






二分类交叉熵求梯度具体过程
1. 定义二分类交叉熵损失函数
对于单个样本,二分类交叉熵损失的公式为:
BCE = − [ y log ( p ) + ( 1 − y ) log ( 1 − p ) ] \text{BCE} = - \left[ y \log(p) + (1 - y) \log(1 - p) \right] BCE=−[ylog(p)+(1−y)log(1−p)]
- 变量说明:
- y y y:真实标签,取值为 0 或 1(例如,0 表示负类,1 表示正类)。
- p p p:模型预测样本属于正类的概率,范围在 [ 0 , 1 ] [0, 1] [0,1]。
在机器学习中,预测概率 p p p 通常通过 sigmoid 函数计算得出:
p = σ ( z ) = 1 1 + e − z p = \sigma(z) = \frac{1}{1 + e^{-z}} p=σ(z)=1+e−z1
- 其中:
- z = θ T x z = \theta^T x z=θTx 是模型的线性输出。
- θ \theta θ 是参数向量(例如权重)。
- x x x 是输入特征向量。
我们的目标是计算损失函数 BCE \text{BCE} BCE 对参数 θ \theta θ 的梯度,即 ∂ BCE ∂ θ \frac{\partial \text{BCE}}{\partial \theta} ∂θ∂BCE。
2. 确定梯度计算的目标
由于 θ \theta θ 通常是一个向量(例如, θ = [ θ 1 , θ 2 , . . . , θ n ] \theta = [\theta_1, \theta_2, ..., \theta_n] θ=[θ1,θ2,...,θn]),梯度 ∇ θ BCE \nabla_\theta \text{BCE} ∇θBCE 也是一个向量,其每个分量为 ∂ BCE ∂ θ j \frac{\partial \text{BCE}}{\partial \theta_j} ∂θj∂BCE,其中 θ j \theta_j θj 是 θ \theta θ 的第 j j j 个参数。我们需要计算每个 θ j \theta_j θj 的偏导数。
3. 使用链式法则分解梯度
损失函数 BCE \text{BCE} BCE 依赖于 p p p,而 p p p 依赖于 z z z, z z z 依赖于 θ \theta θ。因此,我们可以使用链式法则将梯度分解为:
∂ BCE ∂ θ j = ∂ BCE ∂ p ⋅ ∂ p ∂ z ⋅ ∂ z ∂ θ j \frac{\partial \text{BCE}}{\partial \theta_j} = \frac{\partial \text{BCE}}{\partial p} \cdot \frac{\partial p}{\partial z} \cdot \frac{\partial z}{\partial \theta_j} ∂θj∂BCE=∂p∂BCE⋅∂z∂p⋅∂θj∂z
接下来,我们逐一计算这三个偏导数。
4. 计算 ∂ BCE ∂ p \frac{\partial \text{BCE}}{\partial p} ∂p∂BCE
从损失函数的定义开始:
BCE = − [ y log ( p ) + ( 1 − y ) log ( 1 − p ) ] \text{BCE} = - \left[ y \log(p) + (1 - y) \log(1 - p) \right] BCE=−[ylog(p)+(1−y)log(1−p)]
对 p p p 求偏导数:
∂ BCE ∂ p = ∂ ∂ p ( − y log ( p ) − ( 1 − y ) log ( 1 − p ) ) \frac{\partial \text{BCE}}{\partial p} = \frac{\partial}{\partial p} \left( - y \log(p) - (1 - y) \log(1 - p) \right) ∂p∂BCE=∂p∂(−ylog(p)−(1−y)log(1−p))
分别计算两项的导数:
- 第一项: ∂ ∂ p [ − y log ( p ) ] = − y ⋅ 1 p \frac{\partial}{\partial p} [- y \log(p)] = - y \cdot \frac{1}{p} ∂p∂[−ylog(p)]=−y⋅p1,因为 d d x log ( x ) = 1 x \frac{d}{dx} \log(x) = \frac{1}{x} dxdlog(x)=x1。
