







Clustered Variance模块调整聚类的标准误。例如,将一个数据集合复制100次,不应该增加参数估计的精度,但是在符合独立同分布假设(Independent Identically Distributed,IID)下执行这个过程实际上会提高精度。另一个例子是在教育经济学的研究中,有理由期望同一个班里孩子的误差项不是独立的。聚类标准误可以解决这个问题。
MADlib的聚类方差(Clustered Variance)模块包含计算线性、逻辑和多类逻辑回归问题的函数。
聚类方差线性回归训练函数
聚类方差线性回归训练函数具有以下语法:
clustered_variance_linregr ( source_table,
out_table,
dependent_varname,
independent_varname,
clustervar,
grouping_cols
)参数
source_table:TEXT类型,包含训练数据的表的名称。
out_table:VARCHAR类型,包含输出模型的生成表的名称。输出表包含以下列:
- coef:DOUBLE PRECISION[]类型,回归系数向量。
- std_err:DOUBLE PRECISION[]类型,系数标准误向量。
- t_stats:DOUBLE PRECISION[]类型,系数的t统计向量。
- p_values:DOUBLE PRECISION[]类型,系数的p值向量。
还会创建一个名为<out_table>_summary的汇总表,它与linregr_train函数创建的汇总表相同。有关详细信息,请参阅线性回归的文档。
dependent_varname:TEXT类型,用于评估因变量的表达式。
independent_varname:TEXT类型,用于评估自变量的表达式。
clustervar:TEXT类型,用作聚类变量列的逗号分隔列表。
grouping_cols(可选):TEXT类型,缺省值为NULL,当前未实现,忽略任何非NULL值。一个列表表达式,类似于SQL GROUP BY子句,用于将输入数据集分组为离散组,每组运行一次回归。当此值为空时,不使用分组,并生成单个结果模型。
聚类方差逻辑回归训练函数
聚类方差逻辑回归训练函数具有以下语法:
clustered_variance_logregr( source_table,
out_table,
dependent_varname,
independent_varname,
clustervar,
grouping_cols,
max_iter,
optimizer,
tolerance,
verbose_mode
)参数
source_table:TEXT类型,包含训练数据的表的名称。
out_table:VARCHAR类型,包含输出模型的生成表的名称。输出表包含以下列:
- coef:回归系数向量。
- std_err:系数标准误向量。
- z_stats:DOUBLE PRECISION[]类型,系数的z统计向量。
- p_values:DOUBLE PRECISION[]类型,系数的p值向量。
还会创建一个名为<out_table>_summary的汇总表,它与logregr_train函数创建的汇总表相同。有关详细信息,请参阅逻辑回归的文档。
dependent_varname:TEXT类型,用于评估因变量的表达式。
independent_varname:TEXT类型,用于评估自变量的表达式。
clustervar:TEXT类型,用作聚类变量列的逗号分隔列表。
grouping_cols(可选):TEXT类型,缺省值为NULL,当前未实现,忽略任何非NULL值。一个列表表达式,类似于SQL GROUP BY子句,用于将输入数据集分组为离散组,每组运行一次回归。当此值为空时,不使用分组,并生成单个结果模型。
max_iter(可选):INTEGER类型,缺省值为20。允许的最大迭代次数。
Optimizer(可选):TEXT类型,缺省值为‘irls’。使用的优化器名称:
- ‘newton’或‘irls’:迭代再加权的最小二乘。
- ‘cg’: 共轭梯度。
- ‘igd’:递增梯度下降。
Tolerance(可选):FLOAT8类型,缺省值为0.0001。表明收敛的连续迭代中对数似然值之间的差异,以便在n次迭代完成后停止执行。零不能用作收敛标准。
verbose_mode(可选):BOOLEAN类型,缺省值为FALSE。提供训练结果的详细输出。
聚类方差多类逻辑回归训练函数
clustered_variance_mlogregr( source_table,
out_table,
dependent_varname,
independent_varname,
cluster_varname,
ref_category,
grouping_cols,
optimizer_params,
verbose_mode
)参数
source_table:TEXT类型,包含输入数据的表的名称。
out_table:TEXT类型,存储回归模型的表的名称。输出表包含以下列:
- category:类别。
- ref_category:用于建模的参考类别。
- coef:回归系数向量。
- std_err:系数标准误向量。
- z_stats:系数z统计向量。
- p_values:系数p值向量。
还会创建一个名为<out_table>_summary的汇总表,它与mlogregr_train函数创建的汇总表相同。有关详细信息,请参阅多类逻辑回归的文档。
dependent_varname:TEXT类型,用于评估因变量的表达式。
independent_varname:TEXT类型,用于评估自变量的表达式。
cluster_varname TEXT类型,用作聚类变量列的逗号分隔列表。
ref_category(可选):INTEGER类型,范围在[0,num_category)中的引用类别。
groupingvarng_cols(可选):TEXT类型,缺省值为NULL,当前未实现,忽略任何非NULL值。用作分组变量的逗号分隔列列表。
