







 本文探讨了多种基于深度学习的手势识别方法,包括从2D RGB图像估计3D手部姿势、两流卷积网络在视频动作识别中的应用,以及使用递归神经网络进行动态手势识别。这些工作通过3D CNN、LSTM和其它深度结构,实现了对静态和动态手势的准确识别和实时处理。
本文探讨了多种基于深度学习的手势识别方法,包括从2D RGB图像估计3D手部姿势、两流卷积网络在视频动作识别中的应用,以及使用递归神经网络进行动态手势识别。这些工作通过3D CNN、LSTM和其它深度结构,实现了对静态和动态手势的准确识别和实时处理。
- Learning to Estimate 3D Hand Pose from Single RGB Images20173
- Two-Stream Convolutional Networks for Action Recognition in Videos2014
- Convolutional Two-Stream Network Fusion for Video Action Recognition2015
- Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks201611
- Realtime Multi-Person 2D Human Pose Estimation using Part Affinity Fields20166
- Convolutional Pose Machines2016
- Model-based Deep Hand Pose Estimation2016
- Multimodal Gesture Recognition Using 3D Convolution and Convolutional LSTM20173
- VideoLSTM Convolves Attends and Flows for Action Recognition20167
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition20146
- Gesture Recognition with a Convolutional Long Short-Term Memory Recurrent Neural Network2016
- Real time gesture recognition using Continuous Time Recurrent Neural Networks
《Learning to Estimate 3D Hand Pose from Single RGB Images》2017.3
本文介绍了从2D彩色图像进行3D hand pose estimation的一种方法,总体来说方法很直观
project page
主要流程
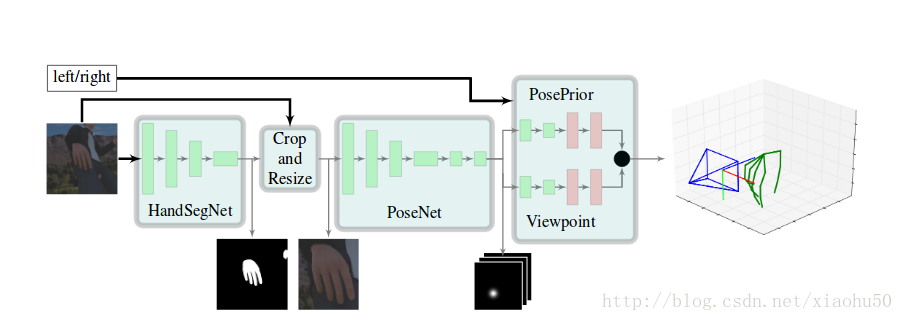
如图所示,依次有以下几个环节:
- 1)HandSegNet, 输入256x256x3, 输出256x256x1的一个hand mask。用一个FCN网络进行手的语义分割,分割之后的结果用来对手附近区域进行截图,以减少计算量及提高准确性
- 2)PoseNet,用来计算手的21个keypoint, 输入256x256x3,输出32x32x21, 即21张不同keypoint的score map
- 3)PosePrior,有两个子stream,每个的网络结构除了最后一层不一样其他都一样,输入32x32x21,输出两个层。一个是正则化的手的坐标,以手掌的点为原点,且长度进行了normalize, 即维度为21x3。另一个是相对于实际图片的空间的变换关系,即维度为3
在论文中还用这个结构进行了手语识别,手语识别的网络直接根据手的指示来, 是一个3层的全连接网络,输入维度63, 输出维度35
代码细节解读
使用自带的工具tfprof进行性能分析,发现主要的耗时在于, 2/3耗时在single_obj_scoremap中的tf.nn.dilation2d操作, 1/6耗时在HandSegNet,1/6耗时在PoseNet2D。
同时,为了复用前人训练好的网络参数,将手部截图重新上采样到256x256来使用PoseNet。可见整个网络还有很大的优化空间。cpu上做到实时也不是没有希望。
训练流程解读