- 第二项: ∂ ∂ p [ − ( 1 − y ) log ( 1 − p ) ] = − ( 1 − y ) ⋅ − 1 1 − p = ( 1 − y ) ⋅ 1 1 − p \frac{\partial}{\partial p} [- (1 - y) \log(1 - p)] = - (1 - y) \cdot \frac{-1}{1 - p} = (1 - y) \cdot \frac{1}{1 - p} ∂p∂[−(1−y)log(1−p)]=−(1−y)⋅1−p−1=(1−y)⋅1−p1,因为对 log ( 1 − p ) \log(1 - p) log(1−p) 使用链式法则,内层导数为 − 1 -1 −1。
合并结果:
∂ BCE ∂ p = − y p + 1 − y 1 − p \frac{\partial \text{BCE}}{\partial p} = - \frac{y}{p} + \frac{1 - y}{1 - p} ∂p∂BCE=−py+1−p1−y
这是 BCE \text{BCE} BCE 对 p p p 的偏导数,表示损失如何随预测概率 p p p 变化。
5. 计算 ∂ p ∂ z \frac{\partial p}{\partial z} ∂z∂p
预测概率 p p p 是 z z z 的 sigmoid 函数:
p = σ ( z ) = 1 1 + e − z p = \sigma(z) = \frac{1}{1 + e^{-z}} p=σ(z)=1+e−z1
sigmoid 函数的导数是一个标准结果:
∂ p ∂ z = σ ( z ) ⋅ ( 1 − σ ( z ) ) \frac{\partial p}{\partial z} = \sigma(z) \cdot (1 - \sigma(z)) ∂z∂p=σ(z)⋅(1−σ(z))
由于 σ ( z ) = p \sigma(z) = p σ(z)=p,我们可以将其代入:
∂ p ∂ z = p ( 1 − p ) \frac{\partial p}{\partial z} = p (1 - p) ∂z∂p=p(1−p)
这个导数表明 p p p 对 z z z 的变化率在 p = 0.5 p = 0.5 p=0.5 时最大,在 p p p 接近 0 或 1 时趋近于 0。
6. 计算 ∂ z ∂ θ j \frac{\partial z}{\partial \theta_j} ∂θj∂z
线性输出 z z z 定义为:
z = θ T x = ∑ k θ k x k z = \theta^T x = \sum_{k} \theta_k x_k z=θTx=k∑θkxk
对第 j j j 个参数 θ j \theta_j θj 求偏导数:
∂ z ∂ θ j = ∂ ∂ θ j ( ∑ k θ k x k ) \frac{\partial z}{\partial \theta_j} = \frac{\partial}{\partial \theta_j} \left( \sum_{k} \theta_k x_k \right) ∂θj∂z=∂θj∂(k∑θkxk)
- 当 k = j k = j k=j 时, ∂ ( θ j x j ) ∂ θ j = x j \frac{\partial (\theta_j x_j)}{\partial \theta_j} = x_j ∂θj∂(θjxj)=xj。
- 当 k ≠ j k \neq j k=j 时, θ k x k \theta_k x_k θkxk 不含 θ j \theta_j θj,导数为 0。
因此:
∂ z ∂ θ j = x j \frac{\partial z}{\partial \theta_j} = x_j ∂θj∂z=xj
这表示 z z z 对 θ j \theta_j θj 的变化仅与对应的特征 x j x_j xj 相关。
7. 合并计算 ∂ BCE ∂ θ j \frac{\partial \text{BCE}}{\partial \theta_j} ∂θj∂BCE
将三个偏导数代入链式法则:
