Q&A:
1.为什么有段时间显示糗事百科不可用?
答:前段时间因为糗事百科添加了Header的检验,导致无法爬取,需要在代码中模拟Header。现在代码已经作了修改,可以正常使用。
2.为什么需要单独新建个线程?
答:基本流程是这样的:爬虫在后台新起一个线程,一直爬取两页的糗事百科,如果剩余不足两页,则再爬一页。用户按下回车只是从库存中获取最新的内容,而不是上网获取,所以浏览更顺畅。也可以把加载放在主线程,不过这样会导致爬取过程中等待时间过长的问题。
项目内容:
用Python写的糗事百科的网络爬虫。
使用方法:
新建一个Bug.py文件,然后将代码复制到里面后,双击运行。
程序功能:
在命令提示行中浏览糗事百科。
原理解释:
首先,先浏览一下糗事百科的主页:http://www.qiushibaike.com/hot/page/1
可以看出来,链接中page/后面的数字就是对应的页码,记住这一点为以后的编写做准备。
然后,右击查看页面源码:

观察发现,每一个段子都用div标记,其中class必为content,title是发帖时间,我们只需要用正则表达式将其“扣”出来就可以了。
明白了原理之后,剩下的就是正则表达式的内容了,可以参照这篇博文:
http://blog.csdn.net/wxg694175346/article/details/8929576
运行效果:
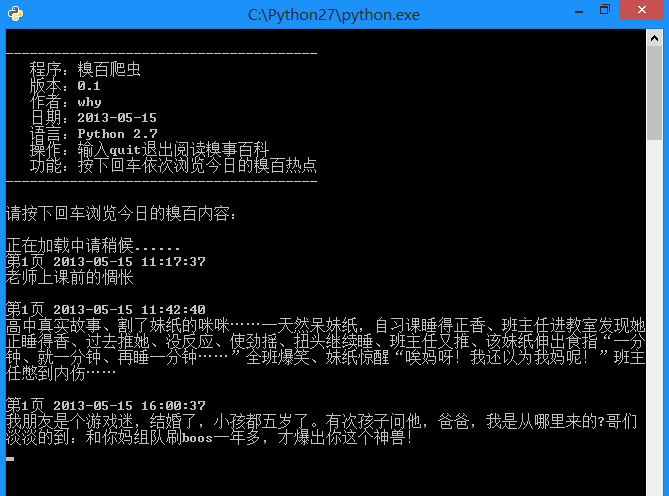
-
-
- import urllib2
- import urllib
- import re
- import thread
- import time
-
-
-
- class Spider_Model:
-
- def __init__(self):
- self.page = 1
- self.pages = []
- self.enable = False
-
-
- def GetPage(self,page):
- myUrl = "http://m.qiushibaike.com/hot/page/" + page
- user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
- headers = { 'User-Agent' : user_agent }
- req = urllib2.Request(myUrl, headers = headers)
- myResponse = urllib2.urlopen(req)
- myPage = myResponse.read()
-
-
- unicodePage = myPage.decode("utf-8")
-
-
-
- myItems = re.findall('<div.*?class="content".*?title="(.*?)">(.*?)</div>',unicodePage,re.S)
- items = []
- for item in myItems:
-
-
- items.append([item[0].replace("\n",""),item[1].replace("\n","")])
- return items
-
-
- def LoadPage(self):
-
- while self.enable:
-
- if len(self.pages) < 2:
- try:
-
- myPage = self.GetPage(str(self.page))
- self.page += 1
- self.pages.append(myPage)
- except:
- print '无法链接糗事百科!'
- else:
- time.sleep(1)
-
- def ShowPage(self,nowPage,page):
- for items in nowPage:
- print u'第%d页' % page , items[0] , items[1]
- myInput = raw_input()
- if myInput == "quit":
- self.enable = False
- break
-
- def Start(self):
- self.enable = True
- page = self.page
-
- print u'正在加载中请稍候......'
-
-
- thread.start_new_thread(self.LoadPage,())
-
-
- while self.enable:
-
- if self.pages:
- nowPage = self.pages[0]
- del self.pages[0]
- self.ShowPage(nowPage,page)
- page += 1
-
-
-
- print u
-
-
-
-
-
-
-
-
-
-
-
-
- print u'请按下回车浏览今日的糗百内容:'
- raw_input(' ')
- myModel = Spider_Model()
- myModel.Start()






















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









