






涉及到的一些方法,具体关系如下:

本文主要讲对比学习在18年至今的一个发展历程,主要分为四个阶段:
1、百花齐放(当前的阶段方法,模型,目标函数还没有统一,代理任务也没有统一,所以是一个百花齐放)
InstDisc(cvpr18)

受到有监督的启发:
- 把每一个个体当作一个类别,学一种特征将每一张图片都区分开,进而引入个体判别这一代理任务。
- 通过CNN将图片编码成一个特征,希望编码后的图片在最后的空间里面,相似的样本更近,不相似的更远一点,意味着每个图片的维度不能太高,不然代价就比较大。
大量的负样本信息存放在Memory Bank中,对于Imagenet来说有128w个图片,意味着要存储128w行。正样本就是数据增强后的,负样本就是在Memory Bank中选择4096,batch_size = 256
- 大量负样本都存在 Memory Bank(ImageNet 中为 128w),因此特征数不能过高(128 维)
一个batch_size 学习到的特征,更换掉Memory Bank中的特征。
- 每次一个正样本,对应采样的 4096 个负样本,使用 NCE loss 计算损失;随后将这个 mini-batch 中样本的新表示,拿去更新 Memory Bank 中的结果
正样本就是通过当前样本的数据增强,负样本就是其它图片。
- 正样本即图片本身(可能数据增强),负样本即其它所有图片
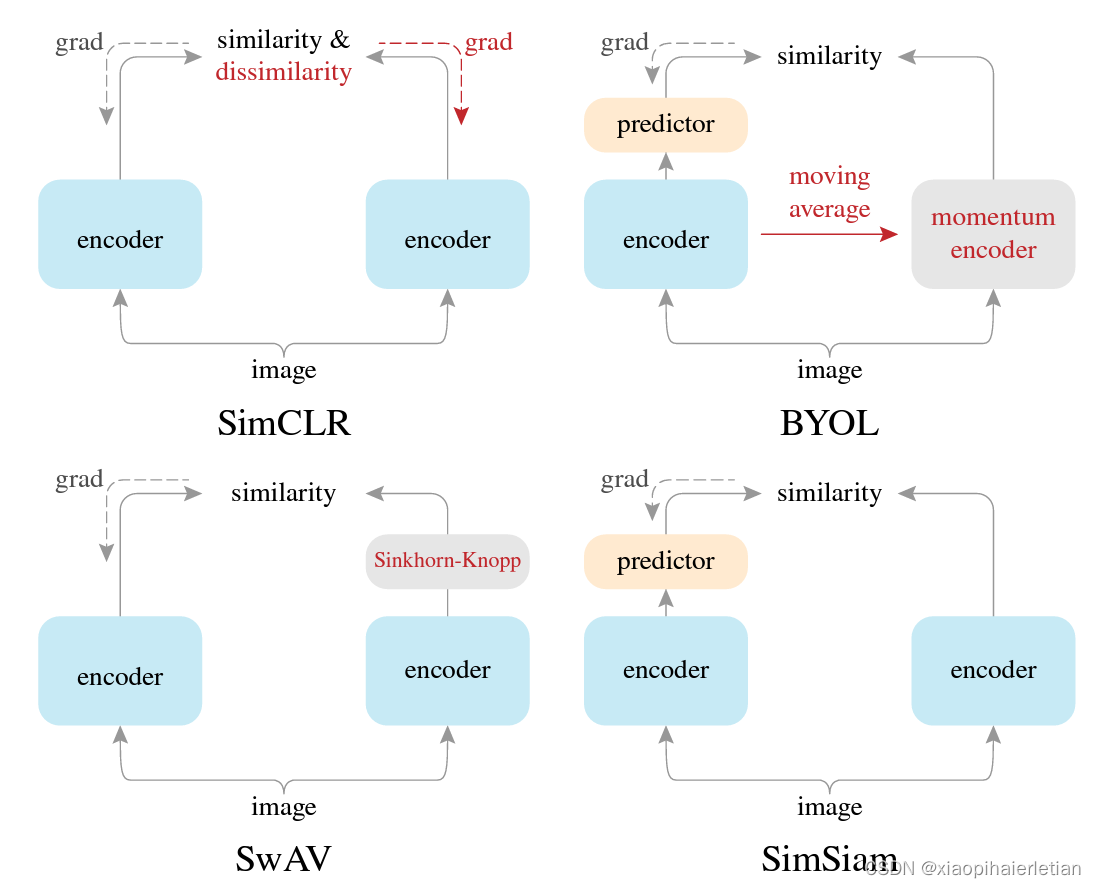
InvaSpread(端到端的学习,仅仅需要一个编码器,不需要额外的数据结构进行存储负样本)
SimCLR的前身,没有使用额外的数据结构去存储大量的负样本。它的正负样本就是来自于同一个minibatch。使用一个编码器进行端到端的学习。
相同的图片,编码后应该类似(Invariant 不变性),不同的图片编码后不类似(Spreading 分散开)
为什么没有取得那么好的结果呢,这就是MoCo论文中讲到的字典必须足够大,也就是在做对比学习的时候,负样本最好足够多。
batch_size = 256 经过数据增强,又得到了256张图片。负样本就是剩下的所有的图片(原始的图片以及增强后的图片)。正样本:256,负样本:(256 - 1) * 2