∂ BCE ∂ θ j = ∂ BCE ∂ p ⋅ ∂ p ∂ z ⋅ ∂ z ∂ θ j \frac{\partial \text{BCE}}{\partial \theta_j} = \frac{\partial \text{BCE}}{\partial p} \cdot \frac{\partial p}{\partial z} \cdot \frac{\partial z}{\partial \theta_j} ∂θj∂BCE=∂p∂BCE⋅∂z∂p⋅∂θj∂z
代入已计算的结果:
∂ BCE ∂ θ j = ( − y p + 1 − y 1 − p ) ⋅ p ( 1 − p ) ⋅ x j \frac{\partial \text{BCE}}{\partial \theta_j} = \left( - \frac{y}{p} + \frac{1 - y}{1 - p} \right) \cdot p (1 - p) \cdot x_j ∂θj∂BCE=(−py+1−p1−y)⋅p(1−p)⋅xj
接下来,我们可以简化表达式。
8. 简化梯度表达式
计算 ∂ BCE ∂ z \frac{\partial \text{BCE}}{\partial z} ∂z∂BCE 来验证和简化:
∂ BCE ∂ z = ∂ BCE ∂ p ⋅ ∂ p ∂ z = ( − y p + 1 − y 1 − p ) ⋅ p ( 1 − p ) \frac{\partial \text{BCE}}{\partial z} = \frac{\partial \text{BCE}}{\partial p} \cdot \frac{\partial p}{\partial z} = \left( - \frac{y}{p} + \frac{1 - y}{1 - p} \right) \cdot p (1 - p) ∂z∂BCE=∂p∂BCE⋅∂z∂p=(−py+1−p1−y)⋅p(1−p)
展开并化简:
- 第一项: − y p ⋅ p ( 1 − p ) = − y ( 1 − p ) -\frac{y}{p} \cdot p (1 - p) = -y (1 - p) −py⋅p(1−p)=−y(1−p)。
- 第二项:
1
−
y
1
−
p
⋅
p
(
1
−
p
)
=
(
1
−
y
)
p
\frac{1 - y}{1 - p} \cdot p (1 - p) = (1 - y) p
1−p1−y⋅p(1−p)=(1−y)p。
(注意: p ( 1 − p ) 1 − p = p \frac{p (1 - p)}{1 - p} = p 1−pp(1−p)=p,因为分子分母的 1 − p 1 - p 1−p 约去。)
合并:
∂ BCE ∂ z = − y ( 1 − p ) + ( 1 − y ) p \frac{\partial \text{BCE}}{\partial z} = -y (1 - p) + (1 - y) p ∂z∂BCE=−y(1−p)+(1−y)p
展开括号:
− y ( 1 − p ) + ( 1 − y ) p = − y + y p + p − y p = p − y -y (1 - p) + (1 - y) p = -y + y p + p - y p = p - y −y(1−p)+(1−y)p=−y+yp+p−yp=p−y
因此:
∂ BCE ∂ z = p − y \frac{\partial \text{BCE}}{\partial z} = p - y ∂z∂BCE=p−y
这是一个非常简洁的结果!现在,将其与 ∂ z ∂ θ j \frac{\partial z}{\partial \theta_j} ∂θj∂z 结合:
∂ BCE ∂ θ j = ∂ BCE ∂ z ⋅ ∂ z ∂ θ j = ( p − y ) ⋅ x j \frac{\partial \text{BCE}}{\partial \theta_j} = \frac{\partial \text{BCE}}{\partial z} \cdot \frac{\partial z}{\partial \theta_j} = (p - y) \cdot x_j ∂θj∂BCE=∂z∂BCE⋅∂θj∂z=(p−y)⋅xj
9. 得到完整的梯度向量
由于 θ \theta θ 是一个向量,梯度 ∇ θ BCE \nabla_\theta \text{BCE} ∇θBCE 也是一个向量,其每个分量为:
∂ BCE ∂ θ j = ( p − y ) x j \frac{\partial \text{BCE}}{\partial \theta_j} = (p - y) x_j ∂θj∂BCE=(p−y)xj
