







一、概述
我们知道Hadoop提供了一个中央化的存储系统,有利于进行集中式的数据分析与数据共享,而且Hadoop对存储格式没有要求,比如可以存储用户访问日志、产品信息、网页数据等。但是如何将数据存入Hadoop中呢?这就需要相应的数据收集系统。
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume具有如下几个特点:
(1) 可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:
end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),
Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),
Best effort(数据发送到接收方后,不会进行确认)。
(2) 可扩展性
Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
(3) 可管理性
所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
(4) 功能可扩展性
用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
二、Flume基本架构
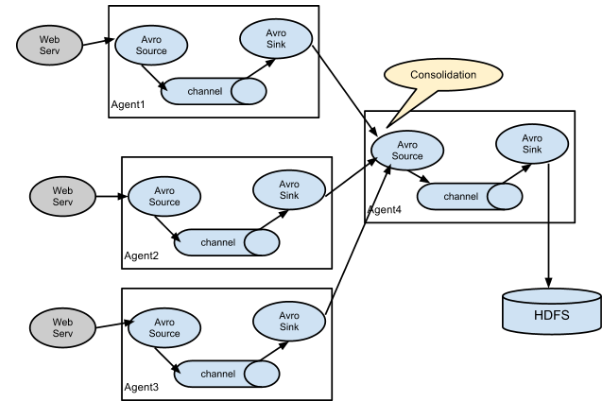
Flume的基本架构图如下:

图上有三个Flume的重要角色:

1、Mater
Master的主要作用如下:
- 管理协调 agent 和collector的配置信息;
- Flume集群的控制器;
- 跟踪数据流的最后确认信息,并通知agent;
- 通常需配置多个master以防止单点故障;
- 借助zookeeper管理管理多Master。
2、Agent
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。Flume传输的数据的基本单位是Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、sink。通过这些组件,Event可以从一个地方流向另一个地方。Event 从 Source 流向 Channel,再到 Sink,本身为一个byte数组,并可携带headers信息。Event代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。一个flume系统可以由一个或多个agent组成,多个agent只要做一些简单的配置就可以串在一起,比如将两个agent(foo、bar)串在一起工作,只要将bar的source(入口)接在foo的sink(出口)上就可以了。
- Source
专用于收集日志,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义等。
Exec Source:以运行 Linux 命令的方式,持续的输出最新的数据,如 tail -F 文件名 指令,在这种方式下,取的文件名必须是指定的。 ExecSource 可以实现对日志的实时收集,但是存在Flume不运行或者指令执行出错时,将无法收集到日志数据,无法保证日志数据的完整性;
Spool Source:监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到 spool 目录下的文件不可以再打开编辑;spool 目录下不可包含相应的子目录。
- Channel
专用于临时存储数据,可以存放在memory、jdbc、file、自定义等。其存储的数据只有在sink发送成功之后才会被删除。
Memory Channel:可以实现高速的吞吐,但是无法保证数据的完整性。Memory Channel 是一个不稳定的隧道,其原因是由于它在内存中存储所有事件。如果 java 进程死掉,任何存储在内存的事件将会丢失。另外,内存的空间也受到RAM大小的限制,与File Channel有差别;
File Channel:保证数据的完整性与一致性。在具体配置FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。File Channel是一个持久化的隧道(channel),它持久化所有的事件,并将其存储到磁盘中。因此,即使 Java 虚拟机当掉,或者操作系统崩溃或重启,再或者事件没有在管道中成功地传递到下一个代理(agent),这一切都不会造成数据丢失。
- Sink
专用于把数据发送到目的地件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义等。
3、collector
collector的作用是将多个agent的数据汇总后,将汇总结果导入后端存储系统,比如HDFS,HBase。
4、可靠性
Flume使用事务性的方式保证传送Event整个过程的可靠性。Sink必须在Event被存入Channel 后,或者已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把Event从Channel中remove掉。这样数据流里的event无论是在一个agent里还是多个agent之间流转,都能保证可靠,因为以上的事务保证了event会被成功存储起来。而Channel的多种实现在可恢复性上有不同的保证。也保证了event不同程度的可靠性。比如Flume支持在本地保存一份文件channel作为备份,而memory channel将event存在内存queue里,速度快,但丢失的话无法恢复。
三、Flume常见拓扑架构
1、拓扑一
如图:
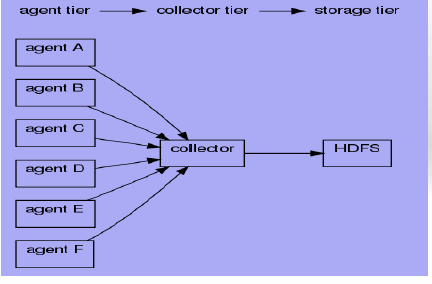
该拓扑将A-F所在的机器的系统日志收集到HDFS中,在flume 中配置如下:
agentA : tail(“/ngnix/logs”) | agentSink("collector",35853); agentB : tail(“/ngnix/logs”) | agentSink("collector",35853); agentC : tail(“/ngnix/logs”) | agentSink("collector",35853); agentD : tail(“/ngnix/logs”) | agentSink("collector",35853); agentE : tail(“/ngnix/logs”) | agentSink("collector",35853); agentF : tail(“/ngnix/logs”) | agentSink("collector",35853); collector : collectorSource(35853) | collectorSink("hdfs://namenode/flume/","srcdata");该配置较为简单,可靠性较低。
2、拓扑二
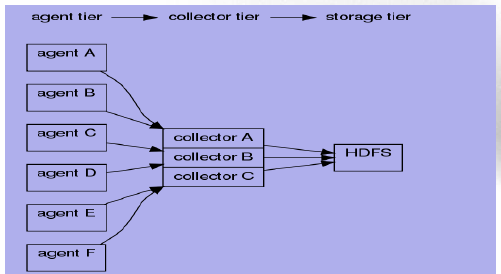
相应的配置如下:
agentA : src | agentE2ESink("collectorA",35853);
agentB : src | agentE2ESink("collectorA",35853);
agentC : src | agentE2ESink("collectorB",35853);
agentD : src | agentE2ESink("collectorB",35853);
agentE : src | agentE2ESink("collectorC",35853);
agentF : src | agentE2ESink("collectorC",35853); collectorA : collectorSource(35853) | collectorSink("hdfs://...","src"); collectorB : collectorSource(35853) | collectorSink("hdfs://...","src"); collectorC : collectorSource(35853) | collectorSink("hdfs://...","src");注:上述配置中的src均为具体目录。
3、拓扑三
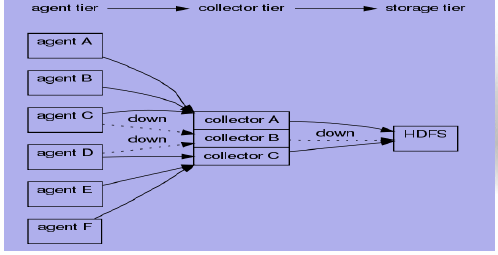
相应配置如下:
agentA : src | agentE2EChain("collectorA:35853","collectorB:35853");
agentB : src | agentE2EChain("collectorA:35853","collectorC:35853");
agentC : src | agentE2EChain("collectorB:35853","collectorA:35853");
agentD : src | agentE2EChain("collectorB:35853","collectorC:35853");
agentE : src | agentE2EChain("collectorC:35853","collectorA:35853");
agentF : src | agentE2EChain("collectorC:35853","collectorB:35853"); collectorA : collectorSource(35853) | collectorSink("hdfs://...","src"); collectorB : collectorSource(35853) | collectorSink("hdfs://...","src"); collectorC : collectorSource(35853) | collectorSink("hdfs://...","src");上述配置保证了当一个Collector Chain挂掉时可以启用备用的Collector。
四、Flume基本配置和使用
1、配置文件
vi /usr/local/flume/conf/flume-conf.properties
#agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/local/logs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/local/logs_tmp_cp
agent1.channels.channel1.dataDirs=/usr/local/logs_tmp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://sparkproject1:9000/logs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d2、创建所需文件夹
本地文件夹:mkdir /usr/local/logs
HDFS文件夹:hdfs dfs -mkdir /logs
3、启动Flume
使用如下命令:
flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console启动后Flume开始监听。

