







基于潜在(隐藏)因子的推荐,常采用SVD或改进的SVD++
奇异值分解(SVD):
考虑CF中最为常见的用户给电影评分的场景,我们需要一个数学模型来模拟用户给电影打分的场景,比如对评分进行预测。
将评分矩阵U看作是两个矩阵的乘积:
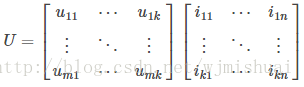
其中,uxy 可以看作是user x对电影的隐藏特质y的热衷程度,而iyz可以看作是特质 y 在电影 </
 本文介绍了奇异值分解(SVD)在协同过滤(CF)推荐系统中的应用,通过数学模型解释了如何预测用户对电影的评分,并引入baseline predictor以考虑用户和电影的个体差异。随后,讨论了SVD++的改进,它利用用户评价行为的隐含信息,通过增加隐式参数来提高模型精度。模型参数通过优化目标函数,如梯度下降或迭代最小二乘算法进行求解。
本文介绍了奇异值分解(SVD)在协同过滤(CF)推荐系统中的应用,通过数学模型解释了如何预测用户对电影的评分,并引入baseline predictor以考虑用户和电影的个体差异。随后,讨论了SVD++的改进,它利用用户评价行为的隐含信息,通过增加隐式参数来提高模型精度。模型参数通过优化目标函数,如梯度下降或迭代最小二乘算法进行求解。
基于潜在(隐藏)因子的推荐,常采用SVD或改进的SVD++
奇异值分解(SVD):
考虑CF中最为常见的用户给电影评分的场景,我们需要一个数学模型来模拟用户给电影打分的场景,比如对评分进行预测。
将评分矩阵U看作是两个矩阵的乘积:
其中,uxy 可以看作是user x对电影的隐藏特质y的热衷程度,而iyz可以看作是特质 y 在电影 </

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1697
1697





