







 本文介绍了机器学习模型调优的实战方法,包括使用pipeline简化预处理步骤,通过holdout和k-fold交叉验证评估模型性能,学习曲线和验证曲线的分析,以及使用网格搜索调优。同时讲解了precision、recall和F1-score等性能指标,以及ROC曲线的绘制和理解。
本文介绍了机器学习模型调优的实战方法,包括使用pipeline简化预处理步骤,通过holdout和k-fold交叉验证评估模型性能,学习曲线和验证曲线的分析,以及使用网格搜索调优。同时讲解了precision、recall和F1-score等性能指标,以及ROC曲线的绘制和理解。
引言
如果你对机器学习算法已经很熟悉了,但是有时候你的模型并没有很好的预测效果或者你想要追求更好地模型性能。那么这篇文章会告诉你一些最实用的技术诊断你的模型出了什么样的问题,并用什么的方法来解决出现的问题,并通过一些有效的方法可以让你的模型具有更好地性能。
介绍数据集
这个数据集有569个样本,它的前两列为唯一的ID号和诊断结果 (M = malignant, B = benign) ,它的3->32列为实数值特征,我不是医学专家,我不太明白具体特征的是什么意思,都是关于细胞的,但是,机器学习的伟大之处就在于这点,即使我们不是一个这方面的专家,我们依然可以读懂这些数据,掌握数据中的模式,从而我们也可以像一个专家一样做出预测。
下面的链接有数据集更详细的介绍,有兴趣的朋友可以看看。
http://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
初识pipeline
在训练机器学习算法的过程中,我们用到了不同的数据预处理技术,比如:标准化,PCA等。在scikit-learn中,我们可以用pipeline这个非常方便的类帮我们简化这些过程。这个类帮我们用任意次的转换步骤来拟合模型并预测新的数据。下面,我用具体代码来演示这个类的好处:
import pandas as pd
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data', header=None) # 读取数据集
from sklearn.preprocessing import LabelEncoder
X = df.loc[:, 2:].values # 抽取训练集特征
y = df.loc[:, 1].values # 抽取训练集标签
le = LabelEncoder()
y = le.fit_transform(y) # 把字符串标签转换为整数,恶性-1,良性-0
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1) # 拆分成训练集(80%)和测试集(20%)
# 下面,我要用逻辑回归拟合模型,并用标准化和PCA(30维->2维)对数据预处理,用Pipeline类把这些过程链接在一起
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# 用StandardScaler和PCA作为转换器,LogisticRegression作为评估器
estimators = [('scl', StandardScaler()), ('pca', PCA(n_components=2)), ('clf', LogisticRegression(random_state=1))]
# Pipeline类接收一个包含元组的列表作为参数,每个元组的第一个值为任意的字符串标识符,比如:我们可以通过pipe_lr.named_steps['pca']来访问PCA组件;第二个值为scikit-learn的转换器或评估器
pipe_lr = Pipeline(estimators)
pipe_lr.fit(X_train, y_train)
print(pipe_lr.score(X_test, y_test))当我们调用Pipeline的fit方法时,StandardScaler调用fit和transform方法来将数据标准化,接着标准化后的数据被传到PCA中,PCA也执行fit和transform方法对标准化后的数据进行降维,最后把降维的数据用逻辑回归模型拟合,当然了,这只是我的一个演示,你可以把任意多的转换步骤放到Pipeline中。而且,它的另一个优点是,当我们评估测试集的时候,它也会用上面转换过程保留的参数来转换测试集。这一切是不是很Cool?Pipeline就像一个工厂流水线一样,把所有的步骤链接到了一起,具体的细节完全不用我们自己操心。整个流程可以用下面的图形概括。
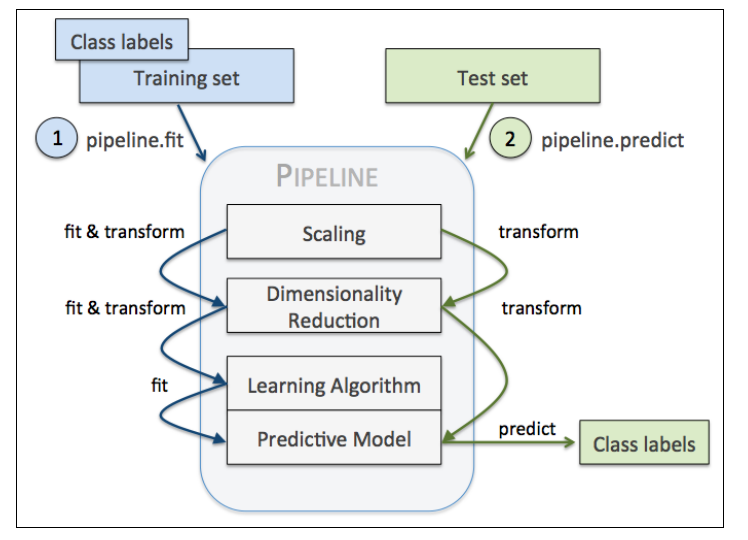
用holdout和k-fold交叉验证评估模型性能
holdout交叉验证