《Two-Stream Convolutional Networks for Action Recognition in Videos》2014
框架
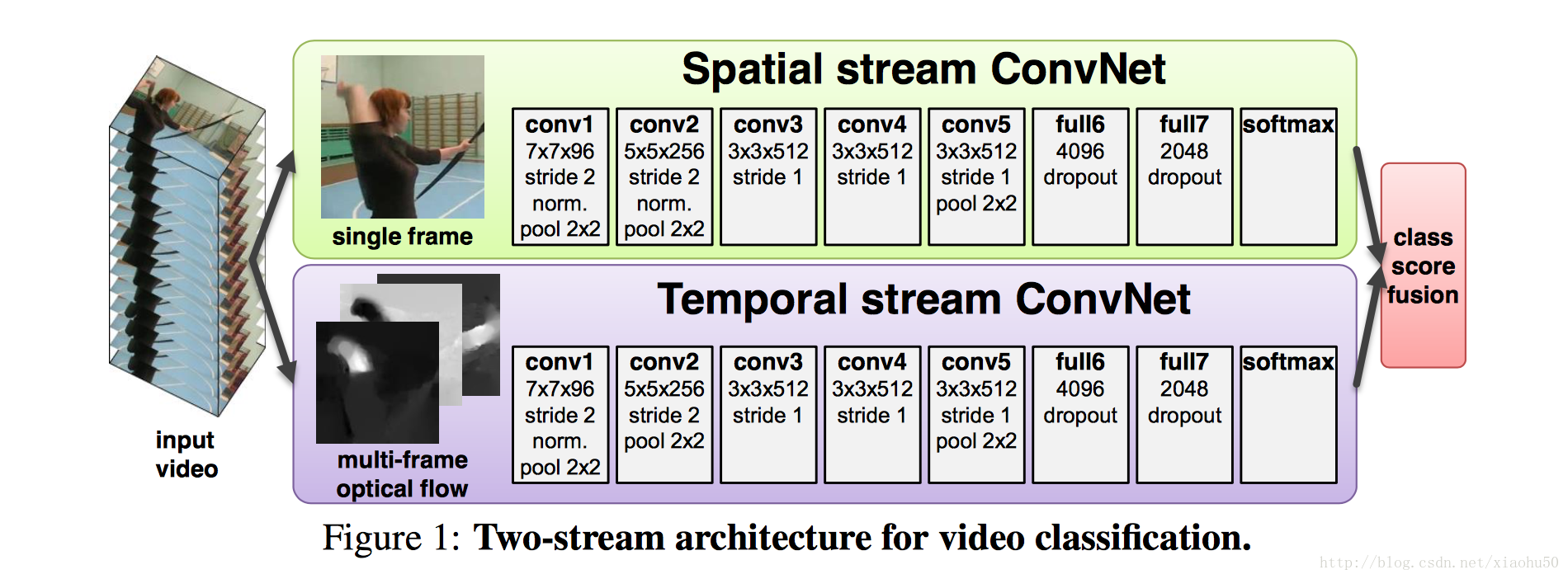
如上图所示,采用两个stream,一个用静态的单张图片来分类,另一个stream用累积的多张图片的信息来分类
两个stream
Spatial stream ConvNet
非常直观,直接用每张图片过cnn
Optical flow ConvNets
文中提到了两种方法,一种是光流Optical flow stacking,一种是轨迹Trajectory stacking
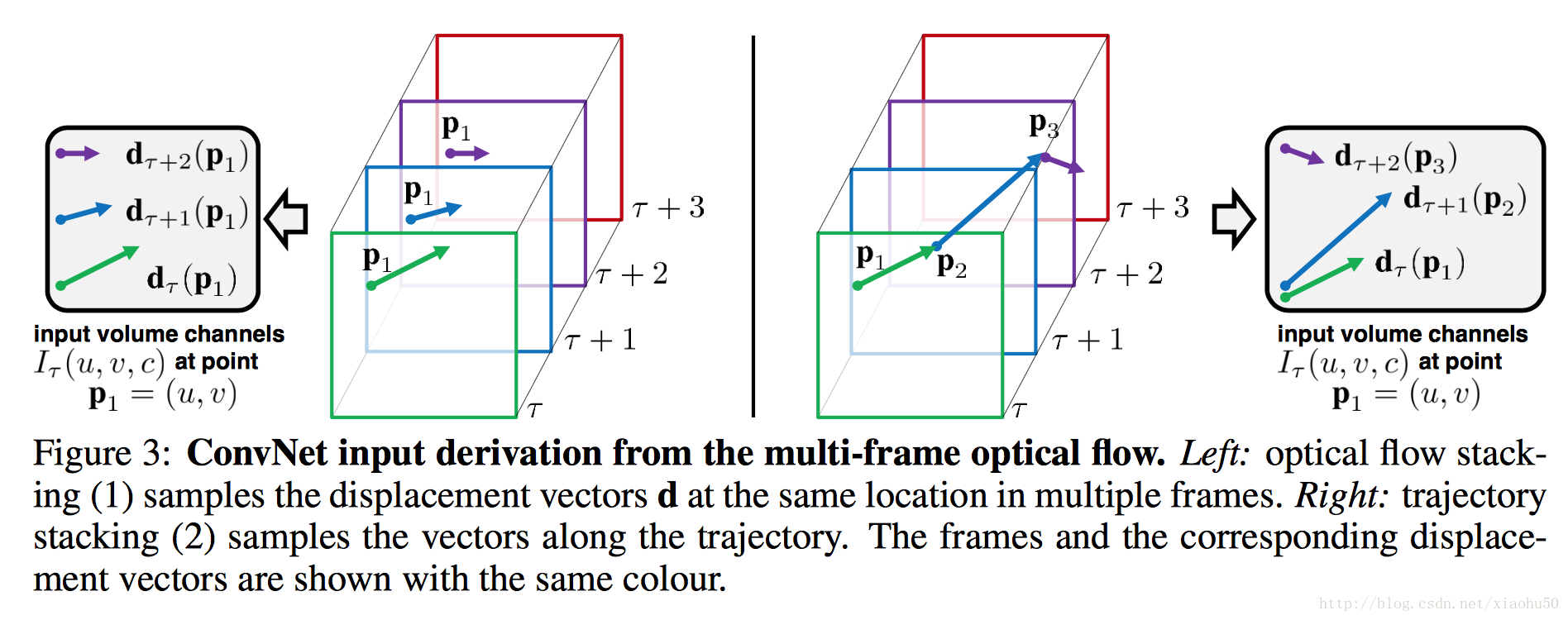
- 光流采用x,y两个方向的光流,顾如果stack一共L张图片的信息,则有2L张的光流图
- 轨迹也分x,y的两张图,但是区别是轨迹追踪的是同个点在不同帧上的位移,个人感觉没啥区别,对框架没有影响。
文中还讨论了一些方便用在学习中的特征,可以参考一下
train要点
- 对于Spatial stream ConvNet, 可以在imageNet等大数据集上进行训练
- 对于Optical flow ConvNets, 需要在video数据集上训练,文中用了UCF-101 ,HMDB-51这两个,如果你直接采用着两个数据集,需要手工去重,防止某些动作特别多照成过拟合, 文中提到了multi-task learning这种方法。参考《A unified architecture for natural language processing: deep neural networks with multitask learning》
《Convolutional Two-Stream Network Fusion for Video Action Recognition》2015
code
这篇文章主要是在《Two-Stream Convolutional Networks for Action Recognition in Videos》的基础上进行改进。主要针对其中的两个缺点:
