







本总结是是个人为防止遗忘而作,不得转载和商用。
说明:前置知识是朴素贝叶斯,这个我以总结,地址是:
http://blog.csdn.net/xueyingxue001/article/details/50680908
复习:一个贝叶斯的例子
啊,上去就说例子?
是啊,这个是再次总结,前置知识看我的上一篇总结,这里不再赘述。
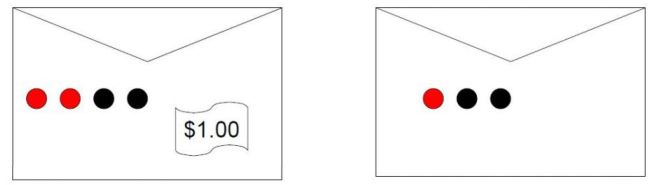
背景:如上图所示,现在你面前有两个信封,一个信封里有1美元,另一个没有,然后有1美元的信封里有红黑球各两个,没有1美元的信封里有1个红球2个黑球。目标是找到有1美元的信封。
规则:在决定选哪个信封前允许你从信封里拿一个球看看颜色。
问:如果拿到的是黑球,则该信封里有1美元的概率是多少?如果是红球,又是多少?
解:
为了方便,用c1、c2表示左右两个信封。用P(R)、P(B)表示摸到红球、黑球的概率。
由题目可以知道:
P(c1)= P(c2) = 1/2
P(R|c1)= P(B|c1) = 2/4
P(R|c2)= 1/3
P(B|c2)= 2/3
于是根据全概率公式有:
P(R)= P(R|c1)*P(c1) + P(R|c2)*P(c2)
根据贝叶斯公式有:
P(c1|R)= ( P(R|c1)*P(c1) )/P(R)
这样就求出了P(c1|R),同理可以求出P(c1|B) ,P(c2|R),P(c2|B)。
朴素贝叶斯
朴素贝叶斯的假设
1,一个特征出现的概率,与其他特征(条件)独立(特征独立性)。或者说:对于给定分类的条件下,特征独立。
2,每个特征同等重要(特征均衡性)。
| PS: 这两个假定其实是不正确的,因为在实践中基本无法满足这两个假定,比如:一篇文章中有个词是“机器学习”,那很有可能会出现“数据挖掘”,于是这两个词就不是特征独立。再比如:一篇文章中有两个组词:“今天是X月X号”和“恭喜你中了500W”,那这两组词就不是同等重要的。 所以,玩机器学习千万不能较真,你较真毛事都干不成! |
以文本分类为例
样本:10000封邮件,每个邮件被标记为垃圾邮件或者非垃圾邮件。
分类目标:给定第10001封邮件,确定它是垃圾邮件还是非垃圾邮件。
方法:朴素贝叶斯
解:
1,用c1表示垃圾邮件,c2表示非垃圾邮件。
2,建立词汇表(人工的话就是找一本辞海,然后把所有的单词抄到一个列表/向量里),记单词的数目为N。
3,将每个邮件m映射成维度为N的向量x,若单词wi 在邮件m中出现过,则xi =1,否则,xi =0。即邮件的向量化:m -> (x1 ,x2……xN)。
这步的意思是:之前已经把所有的单词统计了出来,这样就形成了一个长度为N的列表,列表中的每个元素就是一个单词,于是每封邮件都可以初始化一个长度为N元素全0的列表。而这一步就是统计该邮件中哪些单词用到了,若第i个单词在邮件中出现,就把该邮件的列表的第i个元素设为1,反之不改变。
4,使用贝叶斯公式
