







优化算法
1.Mini-batch梯度下降法
对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降需要对整个训练集进行一次处理,如果训练数据很大时,处理速度就会非常慢。
但是如果每次处理训练数据的一部分进行梯度下降法,则算法的执行速度会变快。而处理的这一小部分训练子集即为Mini-batch.

对于普通的梯度下降法,一个epoch只能进行一次梯度下降;而对于Mini-batch梯度下降法,一个epoch可以进行Mini-batch次梯度下降。
Batch gradient descent和Mini-batch gradient descent区别:
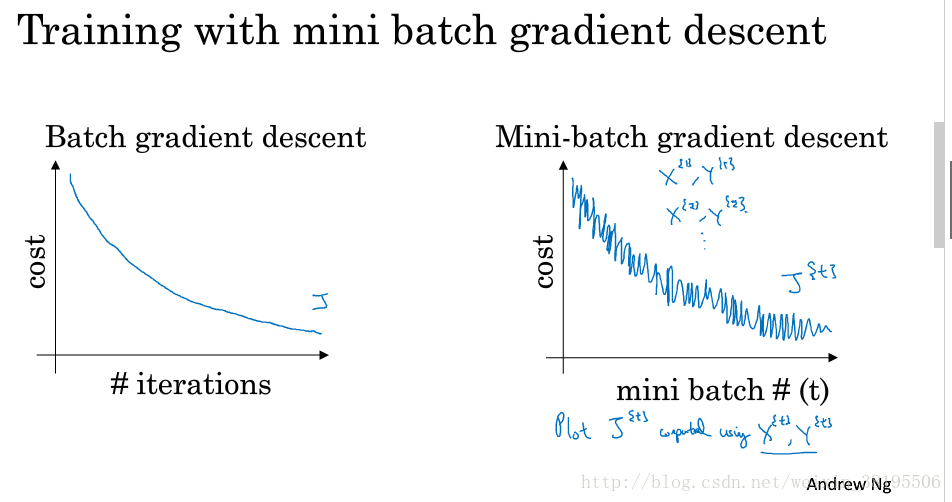
batch梯度下降:
对m个训练样本执行一次梯度下降,每次迭代时间较长。
Cost Function总是向减小的方向下降。
随机梯度下降(样本为m个,分为m个mini-batch):
对每一个训练样本执行一次梯度下降,但是无法享受向量化带来的计算加速。
Cost function总体趋势是向最小值方向下降,但是无法达到全局最小值点,呈现波动的形势。
Mini-batch梯度下降:
选择一个1
2.指数加权平均
指数加权平均的关键函数:
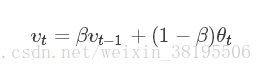
理解指数加权平均
例子,当β=0.9时:
v100=0.9v99+0.1θ100
v99=0.9v98+0.1θ99
v98=0.9v97+0.1θ98
展开后:
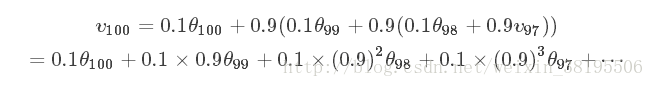
上式中θ前面的系数相加起来为1或者接近于1,称之为偏差修正。
总体来说存在,(1−ε)^1/ε=1/e,在我们的例子中,1−ε=β=0.9,即0.9^10≈0.35≈1/e。相当于大约10天后,系数的峰值(这里是0.1)下降到原来的1/e,只关注了过去10天的天气。
指数加权平均实现
v0=0
v1=βv0+(1−β)θ1
v2=βv1+(1−β)θ2
v3=βv2+(1−β)θ3
因为,在计算当前时刻的平均值,只需要前一天的平均值和当前时刻的值,所以在数据量非常大的情况下,指数加权平均在节约计算成本的方面是一种非常有效的方式,可以很大程度上减少计算机资源存储和内存的占用。
3. 动量(Momentum)梯度下降法
4. RMSprop
5. Adam 优化算法
6.学习率衰减
我们利用mini-batch梯度下降法寻找损失函数的最小值的时候,如果我设置一个固定的学习率α,则算法在到达最小值附近的时候,由于不同的batch中存在一定噪声,使得J不会精确收敛到0,而是会在一个接近于0的范围内波动。
但是如果我们使用学习率衰减,逐渐减小学习速率α,在算法开始的时候,学习速率还是相对较快,能够相对快速的向最小值点的方向下降。但随着α的减小,下降的步伐也会逐渐变小,最终会在最小值附近的一块更小的区域里波动.
学习率衰减的实现:
(1)decay_rate*epoch_num法
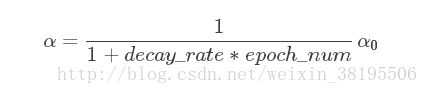
(2)指数衰减法:
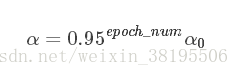
7.局部最优问题
在低纬度的情形下,我们可能会想象到一个Cost function存在一些局部最小值点,在初始化参数的时候,如果初始值选取的不得当,会存在陷入局部最优点的可能性。
但是,如果我们建立一个神经网络,通常梯度为零的点,并不是如左图中的局部最优点,而是右图中的鞍点(叫鞍点是因为其形状像马鞍的形状)。
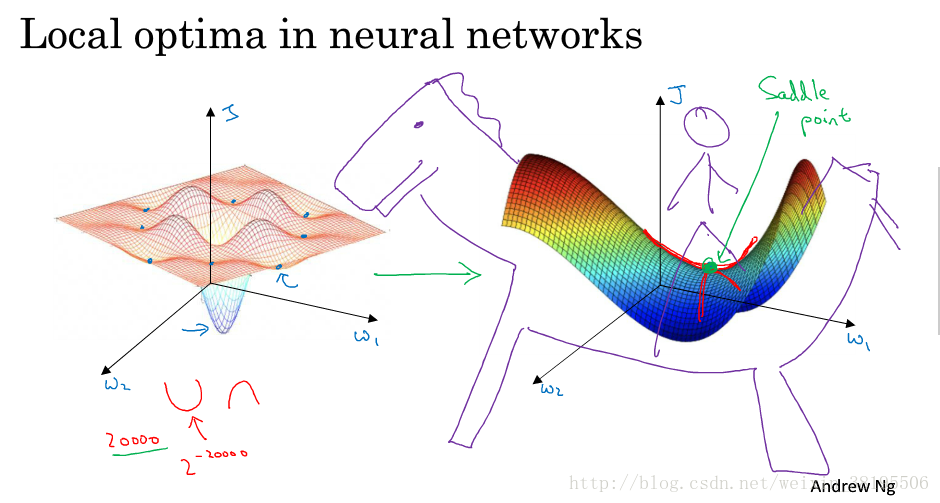
在一个具有高维度空间的函数中,如果梯度为0,那么在每个方向,Cost function可能是凸函数,也有可能是凹函数。但如果参数维度为2万维,想要得到局部最优解,那么所有维度均需要是凹函数,其概率为2^−20000,可能性非常的小。也就是说,在低纬度中的局部最优点的情况,并不适用于高纬度,我们在梯度为0的点更有可能是鞍点。
在高纬度的情况下:
几乎不可能陷入局部最小值点;
处于鞍点的停滞区会减缓学习过程,利用如Adam等算法进行改善














 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









