







教学链接:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/3-1-A-sarsa/
学习该算法之前,需要先了解Q-learning,与之进行比较,
Q-learning教程:http://blog.csdn.net/winycg/article/details/79255960
比较一下Q-learning与Sarsa的算法流程:

上述流程可以分析,Q-learning会在s'上选择产生最大期望的动作a',但是真正到s'状态要选择下一步的动作a'时,却不一定选择a'。而Sarsa在s'状态下估计的动作a'就是到状态s'后的真正选择动作。
Sarsa说到做到,通过自己真正要做的事情进行学习,属于on-policy在线学习;Q-learning说到不一定做到,通过不一定要去做的事情学习,属于off-policy离线学习。
Q learning 机器人永远都会选择最近的一条通往成功的道路, 不管这条路会有多危险;而 Sarsa 则是相当保守, 他会保证拿到宝藏是次要的,保证安全是主要的。因为Q learning算法更新时使用max Q值更新,Sarsa使用走过的路更新Q值,导致后者的Q表的负值要更多一些,所以更能避免一些陷阱。
结合Q-learning的迷宫实例,修改RL_Q_learning函数中的代码为RL_Sarsa函数,变换迷宫算法为Sarsa
import pandas as pd
import numpy as np
import random
import wx
unit = 80 # 一个方格所占像素
maze_height = 4 # 迷宫高度
maze_width = 4 # 迷宫宽度
class Maze(wx.Frame):
def __init__(self, parent):
# +16和+39为了适配客户端大小
super(Maze, self).__init__(parent, title='maze', size=(maze_width*unit+16, maze_height*unit+39))
self.actions = ['up', 'down', 'left', 'right']
self.n_actions = len(self.actions)
# 按照此元组绘制坐标
self.coordinate = (0, 0)
self.rl = Sarsa(self.actions)
self.generator = self.rl.RL_Sarsa()
# 使用EVT_TIMER事件和timer类可以实现间隔多长时间触发事件
self.timer = wx.Timer(self) # 创建定时器
self.timer.Start(200) # 设定时间间隔
self.Bind(wx.EVT_TIMER, self.build_maze, self.timer) # 绑定一个定时器事件
self.Show(True)
def build_maze(self, event):
# yield在生成器运行结束后再次调用会产生StopIteration异常,
# 使用try_except语句避免出现异常并在异常出现(程序运行结束)时关闭timer
try:
self.generator.send(None) # 调用生成器更新位置
except Exception:
self.timer.Stop()
self.coordinate = self.rl.status
dc = wx.ClientDC(self)
self.draw_maze(dc)
def draw_maze(self, dc):
dc.SetBackground(wx.Brush('white'))
dc.Clear()
for row in range(0, maze_height*unit+1, unit):
x0, y0, x1, y1 = 0, row, maze_height*unit, row
dc.DrawLine(x0, y0, x1, y1)
for col in range(0, maze_width*unit+1, unit):
x0, y0, x1, y1 = col, 0, col, maze_width*unit
dc.DrawLine(x0, y0, x1, y1)
dc.SetBrush(wx.Brush('black'))
dc.DrawRectangle(unit+10, 2*unit+10, 60, 60)
dc.DrawRectangle(2*unit+10, unit+10, 60, 60)
dc.SetBrush(wx.Brush('yellow'))
dc.DrawRectangle(2*unit+10, 2*unit+10, 60, 60)
dc.SetBrush(wx.Brush('red'))
dc.DrawCircle((self.coordinate[0]+0.5)*unit, (self.coordinate[1]+0.5)*unit, 30)
class Sarsa(object):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, epsilon_greedy=0.9):
self.actions = actions
self.alpha = learning_rate
self.gamma = reward_decay
self.epsilon = epsilon_greedy
self.max_episode = 10
self.id_status = {} # id和位置元组的字典,因为DataFrame中直接以元组为下标无法索引行
self.status = (0, 0) # 用于记录在运行过程中的当前位置,然后提供给Maze对象
