







MySQL概述及性能调优
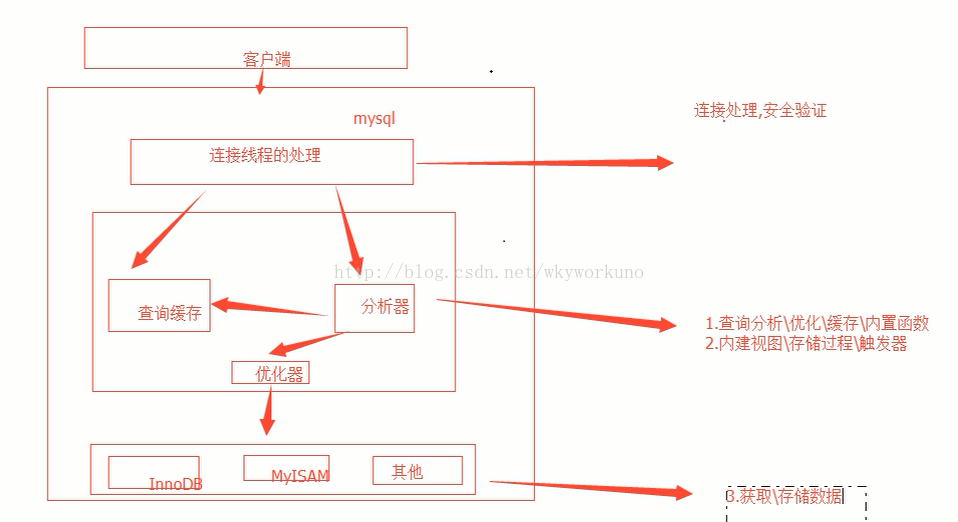
一、基本架构
1.服务层:处理客户端和服务端的链接、安全验证
2.核心层:查询分析,优化,缓存,内置函数 内建的视图/存储过程/触发器(是开发数据库和读MySQL源码最应该关注的地方)
3.储存引擎层:负责数据的存取,通过存储引擎的API和存储引擎通信,遮蔽了存储引擎之间的差异
图解:
二、选择版本
MariaDB数据库-->开源,完全兼容MySQL,使用了XtraDB引擎,代替MySQL 的InnoDB引擎
四个版本:
企业版:收费
社区版:开源免费 用的人多
Percona Server:新特性多,不稳定
MariaDB:国内用的不多
三、配置文件详解
位置:/etc/my.cnf
1.max_connections:MySQL允许的同时会话数 当MySQL到了一个最大连接数上限的时候,其中一个连接将会保留作为管理员使用 Too many connections-->同时会话数设置小了,将其增大
2.max_connect_erros 最大错误允许数,默认是50 使用FLUSH HOSTS或者重启服务,这样报错的记录就会消失(这个错误不是指的删除数据的错误,而是连接本身的错误,当错误的次数达到的时候就无法连接了,会阻塞这个连接)
3.key_buffer_size:关键词缓冲区大小,用来缓存MyISAM索引块,这个值决定了索引值处理速度,尤其是读取索引处理速度
4.max_allowed_packet:设置最大包,限制了server接受数据块的大小,避免超长的sql执行,当服务器收到大于这个信息包的时候会发出信息包过大这个报错,关闭链接,节约资源(报错:丢失与MySQL服务器连接)
5.thread_cache_size:服务器线程缓存,可以重新利用保存在缓存中的线程数据,可以将线程中的缓存数据缓存下来,当缓存中还有空间的时候,服务端/客户端的线程断开,他将会存放在缓存当中,当客户端重新连接的时候,从缓存中把链接取出来重新使用。如果缓存是空的或者新的请求的话,那么线程将会被重新创建,这样是为了避免重复建立大量线程,减少资源的消耗
6.thread_concurrency:CPU核数x2,设置错误后,MySQL不能很好利用多核处理器性能,不要瞎设!
7.sort_buffer_size:每个连接使用buffer分配的内存大小,不是越大越好,高并发的时候,比如20W个连接,这个值设为1M,将消耗20Wx1M=200GB内存左右,而一般单机才128G。
8.join_buffer_size:join表使用的缓存大小
9.query_cache_size:查询缓存大小,mysql会将查询的结果缓存下来,当下次的时候就将其直接返回,缓存期间相关表必须没有变更,否则失效,多写操作数据库设置大了会影响写入效率(千万不能线上建索引)
10.read_buffer_size:MyISAM全表扫描时候的缓冲大小,而且无法通过添加索引来优化全表扫描, 增大会优化
11.read_rnd_buffer_size:从排序好的数据中读取行时,行数据会从缓冲区读取,这个值会提升order by性能。注意mysql会为每个客户端申请这个缓冲区,并发过大,设置过大影响内存开销。
12.myisam_sort_buffer_size:MyISAM表发生变化时,重新排序所需缓存大小
13.innodb_buffer_size:InnoDB使用缓存保存索引 原始数据 缓存大小,可以有效减少读取数据所需的磁盘IO(通过多次试验得知对MySQL性能调优innodb_buffer_size参数可以有效减少读取数据的磁盘IO)
14.innodb_log_file_size:数据日志文件大小,大的值可以提高性能,但增加了恢复故障数据库的时间(通过修改innodb_log_file_size可以提高性能,但是与此同时增加了恢复故障数据库的时间)
15.innodb_log_buffer_size:日志文件缓存 增大该值可以提高性能,但增大了忽然宕机损失数据的风险(宕机时候缓存就没了)
16.innodb_flush_log_at_trx_commit:执行事务的时候,会往innodb存储引擎 日志缓存插入事务日志(当事务提交的时候必须将存储引擎的缓存写入磁盘,也就是写数据前先写日志,这个叫做预写日志方式)当这个参数设置为0时,表示每秒日志缓存写入文件,文件实时写入磁盘,当设置为1时,缓存实时写入文件,文件实时写入磁盘(双实时),当为2的时候,缓存实时写入文件,每秒日志文件写入磁盘
17.innodb_lock_wait_timeout:被回滚前一个InnoDB事务应该等待一个锁被批准多久(当InnoDB自动检测这个事务是否死锁并自动回滚,如果使用locktables指定,或者事务中使用了InnoDB外的存储引擎,那么这个死锁就很可能发生了,而InnoDB无法检测到死锁发生,这个时候这个值有用)
四、软件优化
1.选合适的引擎
MySQL5.1默认的是MyISAM引擎,MySQL5.5、5.6用的是InnoDB引擎。