因此,对于整个参数向量 θ \theta θ,梯度为:
∇ θ BCE = ( p − y ) x \nabla_\theta \text{BCE} = (p - y) x ∇θBCE=(p−y)x
- 解释:
- p − y p - y p−y 是预测概率与真实标签的差值。
- x x x 是输入特征向量。
- 梯度是一个与 x x x 同维度的向量,每个分量由 p − y p - y p−y 缩放对应的特征值 x j x_j xj。
10. 验证梯度的合理性
-
当 y = 1 y = 1 y=1 时:
- ∇ θ BCE = ( p − 1 ) x = − ( 1 − p ) x \nabla_\theta \text{BCE} = (p - 1) x = -(1 - p) x ∇θBCE=(p−1)x=−(1−p)x。
- 如果 p < 1 p < 1 p<1(预测概率不足),梯度为负,参数 θ \theta θ 会增加以提高 p p p。
-
当 y = 0 y = 0 y=0 时:
- ∇ θ BCE = ( p − 0 ) x = p x \nabla_\theta \text{BCE} = (p - 0) x = p x ∇θBCE=(p−0)x=px。
- 如果 p > 0 p > 0 p>0(预测概率过高),梯度为正,参数 θ \theta θ 会减小以降低 p p p。
这种行为符合直觉:梯度方向始终引导模型调整参数,使预测概率接近真实标签。
11. 总结过程
计算二分类交叉熵损失梯度的具体步骤如下:
-
定义损失函数: BCE = − [ y log ( p ) + ( 1 − y ) log ( 1 − p ) ] \text{BCE} = - \left[ y \log(p) + (1 - y) \log(1 - p) \right] BCE=−[ylog(p)+(1−y)log(1−p)] 其中 p = σ ( z ) p = \sigma(z) p=σ(z), z = θ T x z = \theta^T x z=θTx。
-
应用链式法则: ∂ BCE ∂ θ j = ∂ BCE ∂ p ⋅ ∂ p ∂ z ⋅ ∂ z ∂ θ j \frac{\partial \text{BCE}}{\partial \theta_j} = \frac{\partial \text{BCE}}{\partial p} \cdot \frac{\partial p}{\partial z} \cdot \frac{\partial z}{\partial \theta_j} ∂θj∂BCE=∂p∂BCE⋅∂z∂p⋅∂θj∂z
-
计算各部分导数:
- ∂ BCE ∂ p = − y p + 1 − y 1 − p \frac{\partial \text{BCE}}{\partial p} = -\frac{y}{p} + \frac{1 - y}{1 - p} ∂p∂BCE=−py+1−p1−y
- ∂ p ∂ z = p ( 1 − p ) \frac{\partial p}{\partial z} = p (1 - p) ∂z∂p=p(1−p)
- ∂ z ∂ θ j = x j \frac{\partial z}{\partial \theta_j} = x_j ∂θj∂z=xj
-
合并并简化:
- ∂ BCE ∂ z = p − y \frac{\partial \text{BCE}}{\partial z} = p - y ∂z∂BCE=p−y
- ∂ BCE ∂ θ j = ( p − y ) x j \frac{\partial \text{BCE}}{\partial \theta_j} = (p - y) x_j ∂θj∂BCE=(p−y)xj
-
得出梯度向量: ∇ θ BCE = ( p − y ) x \nabla_\theta \text{BCE} = (p - y) x ∇θBCE=(p−y)x
这个梯度可以直接用于梯度下降更新参数:
θ new = θ − η ( p − y ) x \theta_{\text{new}} = \theta - \eta (p - y) x θnew=θ−η(p−y)x
其中 η \eta η 是学习率。
加权交叉熵的定义与应用
加权交叉熵(Weighted Cross-Entropy Loss)是标准交叉熵损失的一种扩展,主要用于解决分类问题中类别不平衡的挑战。
1. 什么是加权交叉熵?
