







数据挖掘的任务:描述、评估、预测、分类、聚类、关联
数据:分类数据、顺序数据、数值数据
收集数据的五大调查方式:抽查、重点调查、普查、统计报表、典型调查
数据预处理:
原因:原始数据不完整且含有噪声(过时、冗余、缺失、离群、异常)
最主要目的:最小化无用数据输入和无用数据输出(GIGO)
处理缺失值:
1、常量替代
2、对于分类数据用众数替代,对于数值型数据用均值替代
3、从数据分布中随机产生一个值替代
4、估计缺失值
注:对于数值型数据 3比2好的一点是中心和散布的度量值与原始值更为接近
标准的4个离散度量:极差、标准差(SD)、平均绝对偏差、四分位差(IQR)
标准差:(最常见,但对离群值异常敏感,涉及极端值时考虑用平均绝对偏差,
或去除离群值后再用)
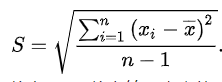
平均绝对偏差:
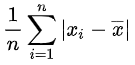
数据规范化:
1、min-max法:[ X-Xmin ] / [ Xmax-Xmin ] (0,1)之间
2、Z-score法:[ X-mean(X) ] / SD(X) (-x,x)之间 Z-score之后均值为0 标准差为1 但并非是正态分布 可能是左右倾斜数据 需要用Q-Q图(正态概率图)来进行检验数据是否为正态分布,就是画出不同分位数的占比,如果数据点散布在一条直线上则满足正态性,反之不满足。
数据右偏可以对数据取对数、取平方根、平方根倒数等变换使数据接近正态分布。因为这样变换后的导数是逐渐减小的,增速逐渐减慢可使数据向左移, 如果左偏的话可以取相反数转化为右偏数据。
3、小数规范化:X / 10^d ,其中d是数据位数 (-1,1)之间
判断数据倾斜度:
倾斜度 = 3*(均值-中位数)/ 标准差
若均值大于中位数 为 右倾数据 正倾斜
若均值小于中位数 为 左倾数据 负倾斜

处理离群值:
非参数方法:
1、校验数据的直方图即可
2、Z-score值小于-3或大于3判定为离群值(有SD所以对极端值敏感)
3、采用IQR法:IQR=Q3-Q1,Q3是数据75%分位数,Q1是数据25%分位数
(比SD衡量离散度更好)
小于【Q1-1.5*IQR】或大于【Q3+1.5*IQR】视为离群值
















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