# 本次设定未知Q表中的状态,所以使用check_status_exist函数将状态添加到Q表
self.Q_table = pd.DataFrame(columns=self.actions, dtype=np.float32)
def choose_action_by_epsilon_greedy(self, status):
self.check_status_exist(status)
if random.random() < self.epsilon:
status_action = self.Q_table.loc[self.id_status[status], :]
status_action = status_action.reindex(np.random.permutation(status_action.index))
action_name = status_action.idxmax()
else:
action_name = np.random.choice(self.actions)
return action_name
def get_environment_feedback(self, s, action_name):
is_terminal = False
if action_name == 'up':
if s == (2, 3):
r = 1
is_terminal = True
elif s == (1, 3):
r = -1
is_terminal = True
else:
r = 0
s_ = (s[0], np.clip(s[1]-1, 0, 3))
elif action_name == 'down':
if s == (2, 0) or s == (1, 1):
r = -1
is_terminal = True
else:
r = 0
s_ = (s[0], np.clip(s[1]+1, 0, 3))
elif action_name == 'left':
if s == (3, 1):
r = -1
is_terminal = True
elif s == (3, 2):
r = 1
is_terminal = True
else:
r = 0
s_ = (np.clip(s[0]-1, 0, 3), s[1])
else:
if s == (1, 1) or s == (0, 2):
r = -1
is_terminal = True
else:
r = 0
s_ = (np.clip(s[0]+1, 0, 3), s[1])
return r, s_, is_terminal
def update_Q_table(self, s, a, r, s_, a_, is_terminal):
if is_terminal is False:
self.check_status_exist(s_)
q_new = r + self.gamma * self.Q_table.loc[self.id_status[s_], a_]
else:
q_new = r
q_old = self.Q_table.loc[self.id_status[s], a]
self.Q_table.loc[self.id_status[s], a] = (1 - self.alpha) * q_old + self.alpha * q_new
def check_status_exist(self, status):
if status not in self.id_status.keys():
id = len(self.id_status)
self.id_status[status] = id
self.Q_table = self.Q_table.append(pd.Series([0]*len(self.actions), index=self.actions, name=id))
def RL_Sarsa(self):
# 使用yield函数实现同步绘图
for episode in range(self.max_episode):
s = (0, 0)
self.status = s
a = self.choose_action_by_epsilon_greedy(s)
yield
is_terminal = False
while is_terminal is False:
r, s_, is_terminal = self.get_environment_feedback(s, a)
a_ = self.choose_action_by_epsilon_greedy(s_)
self.update_Q_table(s, a, r, s_, a_, is_terminal)
s = s_
self.status = s
a = a_
yield
print(self.Q_table)
print(self.id_status)
if __name__ == '__main__':
app = wx.App()
Maze(None)
app.MainLoop()
Sarsa(λ)
Sarsa-lambda 是基于 Sarsa 方法的升级版, 他能更有效率地学习到怎么样获得好的 reward。lambda是一个衰变值, 可以让你知道离奖励越远的步并不是让你最快拿到奖励的步, 所以我们想象我们站在宝藏的位置, 回头看看我们走过的寻宝之路, 离宝藏越近的脚印越看得清, 远处的脚印太渺小, 我们都很难看清, 那我们就索性记下离宝藏越近的脚印越重要, 越需要被好好的更新。
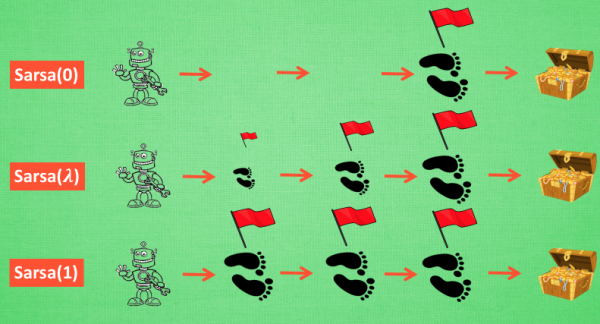
λ是脚步衰减值, 都是一个在0和1 之间的数.