MyISAM索引顺序访问方法,优点是支持全文索引,但非事务安全,不支持外键,是表级锁。
有三个文件,可以恢复数据,FRM文件存放表结构,MYD文件存放数据,MYI存放索引
InnoDB事务性存储引擎,行锁(但也不绝对,因为执行更新语句时无法确定范围的时候也会锁表,例如:update table set age=3 where name like “%jeff%”,也会锁表),这个引擎可以回滚,可以崩溃恢复,也可以ACID事务控制 InnoDB表和索引放在一个表空间里面,表空间里面有多个文件
2.正确使用索引(书的目录就是类似于索引的一种,是用来帮助读者找到相应的章节)
a.给合适的列建立索引 如where子句经常需要给检索建立索引,又或者连接子句,而不应该是select选择列表建立索引
b.索引值应该不尽相同 对于唯一性的值,索引效果最好(对于在百度员工表里面,员工ID肯定是最好,因为员工号不重复,而如果对男女或者叫张三的话因为有多个所以建立索引的效果不是最好的,当有大量重复效果很差)
c.使用短索引 对字符类型的列进行索引,有可能都要指定前缀长度,例如:char(50) 但是前20个字符内很多都是唯一的(时间戳),后面是一样的,对于较小的索引,索引缓存一定,存的索引多,消耗磁盘IO少,能提高查找速度
d.最左前缀 数据如何取名字应该是按照最左前缀的原则,这样好设计索引,索引缓存的更多,查找速度就提升了。n列索引 多个索引能够起n列索引的作用,可以最左列的值进行匹配
e.like查询的时候索引失效,尽量少用like(可以写一个带like版本的和一个不带like版本的,写带like版本的是因为能够实现功能,写不带like版本的是因为索引会失效,能够提高并发性能,所以我们实际业务中应该少用带like版本的)对于百万、千万的数,要用like的话,尽量用一些开源的东西-->用Sphinx开源方案结合MySQL进行全文检索类似like的功能
f.不能滥用索引
1.索引占用空间,降低性能
2.更新数据,索引必须更新,索引会越来越多,会花费时间,所以尽量不要在长期不用的字段上建立索引
3.SQL语句执行一个查询语句进行优化时,可能不是最佳的索引,增加查询时间
3.避免使用select *
1.返回结果多,降低查询速度
2.返回过多的返回结果,增大服务器返回给App端的数据传输量。网络传输速度慢,弱网络环境下,会容易造成请求失效
4.字段尽量设置为NOT NULL
“”和NULL是两回事
例如:服务端给后台传一个json字段{“name”:“”}{“hobby”:空Array}null占空间 安卓判断“”还是NULL 在java和OC中的强类型,NULL和空值是不一样的,会造成App闪退
五、硬件优化
1.增加物理内存,因为MySQL读写数据最大的凭据是磁盘IO,可以提高磁盘IO
Linux内核 内存开缓存 存放数据的方式:
写文件 文件延迟写入机制,先把文件放到缓存中,达到一定程度写入文件
读文件 读文件到缓存中,下次需要相同文件时,从缓存中取,而不是从硬盘中取出
2.增加应用缓存
a.本地缓存
数据放到服务器内存或文件中
b.分布式缓存
Redis、memcache 读写性能非常高 QPS 每秒查询请求数达到1W以上
数据持久化用Redis 数据不持久化 两者都可以
3.固态硬盘SSD代替机械硬盘
a.日志和数据分来存储 日志肯定顺序读写放在机械硬盘 数据随机读写放在SSD
b.调整参数 innodb_flush_method=O_DIRECT 告诉操作系统禁用缓存 fsync(异步)方式数据刷入机械硬盘 innodb_io_capacity=10000 控制mysql一次刷新脏页面的数量,因为使用SSD之后IO能力增强,需要增大一次刷新脏页的数量
4.SSD+SATA混合存储
FlashCache是facebook的一个开源技术,在文件系统和设备驱动之间加了一层缓存 对热数据缓存
六、架构优化
1.分表
a.水平拆分:数据分成多个表
b.垂直拆分:字段分成多个表
c.MyISAM MERGE存储引擎, InnoDB用alter table 将n个子表合成一个整表,但实际上是n个子表
2.读写分离
读是一些机器,写是一些机器,有二进制文件的主从复制 还有延迟的解决方案
3.分库
Mycat部署的工作流程
七、SQL慢查询
是调参数
八、活用存储结构
我有一个内容表,给我三个字段id user_id content, 当我的字段要变得很多的时候,可以分成索引表和内容表,索引表里面放字段,内容表里面放数据,使用key-value键值对存放数据,这样能够使得存储结构灵活起来
九、故障排除案例
App服务商家,后台数据库load居高不下
解决:使用like查询,在这个时候因为不能用索引,需要遍历上百万的数据,性能低下,这个时候使用Sphinx Coreseek开源全文检索














 8102
8102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