P(c1| x) = ( P(x | c1) * P(c1) ) / P(x)
P(c2| x) = ( P(x | c2) * P(c2) ) / P(x)
注意:这里的x是向量(x1 ,x2 ……xN)。
5,剩下的就是计算了,即:只要我们可以计算出P(x | c1)、P(c1)、P(x)就算出P(c1| x)了。(P(c2| x)同理)
5.1,p(c1):因为样本已经给出来了,我们知道哪些是不是垃圾邮件,若样本中有3000封垃圾邮件,则p(c1) = 3/10。
5.2,P(x | c1):根据朴素贝叶斯的“特征条件独立假设”,有:P(x|c1) = P(x1,x2 …xN |c1) = P(x1 | c1)* P(x2 | c1) … P(xN | c1)。
而P(x1 | c1)是所有垃圾邮件里(假设有3000封),单词x1出现的概率。于是方法就是:统计这3000封邮件一共有多少个词,以及这3000封右键中x1出现了多少次,进而求出P(x1 | c1)。其他同理。
5.3,根据朴素贝叶斯的“特征独立假设”,有:P(x)=P(x1 ,x2…xN )=P(x1)*P(x2)…P(xN)。
而p(x1)表示在10000封邮件中x1出现了多少次,其他同理。
6,将第5步的结果代入第4步就可以求出来了。
| PS1: 如果仅仅是区分垃圾邮件,则不需要算p(x),因为对于公式: P(c1 | x) = ( P(x | c1) * P(c1) ) / P(x) P(c2 | x) = ( P(x | c2) * P(c2) ) / P(x) 两个的p(x) 是一样的,既然是一样的那对于区分一个邮件是否是垃圾邮件就没有帮助了。 PS2,两个极端情况: 1,很多次出现的次数都很小,这样的话P(x)因为是那么多很小的数相乘,则早就溢出了。这时候使用对P(x)取对数的方法解决,比如10-18,这个数放计算机早溢出了,但取了对数后是ln10-18=-18,就不可能溢出了。 2,如果某个词没出现的话,那p(xi)就是0了,解决方法是拉普拉斯平滑。 |
拉普拉斯平滑
下面出现的符号还是以上面垃圾邮件的例子为准。
p(x1| c1)是指的:在垃圾邮件c1 这个类别中,单词x1出现的概率。(x1 是待考察的邮件中的某个单词)
定义符号:
n1 :在所有垃圾邮件中单词x1 出现的次数。如果x1 没有出现过,则n1 = 0。
n:属于c1 类的所有文档的出现过的单词总数目。
得到公式
p(x1|c1)= n1 / n
而拉普拉斯平滑就是将上式修改为:
p(x1|c1)= (n1 + 1) / (n + N)
p(x2|c1)= (n2 + 1) / (n + N)
......
其中,N是所有单词的数目。修正分母是为了保证概率和为1。
举个例子:中国男足vs韩国男足的前5场的比分是0:5,那预测第六场中国队胜出的概率是多少时难道给0/5,这绝壁不行。所以分子分母都加1,变成1/6。
贝叶斯网络