加权交叉熵是在标准交叉熵损失的基础上引入权重,用于调整不同类别对总损失的贡献。标准交叉熵损失假设所有类别的样本对损失的影响是均等的,但在类别不平衡的数据集中,这种假设会导致模型偏向多数类,忽略少数类。加权交叉熵通过为每个类别分配不同的权重,增强模型对少数类的关注,从而提高整体性能。
- 二分类加权交叉熵
对于二分类问题,标准交叉熵损失为:
CE = − [ y log ( p ) + ( 1 − y ) log ( 1 − p ) ] \text{CE} = -\left[ y \log(p) + (1 - y) \log(1 - p) \right] CE=−[ylog(p)+(1−y)log(1−p)]- y y y:真实标签(0 或 1),
- p p p:模型预测为正类的概率。
加权交叉熵引入正类和负类的权重:
WCE
=
−
[
w
y
⋅
y
log
(
p
)
+
w
(
1
−
y
)
⋅
(
1
−
y
)
log
(
1
−
p
)
]
\text{WCE} = -\left[ w_y \cdot y \log(p) + w_{(1-y)} \cdot (1 - y) \log(1 - p) \right]
WCE=−[wy⋅ylog(p)+w(1−y)⋅(1−y)log(1−p)]
-
w y w_y wy:正类( y = 1 y = 1 y=1)的权重,
-
w ( 1 − y ) w_{(1-y)} w(1−y):负类( y = 0 y = 0 y=0)的权重。
-
多分类加权交叉熵
对于多分类问题,标准交叉熵损失为:
CE = − ∑ i = 1 C y i log ( p i ) \text{CE} = -\sum_{i=1}^{C} y_i \log(p_i) CE=−i=1∑Cyilog(pi)- C C C:类别数,
- y i y_i yi:one-hot 编码的真实标签,
- p i p_i pi:预测第 i i i 类的概率。
加权交叉熵为:
WCE
=
−
∑
i
=
1
C
w
i
⋅
y
i
log
(
p
i
)
\text{WCE} = -\sum_{i=1}^{C} w_i \cdot y_i \log(p_i)
WCE=−i=1∑Cwi⋅yilog(pi)
- w i w_i wi:第 i i i 类的权重。
2. 为什么要使用加权交叉熵?
在许多实际问题中,数据集的类别分布不平衡,例如:
- 欺诈检测:欺诈交易(正类)远少于正常交易(负类)。
- 医疗诊断:疾病样本(正类)远少于健康样本(负类)。
问题: 标准交叉熵损失对所有样本一视同仁,计算的是平均损失。在不平衡数据集中,多数类样本数量多,对总损失的贡献大,模型优化时会倾向于正确预测多数类,导致少数类的预测性能极差。例如,模型可能将所有样本预测为多数类以获得高准确率,但完全忽略少数类。
解决方法: 加权交叉熵通过为少数类分配更高的权重,增加其在损失中的影响力,使模型在训练时更关注少数类,提高对少数类的预测能力。
3. 权重的设置方法
权重的选择通常基于类别的样本数量,常见方法包括:
- 逆频率权重
权重与类别样本数的倒数成正比:
w i = N C ⋅ N i w_i = \frac{N}{C \cdot N_i} wi=C⋅NiN- N N N:总样本数,
- C C C:类别数,
- N i N_i Ni:第 i i i 类的样本数。
示例: 假设数据集有 10,000 个样本,分为 3 类:
- 类 0:9,000 个样本, w 0 = 10000 3 ⋅ 9000 ≈ 0.37 w_0 = \frac{10000}{3 \cdot 9000} \approx 0.37 w0=3⋅900010000≈0.37,
- 类 1:900 个样本, w 1 = 10000 3 ⋅ 900 ≈ 3.7 w_1 = \frac{10000}{3 \cdot 900} \approx 3.7 w1=3⋅90010000≈3.7,
- 类 2:100 个样本, w 2 = 10000 3 ⋅ 100 ≈ 33.3 w_2 = \frac{10000}{3 \cdot 100} \approx 33.3 w2=3⋅10010000≈33.3。
少数类的权重显著高于多数类,放大其对损失的贡献。
- 二分类中的正类权重
对于二分类,常用正类权重比:
w 1 = N 0 N 1 , w 0 = 1 w_1 = \frac{N_0}{N_1}, \quad w_0 = 1 w1=N1N0,w0=1- N 0 N_0 N0:负类样本数,
- N 1 N_1 N1:正类样本数。
4. 加权交叉熵的应用场景
加权交叉熵特别适用于以下场景:
- 欺诈检测:欺诈交易占比极低,但正确识别欺诈(少数类)至关重要。
- 医疗诊断:罕见疾病的检测比健康样本更关键。
- 图像分类:某些类别样本稀少,但业务上需要关注。
通过增加少数类的权重,模型在训练时不会完全偏向多数类,从而提高对少数类的召回率和整体分类性能。
5. 在 PyTorch 中的实现
在 PyTorch 中,加权交叉熵可以通过内置的损失函数实现。
- 二分类实现
使用nn.BCEWithLogitsLoss,通过pos_weight参数设置正类权重:
import torch
