









写在前面的话:
请允许我废话几句。这个系列的文章发布的时间是在我完成了Storm的项目开发之后才找出来时间写的,在研究Storm过程中,国内较好的参考文章实在有限,大多是入门和概念剖析。Storm的GoogleGroup对于新手来说实在不友好。有经验人士都不愿意回答新手的一些“愚蠢”的问题。现在因为Storm移交了Apache,正式启用了ApacheMailGroup就更不友好了……中间我走过不少弯路,自己摸索和看源码。虽然说自己理解的才是最深刻的,但是我觉得还是分享出来,减少大家走弯路时间,把注意力更多的放在Storm的应用探讨上。或许文章中会有错误,或许文章会“太监”,或许你只是遇到了一篇笔记而已。
介绍文章内写太多基本原理性东西,反而容易让人晕,所以在本篇中,只是点出基本概念模型,同时share一些基本资料给能力强的同学去研究。
转载请注明:转自http://blog.csdn.net/xeseo/article/details/17674775
有关Storm的一些信息片
Storm是由twitter在2011开源出来的产品,现在贡献给了Apache。
1. Storm官方主页:http://storm-project.net/ 看上去不是非常的Apache,所以以后有可能改为Apache的URL样式。
这个主页目前信息量有限。大多数好东西,在其github首页:https://github.com/nathanmarz/storm (最近刚刚把repo转移了到Apache孵化项目页https://github.com/apache/incubator-storm)
2. 最重要的东西在这:https://github.com/nathanmarz/storm/wiki ,与Storm相关的概念性知识90%都在这里了。
不过作者把文章目录直接交给了github的Pages来管理,对于github新手来说可能会忽视这个有用的页面:https://github.com/nathanmarz/storm/wiki/_pages
3. 国内分享内容有深度的blog非StormContributor之一的徐明明的blog莫属:http://xumingming.sinaapp.com/category/storm/ 显然他不愧是Storm的贡献者之一啊,连文档管理都有Storm的风格。。。。。。
4. 写的非常好的,有图有证据的量子恒道官方博客Storm系列:http://blog.linezing.com/category/storm-quick-start?spm=0.0.0.0.rTjmpX
Storm是什么?
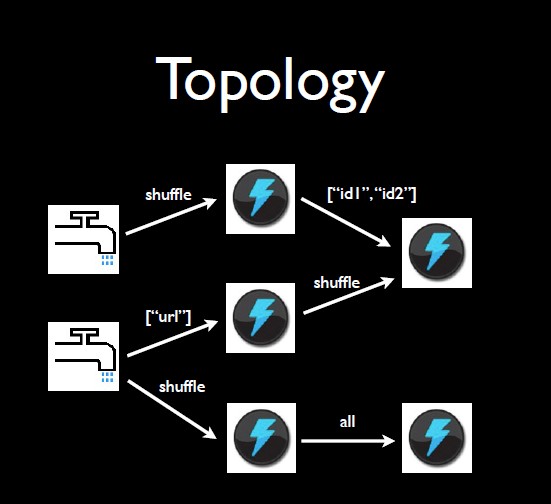
基本模型
- 数据来源定义为Spout,源源不断的供给水流。
- 水流在管道中流行,定义为Stream。
- 每个住户都会消费水,是Stream中的一个节点,定义为Bolt。可能会将消费的水排放,也或许不排。
- 一个小区的Spout、Stream、Bolt组合在一起,即一个拓扑结构,定义为Topology。
Storm的特点
- 支持很多用户场景:
- 处理消息->更新db,典型的流处理
- 不停的实时查询,并把查询结果反馈给客户端
- 通过其分布式框架,实现并行计算,把计算结果交给客户端(distribute RPC)
- 纵向扩展性
- 可以在Topology中的定义Spout、Bolt的并行度
- 保证无数据丢失
- 健壮
- Storm的健壮是因为它只关系最核心的功能,弱化管理。因为简单而健壮。
- 容错能力
- 这个其实Storm的设计原则。Storm的任意节点,理论上都应该是一直运行而不停止的,即使遇到错误,直到被停止。后面的文中,我会提到如何正确的处理错误。
- 多语言支持
基本工作框架

nimbus
很形象的取名,雨云,产生雨点的。它的作用有:
- 整个topology的发起者,会把topology的jar包缓存到本地
- 在提交topology时,分配资源
- 在topology运行时,监听所有worker的心跳
- 当某worker挂掉或收到重新分配请求时,重新分配资源
supervisor
真正的工作节点。在其内部运行的可能是一个spout、亦可能是一个bolt。
- 每一个supervisor会定义若干worker,每一个worker其实是一个独立的JVM进程,具有不同的端口号
- 每一个worker内会维护一个线程池,每一个线程,在Storm中称为executor
- 并行中的每一个spout、bolt对于supervisor中的worker来说是平等的,被认为是一个task。该task的执行会被worker分配到其内部线程池中的某一个或多个线程,即某一个或多个executor去执行
- executor的数量<=spout数+bolt数+acker数 <= task总数。默认情况下是取=
注: acker 是个什么东西,后面的文章会讲述。这里暂且不提。
举例:

在该例子中,
blue spout并行度 = 2
green bolt并行度= 2
yellow bolt并行度 = 6
在不计acker的情况下,默认总的线程数 = 2+2+6 = 10. 两个节点的两个worker,在平均分配下,就是每个节点5个,即每个worker的线程池中有5个executor。
均匀分配,两个worker各得三个yellow bolt, 一个blue spout,和一个green bolt。
但是,green bolt在配置时,表明需要两个executor和四个task。所以在两个worker上,每个其实要处理 3(yellow bolt) + 1(blue spout) + 2(green bolt) = 6个task。
由于每个worker我们只配了5个executor,所以这6个task就在5个executor上轮循执行。而事实上,Storm做了优化,对于同一个类型的task,会交由同一个executor去处理。
所以,在每个节点上,会有固定的3个executor去执行yellow bolt, 一个固定的executor去执行blue spout,一个固定的executor去执行两个green spout。
zookeeper
zookeeper是Storm分布信息存储的地方。
- nimbus会在zookeeper上建立topology的相关信息(包括如何分配)
- supervisor会监听zookeeper,一旦有新的分配任务,就会去领下来去交由worker执行
- zookeeper会保存worker的心跳情况,如果nimbus发现某个worker心跳丢失,就会重新分配资源
所以,这里真正会影响到集群运行的是zookeeper。一旦zookeeper挂掉,整个Storm就无法工作了。

















 1692
1692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