在我们上面的那个例子中,我们只把数据集分成了训练集和测试集。然而在实际的机器学习应用中,我们会选择最优的模型和最优的学习参数来提高我们算法对未见到的数据预测的性能。然而,如果我们在模型选择或调节参数的过程中,一遍又一遍地用我们的测试集,那么它也变成了我们测试集的一部分了,很有可能这样的参数和模型只适应当前的测试集,而对没有见过的数据集它的性能很不好,也就是发生了过拟合现象。
因此,一个更好地方式是把我们的数据集分成三个部分:把上面例子中的训练集分成训练集和交叉验证集,测试集。现在,我们构建机器学习的系统步骤应该是:
- 选择模型和参数,用训练集去拟合
- 把拟合后的模型和参数应用到交叉验证集来评估其性能
- 不断地重复1,2两个过程,直到挑选出我们满意的模型和参数
- 用测试集去评估步骤3选出的模型,看它在未见过的数据上的性能
但是,holdout交叉验证有个缺点是:样本不同的训练集和交叉验证集会产生不同的性能评估。下面,让我们介绍k-fold交叉验证来解决这个问题。
k-fold交叉验证
在holdout交叉验证中,我们把训练集拆分成训练集和交叉验证集。在k-fold交叉验证中,我们把训练集拆分成k份,k-1份用作训练,1份用作测试。然后,我们把这k份中的每份都用来测试剩下的份用作训练,因此,我们会得到k个模型和性能的评估,最后求出性能的平均值。下面,我假设k=10,看下图:
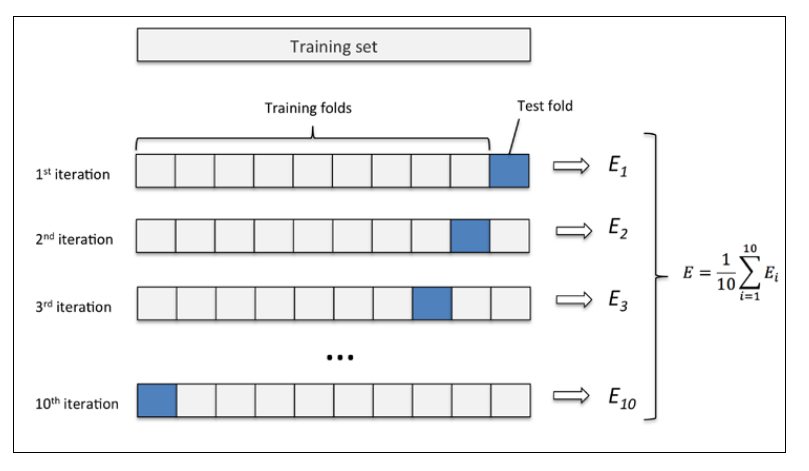
上图中,我把训练集分成10份,在10次迭代中,9份被用作训练,1份被用作测试,最后我们求出平均性能。注意:在每次迭代中,我们并没有重新划分训练集,我们只是最初分成10份,接着在每次迭代中,用这10份中的每一份做测试剩下的9份用作训练。
对于大多数的应用k=10是个合理的选择。然而,如果我们的训练集相对较小,我们可以增加k值,因此,在每次迭代中我们将有更多的训练集来拟合模型,结果是我们对泛化的性能有更低地偏差。另一方面,如果我们有更大地数据集,我们可以选择一个更小地值k,即使k值变小了,我们依然可以得到一个对模型性能的准确评估,与此同时,我们还减少了重新拟合模型的计算代价。
在scikit-learn的实现中,它对我们的k-fold交叉验证做了一个小小的改进,它在每个份的训练集中都有相同的类别比例,请看如下代码:
from sklearn.cross_validation import StratifiedKFold
import numpy as np
scores = []
kfold = StratifiedKFold(y=y_train, n_folds=10, random_state=1) # n_folds参数设置为10份
for train_index, test_index in kfold:
pipe_lr.fit(X_train[train_index], y_train[train_index])
score = pipe_lr.score(X_train[test_index], y_train[test_index])
scores.append(score)
print('类别分布: %s, 准确度: %.3f' % (np.bincount(y_train[train_index]), score))
np.mean(scores) # 求出评估的平均值,0.94956521739130439
# 输出如下:
类别分布: [257 153], 准确度: 0.891
类别分布: [257 153], 准确度: 0.978
类别分布: [257 153], 准确度: 0.978
类别分布: [257 153], 准确度: 0.913
类别分布: [257 153], 准确度: 0.935
类别分布: [257 153], 准确度: 0.978
类别分布: [257 153], 准确度: 0.933
类别分布: [257 153], 准确度: 0.956
类别分布: [257 153], 准确度: 0.978
类别分布: [257 153], 准确度: 0.956上面,我们自己写for循环去拟合每个训练集。scikit-learn有一种更有效地方式帮我们实现了上述的方法:
from sklearn.cross_validation import cross_val_score
scores = cross_val_score(estimator=pipe_lr, X=X_train, y=y_train, cv=10, n_jobs=1)
print(scores)
# 输出如下:
[ 0.89130435 0.97826087 0.97826087 0.91304348 0.93478261  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7138
7138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