import torch.nn as nn
# 假设正类样本数 N1 = 100,负类样本数 N0 = 9900
pos_weight = torch.tensor([9900 / 100]) # 正类权重比
criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
- 多分类实现
使用nn.CrossEntropyLoss,通过weight参数设置每个类别的权重:
import torch
import torch.nn as nn
# 假设三个类别,样本数分别为 N0 = 9000, N1 = 900, N2 = 100
N = 10000
weights = torch.tensor([N / (3 * 9000), N / (3 * 900), N / (3 * 100)])
criterion = nn.CrossEntropyLoss(weight=weights)
- 训练示例
# 假设模型、输入和标签已定义
model = MyModel()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(100):
model.train()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
6. 加权交叉熵的效果
- 标准交叉熵:在不平衡数据集中,模型可能忽略少数类,导致少数类的召回率极低。
- 加权交叉熵:通过提高少数类的权重,模型在训练时更关注少数类,可能略微降低整体准确率,但显著提高少数类的预测能力(如召回率)。
示例: 在欺诈检测中,假设测试集有 20 个正类样本:
- 标准交叉熵:召回率可能为 0(全预测为负类)。
- 加权交叉熵:召回率可能提高到 0.75(正确预测 15 个正类)。
类别不平衡对标准交叉熵损失的影响
为什么会出现偏向多数类的问题?
在欺诈检测中,数据集通常是不平衡的:正常交易( y = 0 y=0 y=0)占绝大多数,而欺诈交易( y = 1 y=1 y=1)非常稀少。这种不平衡会导致标准交叉熵损失在优化时更关注多数类,从而使模型偏向于预测所有样本为多数类。以下是具体过程:
1. 数据集中多数类样本占主导地位
假设一个数据集有 100 个样本,其中 99 个是正常交易( y = 0 y=0 y=0),仅 1 个是欺诈交易( y = 1 y=1 y=1),即欺诈交易占比仅为 1%。这种极端的类不平衡在欺诈检测中很常见。
2. 标准交叉熵损失是平均损失
标准交叉熵损失计算的是所有样本损失的平均值:
Average CE = 1 N ∑ i = 1 N − [ y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ] \text{Average CE} = \frac{1}{N} \sum_{i=1}^N -\left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right] Average CE=N1i=1∑N−[yilog(pi)+(1−yi)log(1−pi)]
其中 N N N 是样本总数。由于正常交易数量远超欺诈交易,平均损失主要由多数类样本的损失决定。
3. 模型优化倾向于减少多数类的损失
在训练时,模型通过梯度下降调整参数以最小化平均损失。梯度是基于所有样本的平均梯度计算的:
Gradient = 1 N ∑ i = 1 N ( p i − y i ) x i \text{Gradient} = \frac{1}{N} \sum_{i=1}^N (p_i - y_i) x_i Gradient=N1i=1∑N(pi−yi)xi
- 对于多数类样本( y i = 0 y_i = 0 yi=0),如果模型预测 p i p_i pi 接近 0,则 p i − y i ≈ 0 p_i - y_i \approx 0 pi−yi≈0,这些样本对梯度的贡献很小,损失也很低。
- 对于少数类样本( y i = 1 y_i = 1 yi=1),如果 p i p_i pi 接近 0,则 p i − y i ≈ − 1 p_i - y_i \approx -1 pi−yi≈−1,梯度贡献较大,但由于这类样本数量极少,其对总梯度的影响被多数类样本"淹没"。
因此,模型会倾向于调整参数,使大多数样本(即正常交易)的预测 p i p_i pi 接近 0,从而显著降低平均损失,即使这意味着欺诈交易的预测不准确。
假设模型预测所有样本的 p = 0.01 p = 0.01 p=0.01:
- 对于 99 个正常交易( y = 0 y=0 y=0),每个样本的损失为 − log ( 1 − 0.01 ) ≈ 0.005 -\log(1 - 0.01) \approx 0.005 −log(1−0.01)≈0.005, 总损失为 99 × 0.005 = 0.495 99 \times 0.005 = 0.495 99×0.005=0.495。
- 对于 1 个欺诈交易( y = 1 y=1 y=1),损失为 − log ( 0.01 ) ≈ 4.605 -\log(0.01) \approx 4.605 −log(0.01)≈4.605。