4、测试
另外启动一个终端,将测试文件放入/usr/local/logs目录下,Flume将自动将该文件上传到HDFS的/logs目录中。
上传前HDFS目录/logs为空:

创建一个测试文件data.txt,将其放入/usr/local/logs中。

观察Flume的终端可与看到如下提示:

最后查看HDFS中的目录:
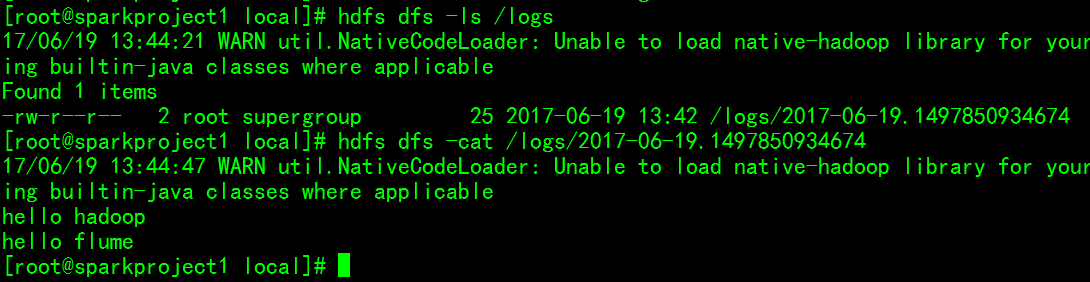
可以看到,Flume已经完成了数据自动上传。

















 7463
7463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