optimizer_params(可选):TEXT类型,缺省值为NULL,使用优化器参数的默认值: max_iter=20, optimizer=‘newton’, tolerance=1e-4。应该是一个包含由逗号分隔的‘key = value’对的字符串。
verbose_mode(可选):BOOLEAN类型,缺省值为FALSE。如果为TRUE,则在计算逻辑回归时打印详细信息。
Cox比例风险模型的聚类方差
Cox比例危险模型的聚类稳健方差估计函数具有以下语法:
clustered_variance_coxph(model_table,output_table, clustervar)参数
model_table:TEXT类型。模型表的名称,与coxph_train()函数的‘output_table’参数完全相同。
output_table:TEXT类型。保存输出表的名称,有以下几列:
- coef:FLOAT8[]类型,系数向量。
- loglikelihood:FLOAT8类型,极大似然估计(Maximum Likelihood Estimate,MLE)的对数似然值。
- std_err:FLOAT8[]类型,系数标准误向量。
- clustervar:TEXT类型,用作聚类变量列的逗号分隔列表。
- clustered_se:FLOAT8[]类型,系数的稳健标准误向量。
- clustered_z:FLOAT8[]类型,系数的稳健z统计向量。
- clustered_p:FLOAT8[]类型,系数的稳健p值向量。
- hessian:FLOAT8[][]类型,黑塞矩阵(Hessian Matrix)。
clustervar:TEXT类型,用作聚类变量列的逗号分隔列表。
示例
1. 查看聚类方差线性回归函数的联机帮助。
SELECT madlib.clustered_variance_linregr();2. 运行线性回归函数并查看结果。
DROP TABLE IF EXISTS out_table;
SELECT madlib.clustered_variance_linregr( 'abalone',
'out_table',
'rings',
'ARRAY[1, diameter, length, width]',
'sex',
NULL
);
SELECT * FROM out_table;3. 查看聚类方差逻辑回归函数的联机帮助。
SELECT madlib.clustered_variance_logregr();4. 运行逻辑回归函数并查看结果。
DROP TABLE IF EXISTS out_table;
SELECT madlib.clustered_variance_logregr( 'abalone',
'out_table',
'rings < 10',
'ARRAY[1, diameter, length, width]',
'sex'
);
SELECT * FROM out_table;5. 查看聚类方差多类逻辑回归函数的联机帮助。
SELECTmadlib.clustered_variance_mlogregr();6. 运行多类逻辑回归并查看结果。
DROP TABLE IF EXISTS out_table;
SELECT madlib.clustered_variance_mlogregr( 'abalone',
'out_table',
'CASE WHEN rings < 10 THEN 1 ELSE 0 END',
'ARRAY[1, diameter, length, width]',
'sex',
0
);
SELECT * FROM out_table;7. 运行Cox比例风险回归,并计算聚类稳健估计。
DROP TABLE IF EXISTS lung_cl_out;
DROP TABLE IF EXISTS lung_out;
DROP TABLE IF EXISTS lung_out_summary;
SELECT madlib.coxph_train('lung',
'lung_out',
'time',
'array[age, "ph.ecog"]',
'TRUE',
NULL,
NULL);
SELECT madlib.clustered_variance_coxph('lung_out',
'lung_cl_out',
'"ph.karno"');
SELECT * FROM lung_cl_out;注意
请注意,我们需要在自变量表达式中手动包含一个截距项。groupingvar的NULL值表示在计算中没有分组。
技术背景
假设数据可以分成 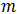
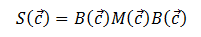
面包部分与Huber-White三明治估计量相同
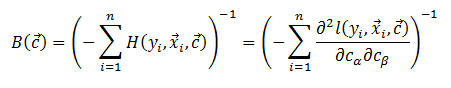
其中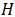
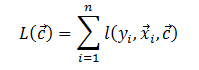
肉的部分是不同的:
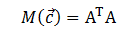
其中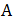
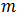
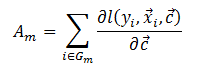
其中
我们可以通过一个聚合函数在一次扫描数据表期间,计算每个聚类的
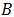
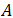
在计算多类逻辑回归的聚类方差时,它使用默认的参考类别为零,回归系数包含在输出表中。输出的回归系数与多类逻辑回归函数的顺序相同。对于K个因变量(1,...,K)和J个类别(0,...,J-1)的问题,令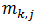















 2872
2872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