- cpc(可以处理音频,文字以及在强化学习中使用),利用预测做代理任务 -
- 一个编码器 + 自回归模型
- 用预测的代理任务来做对比学习,提出 InfoNCE Loss
自回归模型,序列模型。利用前面的输入来预测后面的序列。样本中后面的序列作为一个正样本,非后面的的序列作为一个负样本,进行一个对比学习。

Contrastive Multiview Coding/CMC(一个物体有多个视角,都可以被当作一个正样本,每个视角有可能带有噪声或者不完整。但是重要的信息在所有视角中共享)

- 同一张图片的多个模态为正样本,其余为负样本。
- 不同模态使用不同的编码器
- 证明了对比学习的灵活性
思想:主要就是学习视角不变性,抓住所有视角中的关键因素。学习到的是公共的,并非细节,做一些大概的分类任务问题不大。
- 一个图像的不同视角作为一个正样本,其它图片的不同视角作为负样本。
- 证明了对比学习的灵活性,证明了多视角,多模态的可行性,以及可以应用到不同得领域。所以就出现了clip的模型(OpenAI),输入一张图片、一段文本,来做多模态的对比学习。
- 如果使用知识蒸馏,可以将教师、学生的模型的输出作为正样本。
- 但是也有一定得局限性,多模态可能需要不同的编码器,计算成本就比较大。一般对比学习,正负样本编码器一致。对于多模态数据,可以使用transformer一个编码器。比如clip输入图片,文本使用两个编码器(Vit,Transformer)。对于ma clip仅仅使用一个transformer对多模态数据进行处理,反而效果更好。证明了transformer的强大之处。
2、CV双雄(这个阶段发展非常迅速,有些间隔不到一个月就有一篇好的论文,imagenet不断被刷新)这段时期主要是「MoCo 系列模型」与「SimCLR 系列模型」在轮番较量。
MoCo

利用队列,以及动量编码器形成一个又大有一致的字典,能够进行更好的对比学习。利用一个队列替换掉了InstDisc中的Memory Bank。利用数据结构去存储负样本。
利用动量编码器来取代了loss中的约束项,从而达到动量的更新编码器的目的,而不是更新那个特征。
改进简单有效。
- 队列(取代 Memory Bank)与动量编码器(动量地更新编码器,而不是更新特征)
- 使用 InfoNCE 作为目标函数,并第一次使用无监督方法比有监督表现地更好
- Insight
- 负样本最好足够多,即字典足够多
- 负样本来自的编码器,尽量保持一致,即字典中的特征应保持一致
SimCLR
正负样本和InvaSpread一样,共享一个编码器。
发现了对比学习需要很强的数据增强技术。他们设置了更大的batch_size。训练的时间更久,加了一个可学习的g线性函数
它的数据增强技术,最后一层加MLP,对后续的工作有重大的影响.
图片数据增强:原始图片,裁剪,改变色彩,旋转,cutout(将图片中某一个区域去掉),使用高斯噪声以及高斯blur,使用Sobel filtering。
最有效的数据增强就是随机裁剪以及随机的色彩变幻。其它的都是锦上添花
重大创新点就是加了一个projection(一个MLP),可以在ImageNet上提升10个点。
zi就是要做对比学习的特征。这个g函数只是在做训练的时候使用,做下游任务的时候,直接丢掉
使用非线性层会提十几个点。对比学习中最后一层维度没有太大的影响,一般是128.


