









目录
首先在这里祝各位互联网的大佬们节日快乐,永远暴富!

我是灰小猿,一个超会写bug的程序猿!
ieba库是Python中一个重要的第三方中文分词函数库,
由于该库是第三方库,并不是Python自带的模块,因此需要通过pip命令进行安装,pip安装命令如下:
pip install jieba
jieba库的原理是利用一个中文词库,将待分词的内容与分词词库进行对比,通过图结构和动态规划的方法找到最大概率的词组,当然中文词库中的词语不可能是唯一的,因此在jieba库中可以根据我们个人的需要向其中增加我们自定义的词语。
在jieba库中,支持三种分词模式:
精确模式
jieba.cut(s)
将句子最精确的切割开,常适合用于文本分析
全模式:
jieba..cut(s,cut_all=True)
将句子中所有可以成词的词语都扫描出来,速度快,但缺点是不能消除歧义。
搜索引擎模式:
jieba.cut_for_search(s)
在精确模式的基础上,对长词再次进行划分,提高召回率,适合用于搜索引擎分词
jieba库常用函数
jieba库中常用的函数如下:
| 函数 | 描述 |
| jieba.cut(s) | 精确模式,返回一个可以迭代的数据类型 |
| jieba..cut(s,cut_all=True) | 全模式,输出文本s中所有可能的词 |
| jieba.cut_for_search(s) | 搜索引擎模式,适合搜索引擎建立索引的分词结果 |
| jieba.lcut(s) | 精确模式,返回一个列表类型,建议使用 |
| jieba.lcut(s,cut_all=True) | 全模式,返回一个列表类型,建议使用 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型,建议使用 |
| jieba.add_word(w) | 向分词字典中增加新词w |
接下来对以上常用的分词技术用具体的代码和大家分析一下:
精确模式
jieba.lcut()函数返回精确模式,其返回结果会将原文完整且不多余的以分词的形式输出
# 精确模式
import jieba
str1 = "中华人民共和国是一个伟大的国家"
list1 = jieba.lcut(str1)
print(list1)['中华人民共和国', '是', '一个', '伟大', '的', '国家']
全模式
jieba.lcut(s,cut_all=True)函数返回全模式,即会将所有可能的分词全部输出,但缺点是数据冗余较大,
# 全模式
import jieba
str1 = "中华人民共和国是一个伟大的国家"
list2 = jieba.lcut(str1, cut_all=True)
print(list2)['中华', '中华人民', '中华人民共和国', '华人', '人民', '人民共和国', '共和', '共和国', '国是', '一个', '伟大', '的', '国家']
搜索引擎模式
jieba.lcut_for_search(s)函数返回搜索引擎模式,该模式会先执行精确模式,然后将获得到的词一步步的分割获得结果,
# 搜索引擎模式
import jieba
str1 = "中华人民共和国是一个伟大的国家"
list3 = jieba.lcut_for_search(str1)
print(list3)['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '一个', '伟大', '的', '国家']
自定义分词添加
但是jieba库内的中文分词资源必定有限,所以在进行一些我们自定义的词语时,系统将无法根据我们的需要进行划分,这个时候就需要我们自己使用add_word()函数在库中添加词语,效果如下:
str2 = "灰哥哥正在努力的学习Python"
list4 = jieba.lcut(str2)
print(list4)
jieba.add_word("灰哥哥")
list5 = jieba.lcut(str2)
print(list5)
中文分词案例
接下来和大家演示一个相关的实例,采用jieba库的中文分词技术,对“西游记”中大闹天宫一节中,各位人物的出场次数进行统计,
import jieba
text = open("dntg.txt").read() # 读取本章节文本
words = jieba.lcut(text)
# 将可能出现的任务放入列表
nameWords = ["太白金星", "玉皇大帝", "太上老君", "唐僧", "东海龙王", "孙悟空", "马温", "悟空", "齐天大圣"]
swkWords = ["孙悟空", "马温", "悟空", "齐天大圣"]
counts = {} # 定义存储数据的字典
for word in words:
if word not in nameWords:
continue
else:
if word in swkWords:
word = "孙悟空"
counts[word] = counts.get(word, 0) + 1 # 将分解后的词数量进行统计
wordLists = list(counts.items()) # 讲字典内容转化为列表形式
wordLists.sort(key=lambda x: x[1], reverse=True) # 对获取到的词语进行由大到小的排序
for wordList in wordLists:
word, count = wordList[0], wordList[1]
print("{} {}".format(word, count))分词结果:
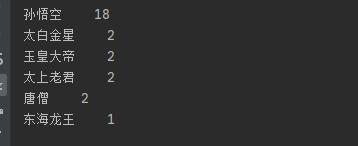
从结果可以看出,大闹天宫一章节中,出场率前六的人物角色分别是“孙悟空”、“太白金星”、“玉皇大帝”、“太上老君”、“唐僧”、“东海龙王”,其中,孙悟空的出场次序最多,为18次。
好了,关于jieba库中文分词技术的讲解就和大家分享到这里,
觉得不错记得点赞关注哟,
大灰狼陪你一起进步!
















 4014
4014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