* spatial 和 temporal 的feature没有在pixel层面上进行合作,只用了最后的score
* temporal的操作基本还是基于2d的conv
核心在于引入3d-conv , 3d-pooling,以及对网络结构进行fusion
框架
TODO
《Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks》2016.11
这篇文章的思路就不一样,它主要在于训练一个end-to-end的手势识别结果,不进行具体的hand pose estimation。从视频效果来看也不错
大道至简,对于近距离的手势识别,觉得这个方案应该是目前比较靠谱的。
project page
框架
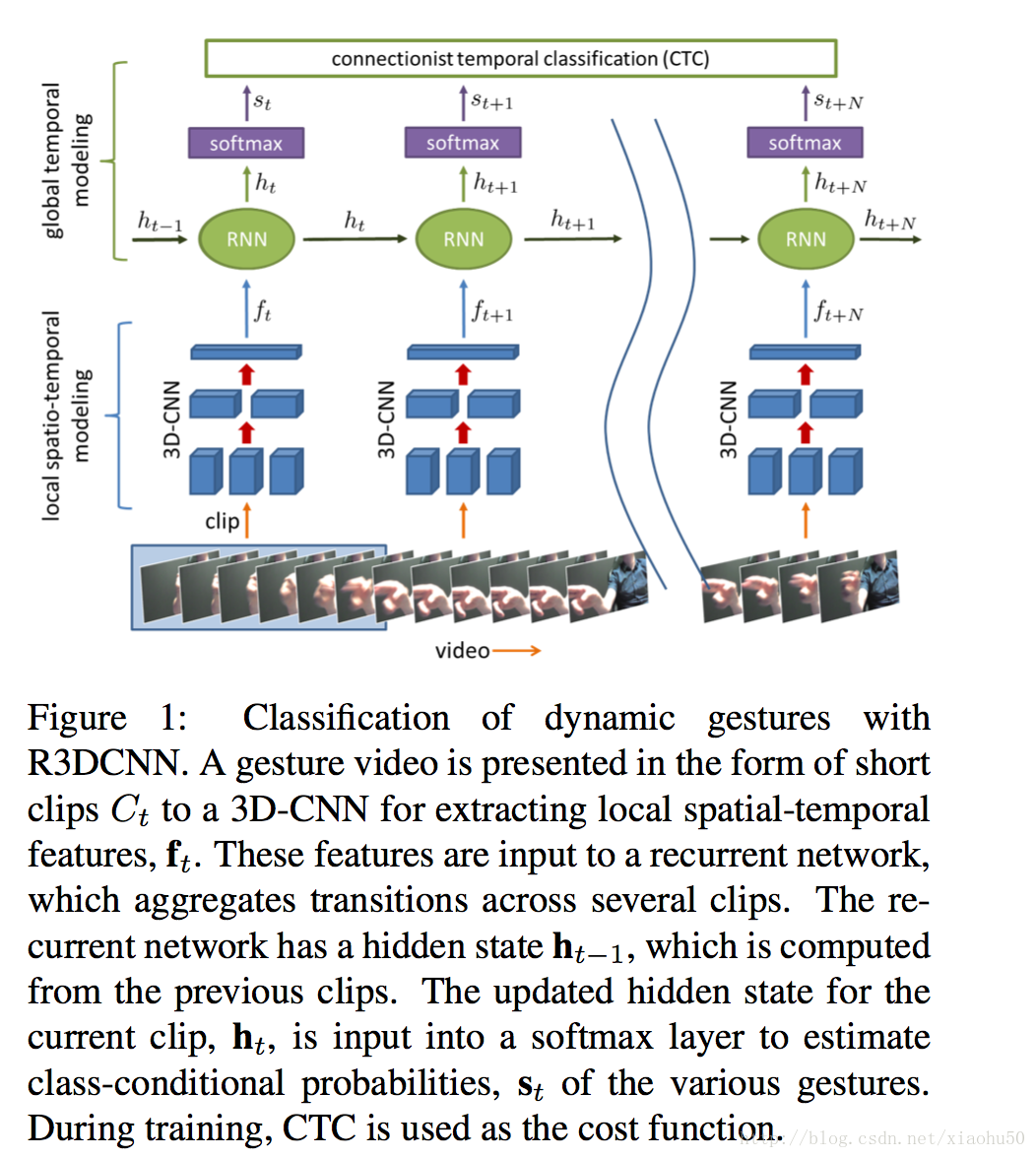
如上图所示基本框架很简单
3D-CNN + RNN + Softmax + CTC loss
文中采用了多模态数据,比如RGB,深度,红外,光流,但本身基于单数据源也效果很好
细节
数据源
在 project page上,有他们自制的训练数据,大概30G,包含25个预定义动作,20个训练人员,10秒不到的短视频,每个视频一个动作,视频中包含无动作开始+动作+无动作结尾。除此之外,在训练过程中还做了data augment,比如从120x160的尺寸中随机取112x112大小的数据,还有random spatial rotation (±15◦) and scal- ing (±20%), temporal scaling (±20%), and jittering (±3 frames).
3D-CNN
经过测试他们选取了一个clip 8帧来兼顾性能和速度,3D-CNN使用pretrain自C3D的一个比较大的运动数据集。然后在pretrain的weights的基础上直接加softmax算cross entropy的loss来fine tune 3D-CNN的参数。
用了8层conv和2层的全连接。
RNN
在准备好3D-CNN之后,加上RNN&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









