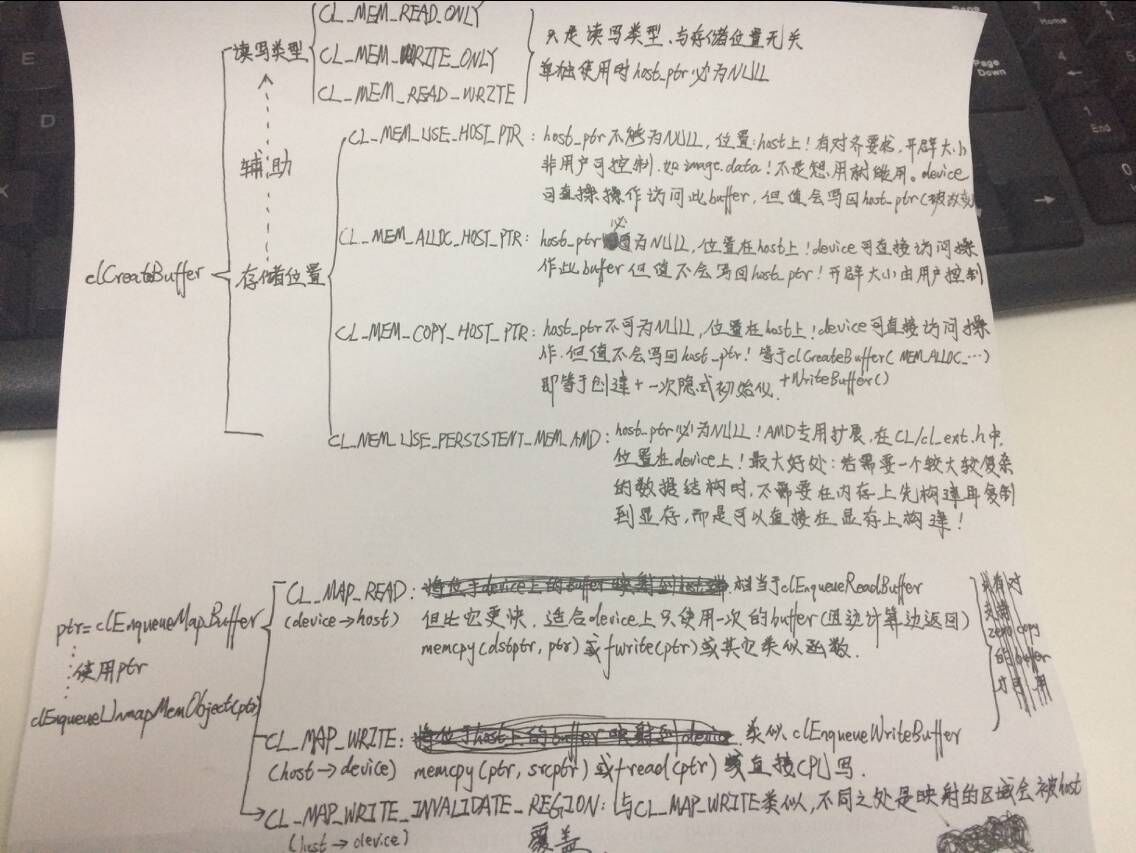
又查了 http://www.cnblogs.com/mikewolf2002/archive/2011/12/18/2291911.html 原来AMD-SDK3.0里已经没有BufferBandwidth的例子了,改成ImageBandwidth了。这位大神写得很好,我想了想,是不是该结合我现在对这些东西的了解,规定几种标准格式用法好了:
1:original buffer takes use of host-zero-copy buffer to write ?
1_1_1:write using clEnqueueWriteBuffer()
a. pinnedBuffer = clCreateBuffer( CL_MEM_ALLOC_HOST_PTR or CL_MEM_USE_HOST_PTR )
b. void *pinnedMemory = clEnqueueMapBuffer( pinnedBuffer ,CL_MAP_WRITE or CL_MAP_WRITE_INVALIDATE_REGION)
c. memcpy( pinnedMemory, hostptr ) or host writes
d. deviceBuffer = clCreateBuffer(CL_MEM_READ_ONLY or CL_MEM_WRITE_ONLY or CL_MEM_READ_WRITE)
e. clEnqueueWriteBuffer( deviceBuffer, pinnedMemory )
f. clEnqueueUnmapMemObject( pinnedBuffer, pinnedMemory )
1_1_2:write using clEnqueueCopyBuffer()
a. pinnedBuffer = clCreateBuffer( CL_MEM_ALLOC_HOST_PTR or CL_MEM_USE_HOST_PTR )
b. void *pinnedMemory = clEnqueueMapBuffer( pinnedBuffer ,CL_MAP_WRITE or CL_MAP_WRITE_INVALIDATE_REGION)
c. memcpy( pinnedMemory, hostptr ) or host writes
d. deviceBuffer = clCreateBuffer(CL_MEM_READ_ONLY or CL_MEM_WRITE_ONLY or CL_MEM_READ_WRITE)
e. clEnqueueUnmapMemObject( pinnedBuffer, pinnedMemory )
f. clEnqueueCopyBuffer( pinnedBuffer, deviceBuffer )
2:original buffer takes use of host-zero-copy buffer to read ?
1_2_1:read using clEnqueueREADBuffer()
a. pinnedBuffer = clCreateBuffer( CL_MEM_ALLOC_HOST_PTR or CL_MEM_USE_HOST_PTR )
b. void *pinnedMemory = clEnqueueMapBuffer( pinnedBuffer ,CL_MAP_READ)
c. memcpy( hostptr, pinnedMemory ) or host reads
d. deviceBuffer = clCreateBuffer(CL_MEM_READ_ONLY or CL_MEM_WRITE_ONLY or CL_MEM_READ_WRITE)
e. clEnqueueREADBuffer( deviceBuffer, pinnedMemory )
f. clEnqueueUnmapMemObject( pinnedBuffer, pinnedMemory )
1_2_2:read using clEnqueueCopyBuffer()
a. pinnedBuffer = clCreateBuffer( CL_MEM_ALLOC_HOST_PTR or CL_MEM_USE_HOST_PTR )
b. void *pinnedMemory = clEnqueueMapBuffer( pinnedBuffer ,CL_MAP_READ)
c. memcpy( hostptr, pinnedMemory ) or host reads
d. deviceBuffer = clCreateBuffer(CL_MEM_READ_ONLY or CL_MEM_WRITE_ONLY or CL_MEM_READ_WRITE)
e. clEnqueueUnmapMemObject( pinnedBuffer, pinnedMemory )
f. clEnqueueCopyBuffer( deviceBuffer, pinnedBuffer )
















 2402
2402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











