







作者:xg123321123
出处:http://blog.csdn.net/xg123321123/article/details/53218870
声明:版权所有,转载请联系作者并注明出处
1 问题定义
distant supervised 关系提取是一种从文本中提取关系事实的方法。
知识库是一种可以被用在问答系统和Web搜索中的三元组关系事实(e.g.,(Microsoft, founder, Bill Gates))的集合。
目前已有了一些大型知识库(knowledge base,KB),如freebase等,但这些远不能将大千世界的关系网络表示清楚。
所以需要更多的知识库。很多被用来构建知识库的方法都需要大量标注好的训练数据,这需要大量人力。
distant supervised关系提取则用来缓解这一尴尬局面。
distant supervised关系提取假设如果知识库中包含特定2个实体的某句话属于某种关系,那么所有包含这2个实体的句子都属于这种关系。
2 背景综述
- 对于偌大的知识库,难免会有一些错误的label,而distant supervised关系提取方法总是深受其害;
- 也有人尝试multi-instance学习来降低错误label的影响,但是由于这些方法都是用固有工具显式地提取特征,所以固有工具产生的错误会不断地传播;
- 大多数已有的深度学习方法需要句子级别的label,这使得深度学习在大规模知识库上的应用变得不太现实;
- 也有人尝试将multi-instance和深度学习结合起来实现distant supervised提取,然而这种方法在所有包含特定2个实体的句子中,只选取最有可能的一个来进行训练和预测,这就丢失了大部分信息。
3 灵感来源
- 运用attention机制来尽量减轻错误label的负面影响;
- 运用CNN将关系用sentence embedding的语义组合来表示,以此充分利用训练知识库的信息。
4 方法概述
- 给定句子集合 { x1,x2,...,xn} ,模型将会给出每种关系 r 的概率;
- 给定一个句子,使用CNN来构建其对应的向量;
- 然后使用句子级别的attention机制来选取对关系提取有影响的句子。
语句编码器
先将每个句子转化为稠密实数向量,然后利用卷积,池化和非线性转换等操作构建起对应的句向量,原理示意图如下。
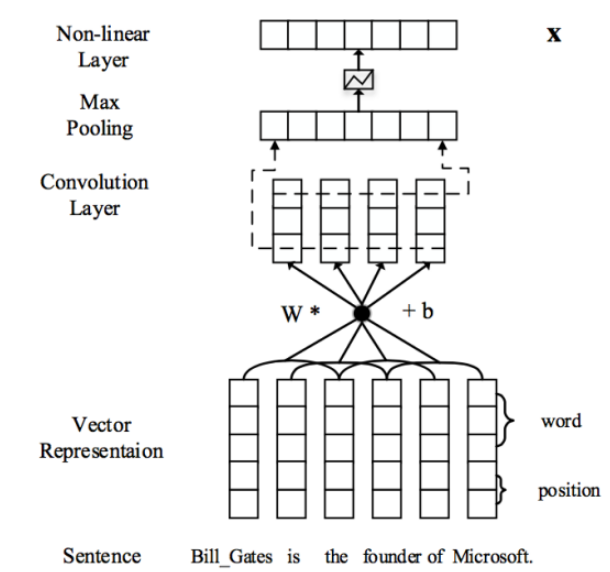
输入表示
- 输入为原始句子
x={w1,w2,...,wm} ; - 用word2vec将原始句子中的每个单词转换为实数向量;
- 用每个单词分别和2个实体的距离构造2个位置向量;
- 一个原始句子就被表示为了一个向量序列 w⃗ ={ w⃗ 1,w⃗ 2,...,w⃗ m} ,其中 wi∈Rd(d=da+db×2) , da 在文中取的3,而 db 取的1
卷积,池化和非线性操作
- 文本语句总是变长的,且对于最后关系分类比较重要的信息可能会出现句子的任何部分,所以需要将整个句子的信息都捕捉到;
- 本部分先对上面的向量序列 w⃗ ={ w⃗ 1
- 输入为原始句子
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