在“朴素贝叶斯的假设”中说了,实际应用中很难遇到满足这两个假设的情况的,然后也说了不能较真,不过如果硬是较真的话....那也不是没办法,因为我们可以对其做一下改进,而改进就是贝叶斯网络。
把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。
贝叶斯网络(Bayesian Network),又称有向无环图模型(directedacyclic graphical model ,DAG),是一种概率图模型,根据概率图的拓扑结构,考察一组随机变量{X 1 ,X 2 ...X n }及其n组条件概率分布(ConditionalProbability Distributions, CPD)的性质。
一个简单的贝叶斯网络
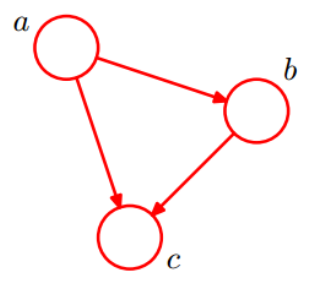
p(a,b, c) = p(c|a, b)p(b|a)p(a)
| PS:如果把a, b, c规定成条件独立,那相当于把上面图的边去掉,这就变成朴素贝叶斯建立的图了。 |
全连接贝叶斯网络
即,每一对结点之间都有边连接
一个“正常”的贝叶斯网络

如上图所示,直观上:x1和x2独立;x6和x7在x4给定的条件下独立
于是x1,x2,…x7的联合分布就是:
p(x1)p(x2) p(x3)p(x4|x1, x2, x3)p(x5|x1, x3)p(x6|x4)p(x7|x4, x5)
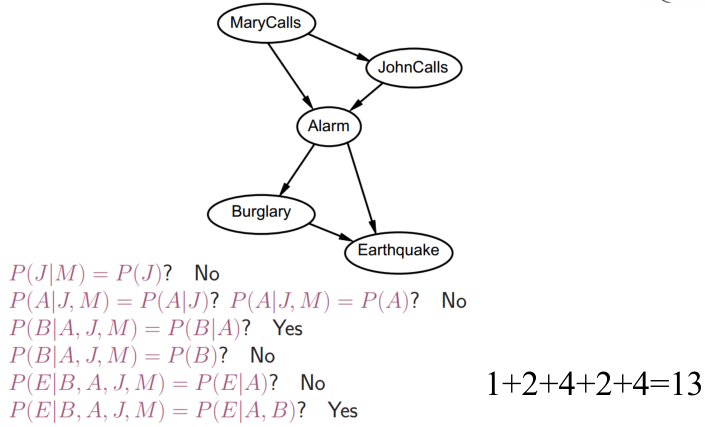
贝叶斯网络:警报
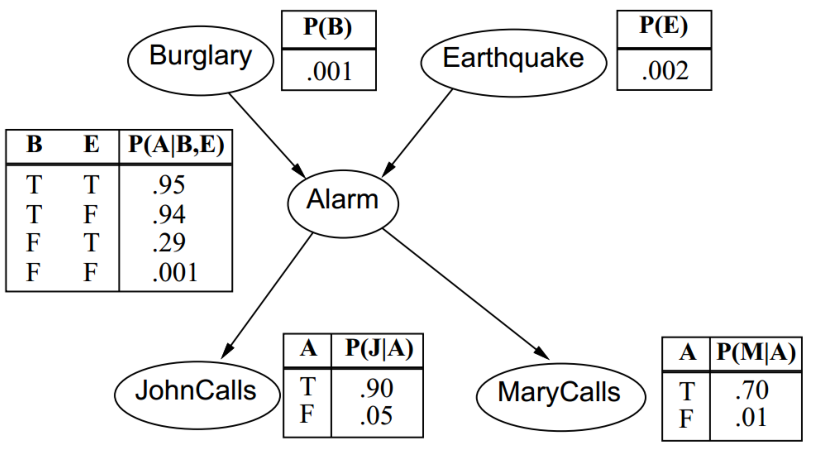
如上图所示,Burglay和Earthquake发生时会响警报Alarm,警报响时John和Mary可能会打电话通知你,图里面的数是概率,如:.001就是0.001。
于是根据之前得到的结果,即全部随机变量的联合分布:
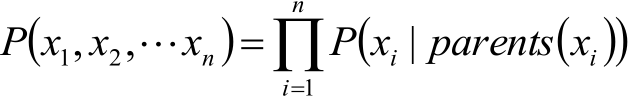
就可以求下面这个联合概率:
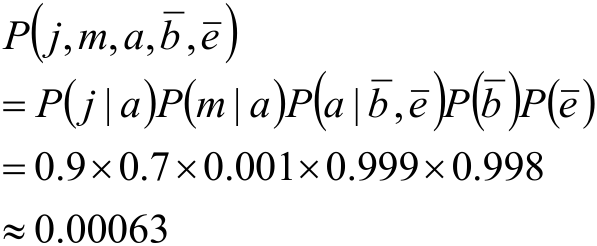
需要多少参数才能确定贝叶斯网络
结点的parent数目是M,结点和parent的可取值数目都是K时,每个结点所需参数的个数为:KM *(K-1)
特殊的贝叶斯网络 -- 马尔科夫网络
就是形如下面这样的网络:

即:当前结点至于上一个结点有关系。
D-separation(通过贝叶斯网络判定条件独立)
在c给定的条件下,a和b是独立的三种情况。
第一种:
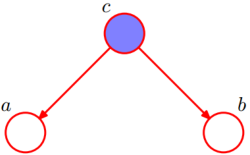
如上图所示,这种称作tail-to-tail。
首先根据图模型,得:p(a,b,c) = p(c) * p(a|c) * p(b|c)
所以:p(a, b, c)/p(c) = p(a|c) * p(b|c)
因为:p(a, b| c) = p(a, b, c)/p(c)
所以:p(a, b| c) = p(a|c) * p(b|c)
第二种:

如上图所示,这种称作head-to-tail