当λ=0, 就变成了Sarsa 的单步更新, 只更新获取到 reward 前经历的最后一步。当λ=1, 就变成了回合更新, 对所有步更新的力度都是一样.
当λ∈(0 ,1) , 取值越大, 离宝藏越近的步更新力度越大. 这样我们就不用受限于单步更新的每次只能更新最近的一步, 我们可以更有效率的更新所有相关步
算法过程如下:

E为eligibility_trace表,为随着时间衰减 eligibility trace 的值, 离获取 reward 越远的步, 不可或缺值越小。
以下有两种E表的更新方式:
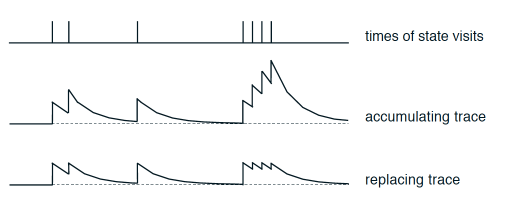
accumulating trace为累加方式,每访问一次此状态,值+1;replacing trace前者的标准化,最大为1。算法中使用的为前者,在代码中使用后者,效果要更好。标准化过程采用将[s,:]置0,[s,a]置1的方法,因为在寻找的过程中,如果走到了之前到过的状态s,那么就可以舍弃,因为是探索过程中的无效状态。
Q表的更新原则为之前经历的全部状态都要更新值,只是权重不同。
新代码中主要修改了update_Q_table函数中的内容:
import pandas as pd
import numpy as np
import random
import wx
unit = 80 # 一个方格所占像素
maze_height = 4 # 迷宫高度
maze_width = 4 # 迷宫宽度
class Maze(wx.Frame):
def __init__(self, parent):
# +16和+39为了适配客户端大小
super(Maze, self).__init__(parent, title='maze', size=(maze_width*unit+16, maze_height*unit+39))
self.actions = ['up', 'down', 'left', 'right']
self.n_actions = len(self.actions)
# 按照此元组绘制坐标
self.coordinate = (0, 0)
self.rl = SarsaLambda(self.actions)
self.generator = self.rl.RL_Sarsa_Lambda()
# 使用EVT_TIMER事件和timer类可以实现间隔多长时间触发事件
self.timer = wx.Timer(self) # 创建定时器
self.timer.Start(200) # 设定时间间隔
self.Bind(wx.EVT_TIMER, self.build_maze, self.timer) # 绑定一个定时器事件
self.Show(True)
def build_maze(self, event):
# yield在生成器运行结束后再次调用会产生StopIteration异常,
# 使用try_except语句避免出现异常并在异常出现(程序运行结束)时关闭timer
try:
self.generator.send(None) # 调用生成器更新位置
except Exception:
self.timer.Stop()
self.coordinate = self.rl.status
dc = wx.ClientDC(self)
self.draw_maze(dc)
def draw_maze(self, dc):
dc.SetBackground(wx.Brush('white'))
dc.Clear()
for row in range(0, maze_height*unit+1, unit):
x0, y0, x1, y1 = 0, row, maze_height*unit, row
dc.DrawLine(x0, y0, x1, y1)
for col in range(0, maze_width*unit+1, unit):
x0, y0, x1, y1 = col, 0, col, maze_width*unit
dc.DrawLine(x0, y0, x1, y1)
dc.SetBrush(wx.Brush('black'))
dc.DrawRectangle(unit+10, 2*unit+10, 60, 60)
dc.DrawRectangle(2*unit+10, unit+10, 60, 60)
dc.SetBrush(wx.Brush('yellow'))
dc.DrawRectangle(2*unit+10, 2*unit+10, 60, 60)
dc.SetBrush(wx.Brush('red'))
dc.DrawCircle((self.coordinate[0]+0.5)*unit, (self.coordinate[1]+0.5)*unit, 30)
class SarsaLambda(object):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, epsilon_greedy=0.9, trace_decay=0.9):
self.actions = actions
self.alpha = learning_rate
self.gamma = reward_decay
self.epsilon = epsilon_greedy
self.lambda_decay = trace_decay
self.max_episode = 100
self.id_status = {} # id和位置元组的字典,因为DataFrame中直接以元组为下标无法索引行
self.status = (0, 0) # 用于记录在运行过程中的当前位置,然后提供给Maze对象
# 本次设定未知Q表中的状态,所以使用check_status_exist函数将状态添加到Q表
self.Q_table = pd.DataFrame(columns=self.actions, dtype=np.float32)