MoCo V2
- 将 SimCLR 中的 g 和数据增广,借鉴到了 MoCo 中
- MLP、aug+、cosine learning rate schedule、more epochs
做了一些改进。加了一个MLP层,加了更多的数据增强,训练的时候利用了cosine learning rate schedule,更大的epochs。
相对更低的配置,更少的时间就可以完成。


SimCLR v2(非常大的自监督训练出来的模型非常适合做半监督学习)
- 用更大的模型,无监督对比学习效果更好
- 将之前一层的 MLP (fc+relu) 换成两层的 MLP,即加深了 projection head
- 使用动量编码器
第一步利用自监督训练一个比较大的模型,第二步,一旦有了这么好的模型,仅仅需要一部分有标签的数据去做有监督的微调,微调结束,就有一个teacher模型,利用teacher模型去生成很多伪标签,
改进:1、加深模型,编程大模型。2、projection head 加深,一层很有用,尝试多加几层,实验发现两层就够了(FC + RELU + FC + RELU)。3、使用动量编码器,但是提升一两个点,原因就是这个已经用了很大的mini-batch了。

SwAV(给定一张同样的图片,有不同的视角,我希望用一个视角去预测另外一个视角得到的特征,因为所有的特征按道理来说是比较接近的,做法就是把对比学习和聚类的方法结合起来)。聚类算法:DeepCluster v1,v2
- 拿到负样本聚类得到的矩阵,将其作为映射矩阵 C,随后代理任务为,两个正样本 z1、z2,经过映射矩阵 C 得到的 Q1、Q2,应尽可能相似
- trick:数据增广时,采用多尺度去裁剪图片 (multi crop)
不去和大量的负样本比,和聚类的中心点比。聚类的中心就是一个矩阵(d x k),
crop,很有用


3、 不用负样本(不用负样本,也可以做对比学习)
BYOL(我自己和自己学)
- Model collapse: 即一旦只有正样本,模型会学到 trival solution,即所有输入都对应相同输出
- 编码器 1 为希望学到的编码器,编码器 2 为动量编码器,两个正样本经过编码器 1、2 分别得到 z1、z2,随后 z1 再过一层 MLP 得到 q1,此时用 q1 来预测 z2 进而来更新网络(使用 MSE Loss)。最后在下游任务上,使用编码器 1 进行特征表示
- BYOL 为什么不会坍塌:如果去除 BYOL 中 MLP 里的 BN,学习就会坍塌,但加上就不会
- 一种解释角度:BN 即使用 minibatch 的均值和方差,因此 BN 会导致数据泄露,即 BYOL 实际上是和 “平均图片” 去比,可以认为是一种隐式的负样本
- BYOL 后续进一步回应(大量消融实验):BN 能够使模型训练更加稳定,就算不用 BN,换成 Group Normalization 或者比较好的初始化,BYOL 依然可以学得比较好
一般会加负样本,防止模型学捷径。造成model collapse,learning collapse(模型坍塌,学习坍塌)
该模型的成绩就是不用负样本,效果照样好
t t‘ 数据增强的结果。f1,f2使用同样的网络架构,但是他们的参数是不同的。f1随着梯度更新而更新的。f2使用动量编码器。接下来使用projection。 然后q1在进入一个prodiction,输出结果预测sg。将匹配任务转化为了预测任务。 训练完之后只有f1留校,其它的都不要。
projection以及prediction中都有batch Norm
batch norm是在当前的batch中计算方差以及均值,利用均值和方差去做归一化,就意味着在算某个正样本的loss时,其实也看到了其它样本的这个特征,也就是这里面是有信息泄露的,因为有这种信息泄露,就可以把这种负样本看作隐式的负样本。BYOL回应batch notm现象


SimSiam(把整个过程化繁为简)
- 特点:不需要负样本、大 batch size、动量编码器
- 方法:将 BYOL 中的动量编码器变成了一个可以更新的编码器
- 解释:stop gradient 使得模型的更新交替进行,类似 EM 的思想
我们既不需要负样本,不需要大的batch_size,不需要动量编码器
# 4、Transformer(Vit)
MoCo V3()
在 MoCo v2 基础上,引入了 SimSiam 中 predictor 以及两边一起更新的 EM 思想,并将 backbone 从 ResNet 换成了 Vision Transformer
出现的问题:大 batch size 时,训练波动很大,导致最终结果也不太好
解决方式:在训练时,冻住 patch projection layer,即使用 random patch projection layer

DINO
- 整体与 MoCo v3 非常像,主要不同在于算 loss 时,用了一下 centering 的 trick
参考资料
原文链接:对比学习 (Contrastive Learning) 发展历程 - 综述_对比学习损失发展脉络-CSDN博客














 38
38











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