- 平均损失为 ( 0.495 + 4.605 ) / 100 = 0.051 (0.495 + 4.605) / 100 = 0.051 (0.495+4.605)/100=0.051。
现在假设模型试图正确识别欺诈交易,预测其 p = 0.99 p = 0.99 p=0.99,但这可能导致部分正常交易的 p p p 增加(例如 10 个正常交易的 p = 0.1 p = 0.1 p=0.1):
- 欺诈交易损失变为 − log ( 0.99 ) ≈ 0.01 -\log(0.99) \approx 0.01 −log(0.99)≈0.01,
- 10 个正常交易的损失为 10 × − log ( 1 − 0.1 ) ≈ 1.05 10 \times -\log(1 - 0.1) \approx 1.05 10×−log(1−0.1)≈1.05,
- 其余 89 个正常交易的损失仍为 89 × 0.005 = 0.445,
- 平均损失为 ( 1.05 + 0.01 + 0.445 ) / 100 = 0.0151 (1.05 + 0.01 + 0.445) / 100 = 0.0151 (1.05+0.01+0.445)/100=0.0151。
虽然第二种情况正确识别了欺诈交易,但平均损失反而增加了(从 0.051 到 0.0151)。在实践中,模型很难仅对欺诈样本输出高概率而不影响正常样本的预测,尤其当特征分布复杂时。结果,模型可能选择一个简单策略:对所有样本预测低概率(接近 0),以保证多数类损失极低,从而使总体损失"看起来"较小。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
import numpy as np
# 设置随机种子以确保结果可重复
torch.manual_seed(42)
np.random.seed(42)
# 生成模拟数据集
n_samples = 10000
n_positive = 100 # 正类样本数
n_negative = n_samples - n_positive
# 正类特征:均值为 [1, 1],标准差为 1
positive_features = np.random.randn(n_positive, 2) + np.array([1, 1])
# 负类特征:均值为 [0, 0],标准差为 1
negative_features = np.random.randn(n_negative, 2) + np.array([0, 0])
# 合并特征和标签
features = np.vstack((positive_features, negative_features))
labels = np.array([1] * n_positive + [0] * n_negative)
# 划分训练集和测试集(80% 训练,20% 测试)
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# 转换为 PyTorch 张量
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1) # 添加维度以匹配模型输出
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).unsqueeze(1)
# 定义简单神经网络模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.linear = nn.Linear(2, 1) # 输入维度 2,输出维度 1
self.sigmoid = nn.Sigmoid() # 将输出转换为概率
def forward(self, x):
return self.sigmoid(self.linear(x))
# 初始化模型
model = SimpleNN()
# 定义损失函数和优化器
criterion = nn.BCELoss() # 标准二元交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器,学习率为 0.01
# 训练模型
n_epochs = 100
for epoch in range(n_epochs):
model.train() # 设置模型为训练模式
optimizer.zero_grad() # 清空梯度
outputs = model(X_train) # 前向传播
loss = criterion(outputs, y_train) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 每 10 个 epoch 打印一次损失
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{n_epochs}], Loss: {loss.item():.4f}')
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 禁用梯度计算
test_outputs = model(X_test) # 在测试集上预测
