









1、数据预处理的原因
现实世界中数据大体上都是不完整,不一致的脏数据,包含在数据库中的大部分原始数据也是不完整且含有噪声的,无法直接进行数据挖掘,或挖掘结果差强人意。为了提高数据挖掘的质量产生了数据预处理技术。数据预处理有多种方法:数据清理,数据集成,数据变换,数据归约等。这些数据处理技术在数据挖掘之前使用,大大提高了数据挖掘模式的质量,降低实际挖掘所需要的时间。
例如数据库可能包含:
- 过时或冗余字段
- 缺失值
- 离散值
- 其形式不适合数据挖掘模型的数据
- 与策略或常识不一致的值
2、数据预处理的方法
数据清理
数据清理过程通过填写缺失的值、光滑噪声数据、识别或删除离群点并解决不一致性来“清理”数据。主要是达到如下目标:格式标准化,异常数据清除,错误纠正,重复数据的清除。
a.处理缺失的方法:
1、直接省略缺失值的记录或字段 这种方法最简单直接,但极度危险,造成数据集失真。
2、根据不同标准使用替代值来替换缺失值
1)使用分析师制定的一些常量替换缺失值;
2)使用字段均值(对于数值型变量)或众数(对于分类变量)替换缺失字段值;
3)从观察到的变量分布中随机产生一个值替换缺失值;
4)根据记录的其他特性得出估算值以替换缺失值;
b.识别错误分类不一致性:
通过观察数据分布统计频率,确保数据有效且一致性
c.识别离群值的图形方法:
1)离散值是偏离了其他值的趋势的极端值,这可能代表数据输入错误,此外某些统计方法对离群值的存在是敏感的,即使离群值是有效的数据点不是错误,也可能产生不可靠的结果。
识别数值变量离群值的图形方法是校验变量的直方图,很明显的从图中观察对独立的一个或多个离群值,从而识别数据的有效性。
2)均值对于离群值的存在也极其敏感
标准的离散度度量包括极差(最大值-最小值)、标准偏差(SD)、平均绝对偏差和四分位差(IQR)。
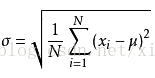
d、删除无用变量
删除对分析没有帮助的变量
e、删除重复记录
数据集成
数据集成例程将多个数据源中的数据结合起来并统一存储,建立数据仓库的过程实际上就是数据集成。
数据变换
通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。
1、规范化方法
1)min-max规范化:规范数据
2)z-score 标准化
步骤如下:
(1)求出各变量(指标)的算术平均值(数学期望)xi和标准差si ;
(2)进行标准化处理:
zij=(xij-xi)/si
其中:zij为标准化后的变量值;xij为实际变量值。
(3)将逆指标前的正负号对调。
标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
3)Decimal scaling小数定标标准化
数据归约
数据挖掘时往往数据量非常大,在少量数据上进行挖掘分析需要很长的时间,数据归约技术可以用来得到数据集的归约表示,它小得多,但仍然接近于保持原数据的完整性,并结果与归约前结果相同或几乎相同。















 8300
8300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











