







 本文探讨了一种结合多级注意力机制的卷积神经网络模型用于关系提取,通过分配不同权重给文本中的词语,提高了模型对实体关系的识别效果。模型包括输入级和池化级的注意力机制,并采用改进的目标函数优化关系分类。
本文探讨了一种结合多级注意力机制的卷积神经网络模型用于关系提取,通过分配不同权重给文本中的词语,提高了模型对实体关系的识别效果。模型包括输入级和池化级的注意力机制,并采用改进的目标函数优化关系分类。
作者:xg123321123
出处:http://blog.csdn.net/xg123321123/article/details/553163257
声明:版权所有,转载请联系作者并注明出处
1 问题定义
关系提取用于从文本中抽取结构化事实。
2 背景综述
- 除了少数无监督方法,大部分方法都是将关系提取转化为多分类问题来做;
- 传统的基于特征的方法要么依赖于手工提取的特征,要么依赖于精心设计的kernel,这些方法不仅容易出错,提取特征的能力也是有限的,当应用到新的领域时不够鲁棒;
- 近年来出现的神经网络模型取得了一定成果,但模型较为复杂,要么是需要外部依赖,要么是需要训练多个子模型。
3 灵感来源
- 现实世界中,同一关系可以被表达为很多种形式,这就要求模型不仅得考虑词级信息,还得考虑句级和语义级别的信息;
- 有很多手工设计提取特征的模型;
- 也有一些基于神经网络的模型,但大多需要外部依赖,同时,对于关键信息的捕捉还不理想。
4 方法概述
将attention机制加入到神经网络中,对于反映实体关系更重要的词语给予更大的权重,辅以改进后的目标函数,从而提高关系提取的效果。
整体结构示意图如下:
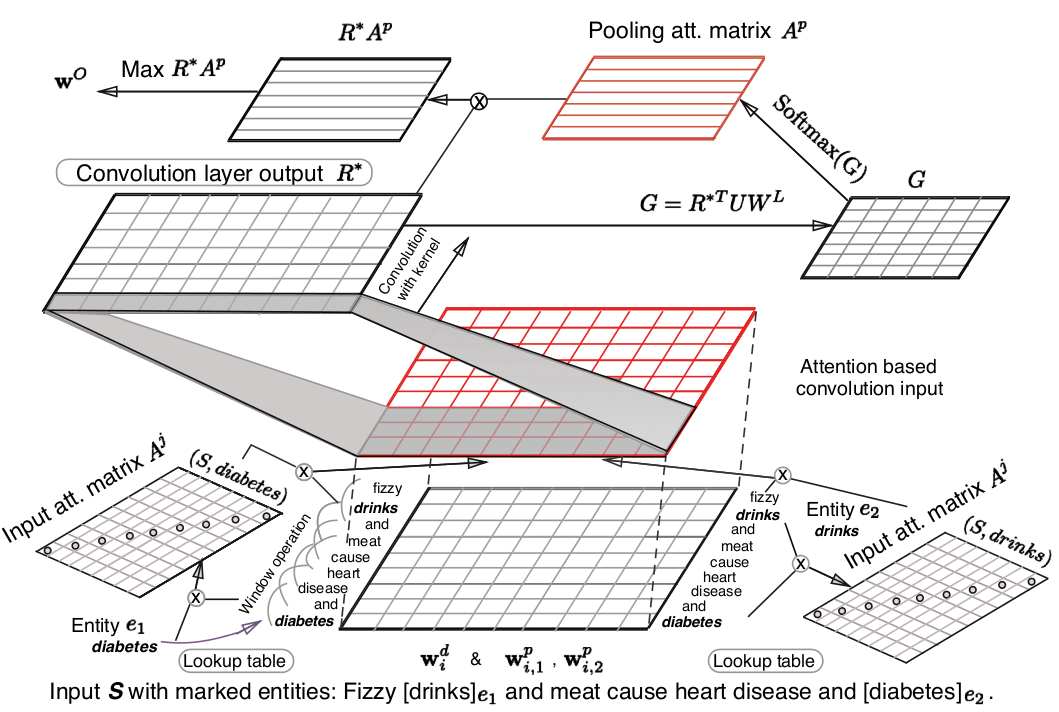
- 将attention机制应用在输入序列中,用于学习输入语句中各部分对两个实体的注意力;
- 将attention机制应用在池化层上,用于学习目标类别的注意力;
- 改进了目标函数,使其在关系提取上表现得更好。
输入表示
对于一个句子 S=(w1,w2,...wn) ,有两个标记的实体 e1(wp) 和 e2(wt) ,其中 (p,t∈[1,n],p≠t)
- 先将每个单词转换为真值向量,即将 wi 表示为 wdi∈Tdw ,其中 dw 是向量的维度;
- 为了进一步捕获实体之间关系的信息,引入了WPE(word position embeddings),具体来说,就是将每个单词相对于两个实体的距离给保存下来,即将 wi 表示为 wMi=[(wdi)T,(wpi,1)T,(wpi,2)T]T ,其中 (wpi,1)T,(wpi,2)T 分别是 wi 关于实体 e1 和 e2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