test_preds = (test_outputs > 0.5).float() # 阈值 0.5 转换为类别预测
accuracy = (test_preds == y_test).float().mean() # 计算整体准确率
recall = recall_score(y_test.numpy(), test_preds.numpy()) # 计算正类的召回率
print(f'Test Accuracy: {accuracy:.4f}')
print(f'Recall for positive class: {recall:.4f}')
# 检查对正类样本的预测情况
positive_test_indices = np.where(y_test.numpy() == 1)[0] # 测试集中正类的索引
positive_preds = test_preds[positive_test_indices] # 正类的预测结果
print(f'Number of positive samples in test set: {len(positive_test_indices)}')
print(f'Number of correctly predicted positive samples: {int(positive_preds.sum())}')
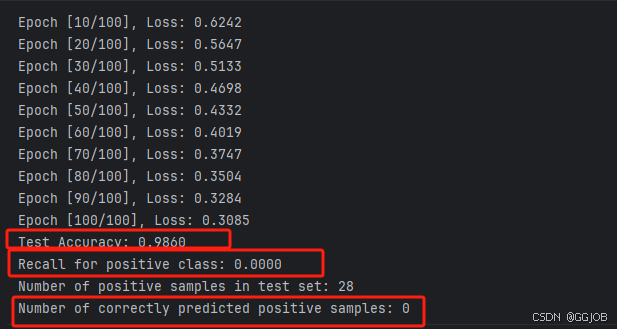
损失从初始值逐渐下降,表明模型在训练过程中逐步优化。
测试集准确率达到 98.60%,看似很高。但这主要是因为测试集中负类(正常交易)占绝大多数,模型只需预测所有样本为负类即可获得高准确率。
正类的召回率为 0.0000,意味着模型未能正确识别测试集中的任何一个正类样本(欺诈交易)。这表明模型完全偏向于预测多数类(负类)。
测试集中有 100 个正类样本,但模型正确预测的个数为 0,进一步证实模型忽略了少数类。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
import numpy as np
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)
# 生成不平衡数据集
n_samples = 10000
n_positive = 100
n_negative = n_samples - n_positive
positive_features = np.random.randn(n_positive, 2) + [1, 1]
negative_features = np.random.randn(n_negative, 2)
features = np.vstack((positive_features, negative_features))
labels = np.array([1] * n_positive + [0] * n_negative)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).unsqueeze(1)
# 定义模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.linear = nn.Linear(2, 1)
def forward(self, x):
return self.linear(x) # 输出 logits,由 BCEWithLogitsLoss 处理 sigmoid
# 计算正类权重
pos_weight = (y_train.size(0) - y_train.sum()) / y_train.sum()
# 初始化模型和损失函数
model = SimpleNN()
criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(100):
model.train()
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f'Epoch [{epoch + 1}/100], Loss: {loss.item():.4f}')
# 评估模型
model.eval()
with torch.no_grad():
test_outputs = model(X_test)
test_preds = (torch.sigmoid(test_outputs) > 0.5).float()
accuracy = (test_preds == y_test).float().mean()
recall = recall_score(y_test.numpy(), test_preds.numpy())
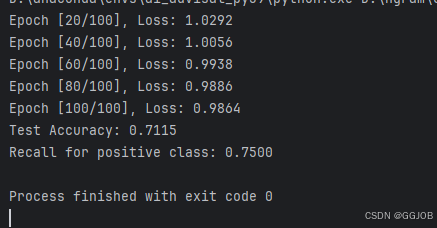
print(f'Test Accuracy: {accuracy:.4f}')
print(f'Recall for positive class: {recall:.4f}')


















 3184
3184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