公式是:p(a, b|c) = p(a|c) * p(b|c)
第三种:
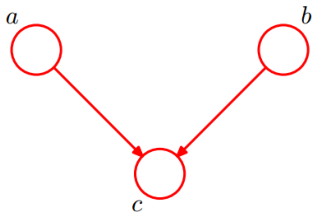
如上图所示,这种称作head-to-head
公式是:p(a, b) = p(a) * p(b)
例子:
第一种:
c:抽烟;a:肺癌;b:支气管炎。
于是第一种图就表示:抽烟可引起肺癌,也可能引起支气管炎。
因此如果一个人去检查结果是支气管炎,而医生在不知道其是否抽烟或者可以确定其抽烟的情况下会建议其检查下是否患有肺癌(因为不能排除其抽烟的可能性啊),但是如果可以确定这个人没有抽烟(c确定了),那就不用在检查是否有肺癌了。
第二种:
a:去过亚洲;b:照X光片有阴影;c:得肺结咳;
于是如果一个人去过亚洲(如北京) -> 那他的肺结咳的概率会高 -> 如果得了那照X光片就会有阴影。而如果一个人得了肺结核(c确定了),那去没去亚洲和照X光片有没有阴影就没关系了(或者说就不用在关心他是否去过亚洲了,为啥?赶紧治病啊!你关心曾经还有个毛用!)。
贝叶斯网络的构建
一句话描述的话就是:依次计算每个变量的D-separation的局部测试结果,
综合每个结点得到贝叶斯网络。
一步步描述的话就是:
1,分析每个特征,给一个看起来比较合理的顺序:x1, x2, ..., xn。
2,对于i=1到n:
2.1在网络中添加xi结点
2.2在x1,x2, ..., xn中选择xi的父母,使得:
p(xi|parent(xi))= p(xi|x1,x2,...,xi-1)
如:
看看x1和x2是否独立,即p(x1,x2) =p(x1)p(x2),如果独立则这两者之间就不能有连线,判断好后将x1和x2打成一个包
看看x3和x1,x2是否独立,即:p(x3,x1,x2)=p(x3)p(x1,x2),独立同理;不独立看看能不能退而求其次,如:p(x3,x1,x2) =p(x3|x2)p(x1)p(x2),如果这种成立,那x3和x1之间就不能有边
这种构造方法,显然保证了全局的语义要求:
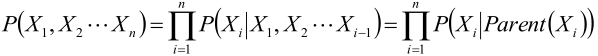
但时间复杂度很高就是了。。。。
例子
第一步:
选取两个结点,看看这两个独立不,即p(J|M) = P(J) ?
结果是不独立,于是画上边
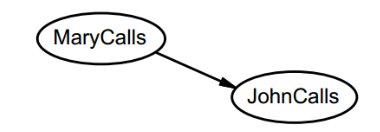
第二步:
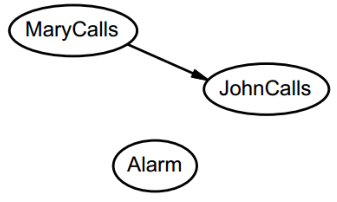
添加结点,看看与新节点是否独立,即:
P(A|J,M)= P(A|J)?
P(A|J,M)= P(A)?
结果都不独立,然后画出了下图:
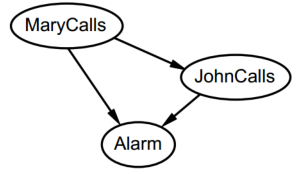
就这样不停的添加结点,最终结果就是:














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