self.E_table = pd.DataFrame(columns=self.actions, dtype=np.float32)
def choose_action_by_epsilon_greedy(self, status):
self.check_status_exist(status)
if random.random() < self.epsilon:
status_action = self.Q_table.loc[self.id_status[status], :]
status_action = status_action.reindex(np.random.permutation(status_action.index))
action_name = status_action.idxmax()
else:
action_name = np.random.choice(self.actions)
return action_name
def get_environment_feedback(self, s, action_name):
is_terminal = False
if action_name == 'up':
if s == (2, 3):
r = 1
is_terminal = True
elif s == (1, 3):
r = -1
is_terminal = True
else:
r = 0
s_ = (s[0], np.clip(s[1]-1, 0, 3))
elif action_name == 'down':
if s == (2, 0) or s == (1, 1):
r = -1
is_terminal = True
else:
r = 0
s_ = (s[0], np.clip(s[1]+1, 0, 3))
elif action_name == 'left':
if s == (3, 1):
r = -1
is_terminal = True
elif s == (3, 2):
r = 1
is_terminal = True
else:
r = 0
s_ = (np.clip(s[0]-1, 0, 3), s[1])
else:
if s == (1, 1) or s == (0, 2):
r = -1
is_terminal = True
else:
r = 0
s_ = (np.clip(s[0]+1, 0, 3), s[1])
return r, s_, is_terminal
def update_Q_table(self, s, a, r, s_, a_, is_terminal):
if is_terminal is False:
self.check_status_exist(s_)
q_new = r + self.gamma * self.Q_table.loc[self.id_status[s_], a_]
else:
q_new = r
q_old = self.Q_table.loc[self.id_status[s], a]
delta = q_new - q_old
self.E_table.loc[self.id_status[s], :] = 0
self.E_table.loc[self.id_status[s], a] = 1
self.Q_table = self.Q_table + self.alpha*delta*self.E_table
self.E_table *= self.gamma * self.lambda_decay
def check_status_exist(self, status):
if status not in self.id_status.keys():
id = len(self.id_status)
self.id_status[status] = id
self.Q_table = self.Q_table.append(pd.Series([0]*len(self.actions), index=self.actions, name=id))
self.E_table = self.E_table.append(pd.Series([0]*len(self.actions), index=self.actions, name=id))
def RL_Sarsa_Lambda(self):
# 使用yield函数实现同步绘图
for episode in range(self.max_episode):
self.E_table *= 0
s = (0, 0)
self.status = s
a = self.choose_action_by_epsilon_greedy(s)
is_terminal = False
yield
while is_terminal is False:
r, s_, is_terminal = self.get_environment_feedback(s, a)
a_ = self.choose_action_by_epsilon_greedy(s_)
self.update_Q_table(s, a, r, s_, a_, is_terminal)
s = s_
self.status = s
a = a_
yield
print(self.Q_table)
print(self.id_status)
if __name__ == '__main__':
app = wx.App()
Maze(None)
app.MainLoop()














 3795
3795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









