







 本文介绍了MV3D融合网络,一种将雷达点云与单目视觉信息相结合的方法,用于无人驾驶场景中的3D物体检测。该方法通过多视角点云投影生成初始3Dproposal,并利用融合网络提高检测精度。
本文介绍了MV3D融合网络,一种将雷达点云与单目视觉信息相结合的方法,用于无人驾驶场景中的3D物体检测。该方法通过多视角点云投影生成初始3Dproposal,并利用融合网络提高检测精度。
问题引入
在无人驾驶场景中,物体的3D检测(或者说是bounding-box)的重要性不言而喻。从2D检测到3D检测,主要的难点是提取深度信息,因此总体上可以将其分为四种,分别为:
- 基于单目图像(Mono)
- 基于双目图像(Stereo)
- 基于雷达(LIDAR)
- 基于融合网络
这篇论文就是一篇较为出色的融合网络的范例。后期和清华的老师沟通得知,这篇论文的算法正在被产业化,因此源码在一段时间内不会透露,可以就相关问题进行沟通。
但是该论文的很多思想以及尝试的实现代码还是有很多值得学习的地方的。
接下来说一下这篇文章的性质: 这是一篇将雷达点云与单目视觉融合来进行的3D bounding-box提取。
关于突出贡献什么的,个人觉得最大的一点就是将雷达点云信息与单目图像信息结合起来了,同时这种结合还保证了其速度与精度。关于其能够达到如此好的效果的原因,将在之后的文章中进行深入的分析。
总体结构
老规矩,了解一篇文章首先了解其总体的架构:
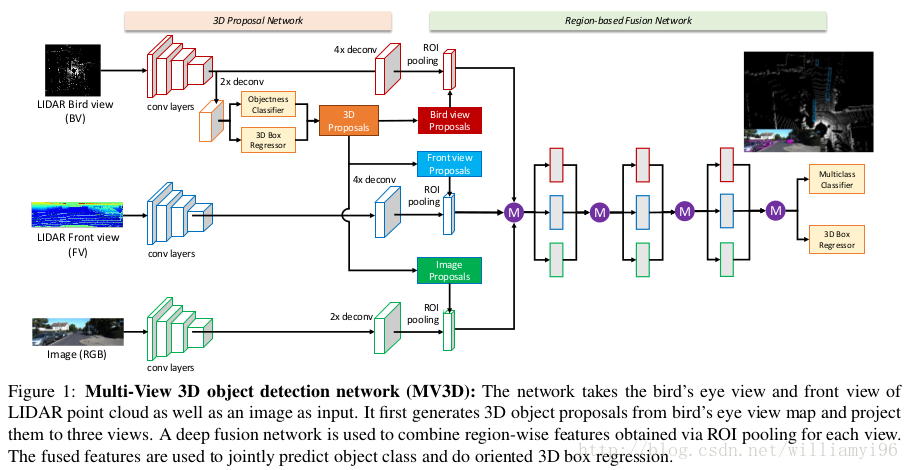
首先将雷达输入的3D点云投影到俯视图和鸟瞰图,接着用鸟瞰图通过卷积网络以及3D bounding-box回归之后生成低精度的3D proposal,然后将此3D proposal投影到俯视图,鸟瞰图和单目图像,通过一个融合网络,最后将其通过多任务损失函数进行训练。
实验结果
实验结果直接放图:

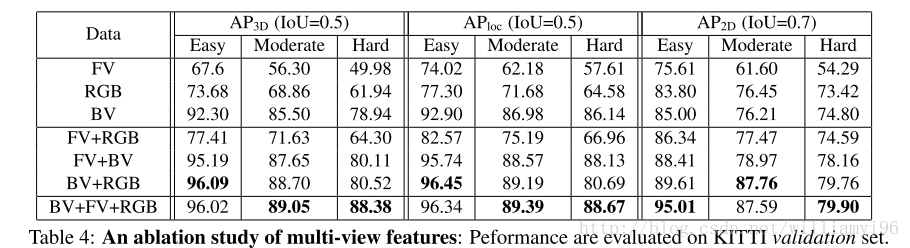
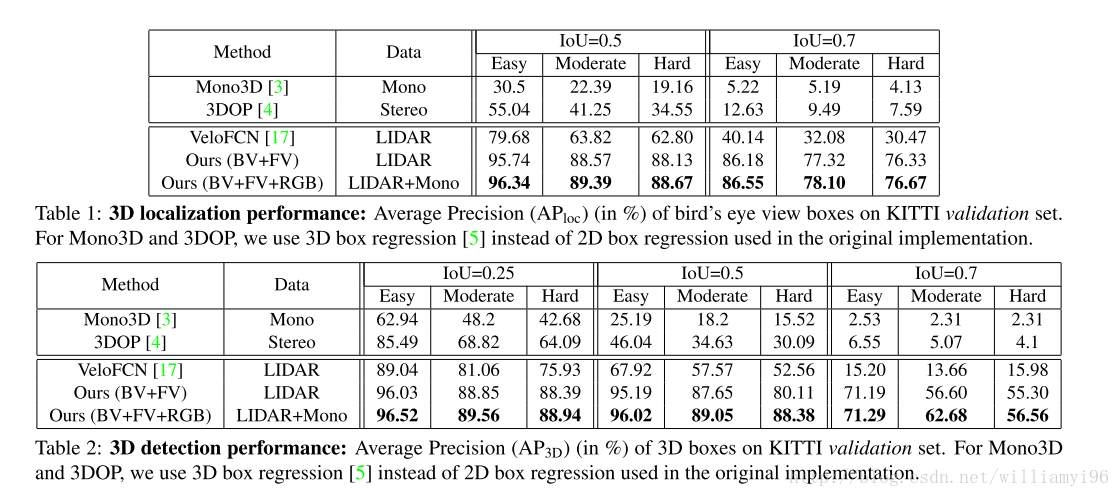
总结
该文章分析了MV3D实现的总体框架以及其当前的主要优势,由于对某些部分的实现暂时没有完全弄懂,同时处于整个框架的设计较为复杂,因此关于网络设计实现以及测试部分的内容将在后续的文章中进行分析。

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









